
The LLM Convergence Threshold Has Shifted. It’s Time for New Benchmarks
Is agentic engineering outpacing its own analysis?

Throughout 2025, one narrative dominated AI coding discussions: open-source models finally caught up. Will 2026 be the year of even closer convergence? Or is something different in the works?
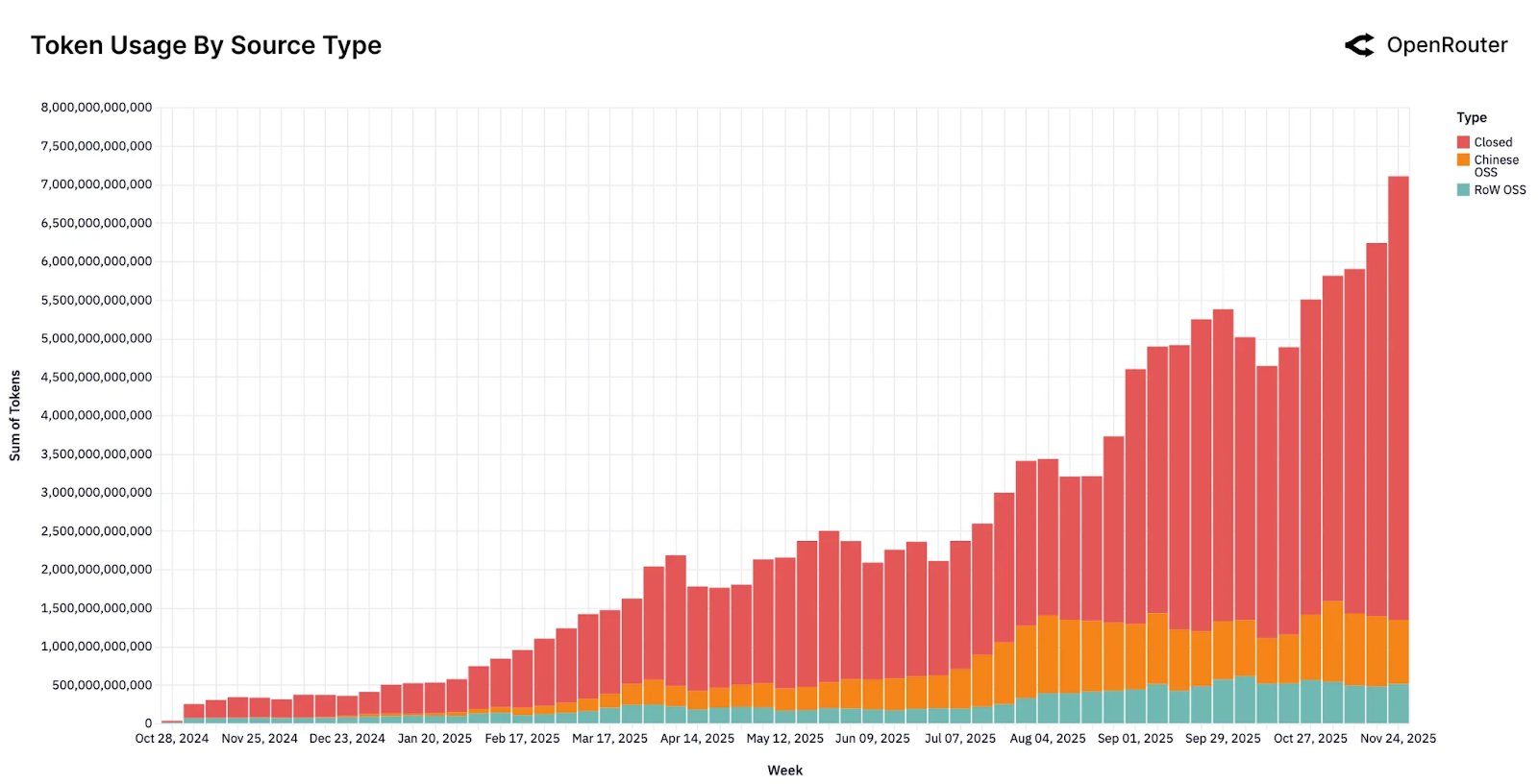
Recent reports from OpenRouter and Understanding AI documented a massive surge in open-source (OSS) model usage across tasks and workflows, and this was even more of a shift for AI coding.
OSS models moved from fringe to around one third of overall usage across closed and open models combined
Programming queries jumped from 11% to over 50% of total AI usage this year
But that broad convergence belies a deeper evolution in model capabilities: the big labs are moving in even bigger leaps with each release. And the convergence is also reshaping how engineering teams should think about model choice in 2026.
WIRED magazine has been busy declaring that Meta’s open-weight Llama models are dead in the water, and that Alibaba’s Qwen will soon overtake OpenAI’s GPT models. But that seems like just how things happened to feel for a moment earlier this week.
At Kilo we’re always looking at what’s next. Our goal is not just to help developers take advantage of the latest models, but to help them unlock the ability to truly move at Kilo Speed.
And to do that, we need new ways of thinking about, tracking, and analyzing agentic engineering.
When you cross a threshold, it’s not about looking back. Instead we should be focused on the next threshold — and the new benchmarks needed to keep agentic coding progressing at an exponential pace.
OSS Performance: The Rise Is Real
The gap between proprietary and open-source models is closing faster than anticipated, signaling a new era of accessibility for high-performance AI. Recent benchmarks confirm that open-weight systems are now capable of matching, and occasionally outperforming, closed models in complex reasoning and coding tasks.
This convergence proves that state-of-the-art capabilities are becoming democratized, fundamentally altering the economics of intelligent application development. Open-source models aren’t just popular — in many respects they’re competent enough to replace closed models for typical coding workflows:
MiniMax M2 showed that a 10B-parameter model with efficient reasoning can handle real application tasks (Flask API creation, bug detection, docs) in seconds vs. minutes for larger models.
Z AI’s new GLM 4.7 model significantly improved mathematical and reasoning skills, achieving 42.8% on the HLE (“Human Last Exam”) benchmark—a significant increase over GLM-4.6 and surpassing OpenAI’s GPT-5.1.
MiniMax M2.1 improves on M2 with strong scoring on SWE-bench Verified (74.0) and VIBE-Web (91.5), edging out other open models and even competing with closed systems in some tasks.
It’s not just about low cost and open weights, it’s about handling complex tasks efficiently and effectively, and doing so in a cost-effective way. Open models now often perform competitively on strong industry benchmarks at a fraction of cost and latency. For example, when it was released back in September (an eon ago in AI years…), GLM-4.6, the previous Z AI model, got a lot of buzz for matching benchmark performance of Anthropic and OpenAI models on key benchmarks like AIME 25. But that was just the tip of the iceberg. GLM-4.6 demonstrated a 48.6% win rate against Claude Sonnet 4 in real-world coding tasks, and when we did the cost analysis we found a stunning 50-100x cost difference.
For many day-to-day tasks — scaffolding code, fixing bugs, boilerplate generation — OSS models are now viable first choices in production workflows.

Benchmarking how different models perform in different agentic developer modes in Kilo has given us direct visibility into this shift: OSS models from labs like MiniMax and Z AI are now high contenders in every category, and Grok Code Fast 1, which is free in Kilo, remain stronger than ever. (xAI typically releases weights for earlier versions of models; Code Fast isn’t open but the original Grok-1, a 314 billion parameter model, is open source under the Apache 2.0 license.)
And unlike earlier this year where there was a lot of fast switching, a trend is emerging that users will continue to rely on a particular model for a particular type of task, then add on other models in other modes like layers on a cake.
Yet State-of-the-Art Models Are Still Making Big Leaps
The convergence story holds only if you focus on average performance. When you look at frontier launches, a different trend emerges. And it’s a big one.
Claude, GPT and Major Frontier Progress
We’ve been running a lot of head-to-head evaluations of models this year (and will be leaning into this even more in 2026!). One that keeps getting coverage is our analysis of GPT-5.1, Gemini 3.0, and Claude Opus 4.5. In a deep dive, we put these high-performance models to work on real coding tasks, benchmarking them against each other.
The results were intense:
Claude Opus 4.5 scored 98.7% average across architecture, refactor, and extension tests in ~7 minutes total — the highest overall completeness and thoroughness on requirements.
GPT-5.1 produced resilient, well-documented, backward-compatible code.
Gemini 3.0 delivered minimal, prompt-literal output at lower cost but missed deeper architectural requirements.
These differences aren’t trivial: they reflect choices in model reasoning depth, completion quality, and interpretation style — all of which affect production code correctness, not just bench scores.
Anthropic has become the standard-bearer for coding models. But that’s making everybody stronger as a result.
What this signals for the future is that model choice will become more subtle but also more essential–almost a necessity–for deeper development workflows, especially as everybody from startups to huge enterprises are building out deeper agentic flows that cover everything from planning and architecture, to development, code review, security review and refinement.
Gemini 3 Flash — Frontier Innovation at Scale (or Google vs Google)
Google’s latest Gemini 3 Flash exemplifies how frontier models are expanding the capability frontier. Looking at Gemini models compared against each other, we found that Gemini 3 Flash:
Scored 90% across three real coding tests,
6x cheaper and 3x faster than Gemini 3 Pro
Yet still trailed the highest-performers (such as the latest Opus model) in implementation completeness
This leap is noteworthy because it combines speed, cost efficiency, and quality improvements — something OSS models haven’t matched at the same scale.
Google is a player to watch from all sides. In addition to their heads-down approach to LLM development, they have humungous waves of user data to train the models on, across a tremendous range of use cases. Who isn’t using a Google product in their day-to-day life, let alone just at work?
The New Threshold: Specialization Over General Convergence…and the Love of Evals
OSS models closed the gap to earlier SOTA models on average performance, but frontier models continue to push the capability frontier — especially on deeper reasoning, architectural tasks, and completeness.
But what does SOTA event mean any more when so many models are State of the Art?
Our prediction: 2026 will be the year of specialization and hybrid model strategies – both across different providers and within a labs’ portfolio (like optimizing use of both Sonnet and Opus in a particular high-speed environment.) This might just be the year of deep adoption.
As Stanford AI experts put it in their predictions for 2026, it’s about moving from AI evangelism to AI evaluation:
The era of AI evangelism is giving way to an era of AI evaluation. Whether it’s standardized benchmarks for legal reasoning, real-time dashboards tracking labor displacement, or clinical frameworks for vetting the flood of medical AI startups, the coming year demands rigor over hype. The question is no longer “Can AI do this?” but “How well, at what cost, and for whom?”
In this new world of applied AI, evals are king.
The next frontier is bigger than we can even imagine, and there are exciting new players like Martian and CoreThink doing wild stuff with model mapping, routing, injection and interpretability.
Which means that we’ll ultimately need not only new benchmarks, but also new ways of testing them.
Watch this space 🙂
And happy new year from all of us at Kilo Code!