
Inside Kilo Speed: The Engineer Who Teaches Teams How to Think in Agents
How to manage your agent team, from someone who coaches Kilo customers in agentic engineering.

When you’re learning a new discipline—especially on the job—learning the theory behind it can feel like an abstract nice-to-have, while practice is the thing that’s actually useful. Learning by doing is absolutely a valid way to upskill, but in Marius Wichtner’s experience, grasping the conceptual foundation of agentic engineering helps to make the practical steps make sense.
Before joining Kilo Code, Marius was already training engineering teams on working with generative AI. At Kilo, he does the same for enterprise clients in Kilo Speedruns: one-hour sessions designed to give teams a fast, practical orientation on agentic software development. He’s run them for companies across industries, and now he’s sharing the foundations of those lessons (and his specific practices for each) here:
How to delegate effectively
How to scale across concurrent workstreams
How to maintain judgment and recover when things go wrong
1. How to Delegate: The Team Lead Model and the Plan
The mental model Marius uses to explain agentic engineering—both in client speedruns and in how he structures his own work—is the team lead.
Team leads don’t spend all day writing code, and the same was true even before agentic tools existed. They were in pairing sessions, answering questions, reviewing output, and deciding what to merge. “Those were always the people that were only in meetings and they got called by all the juniors,” Marius says. “They were just solving the last 20% of the problem.”
In this model, the agent takes care of execution work, while the engineer operates as the team lead. The 80% that agents handle well—code generation, boilerplate, well-scoped subtasks—is work that the team lead delegates. The 20% that still requires the engineer is the judgment work: architectural decisions, what to merge, and recognizing when the agent has drifted.
The engineers who transition most naturally into agentic workflows are often the ones who were already operating this way: team leads and architects who had developed the habit of switching contexts and reviewing output rather than writing it. Everyone else has to learn that mode of working, which starts with understanding the difference between a specification and a plan.
A specification captures what the user wants. It doesn’t change based on the current state of the codebase. It’s set from the user demand, and it stays set. A plan is how you intend to build the thing given where the code actually is right now. “A plan is dependent on your state of the code,” says Marius. “Plans usually get thrown away very quickly.”
When Marius works with an agent on complex tasks (especially those with important architecture decisions), he asks it to write its plan to a markdown file before it starts executing so he can review it. Asking the agent to write its plan first forces a shared understanding of what’s actually being built. You review it, ask questions, and surface problems before execution begins. It’s the refinement stage of traditional software engineering, but the difference now is that the feedback loop is much faster.
Plans, done right, function as constraints. Marius thinks of this as keeping an agent in the acceptable solution space: the set of outputs you will actually accept. The further an agent drifts from a confirmed plan, the more likely it ends up somewhere that requires starting over. Forcing the plan upfront dramatically increases the probability of staying on track.
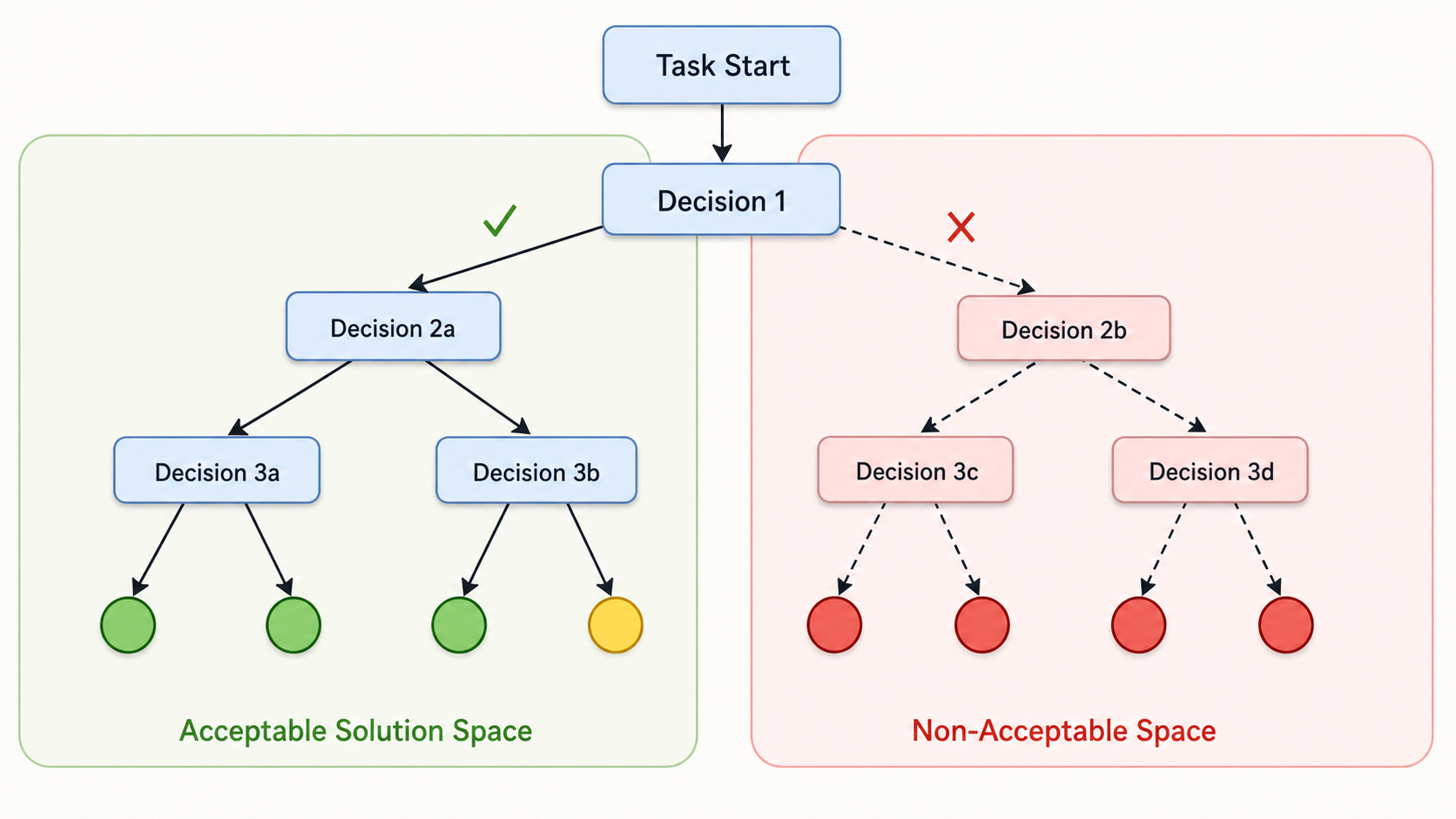
The plan also acts as a contract: it documents the approach the agent intends to take, so when it does something unexpected later, there’s a reference point. “You can always reiterate to the agent, ‘We decided to implement this plan. Why have you decided otherwise?’”
2. How to Scale: Parallelism and the Context Rot Problem
Even with a solid plan in place, there’s a natural limit to how far a single agent session can take you: context rot. As a session grows, accumulating conversation history, prior decisions, and intermediate code states, the agent starts losing coherence. Tasks that were reasonable at the start become unpredictable midway through. Early decisions can come back to bite you. At some point, recovery means starting over.
Most engineers treat this as a nuisance and work around it by brute force: shorter sessions, more restarts. Marius treats it as a signal that the work hasn’t been decomposed correctly. “If you have a huge feature and you develop on it for the whole week, you will keep having context rot,” Marius says. “It makes much more sense to plan out what you want to implement ahead of time and then develop each of the sub-problems individually in small context windows.”
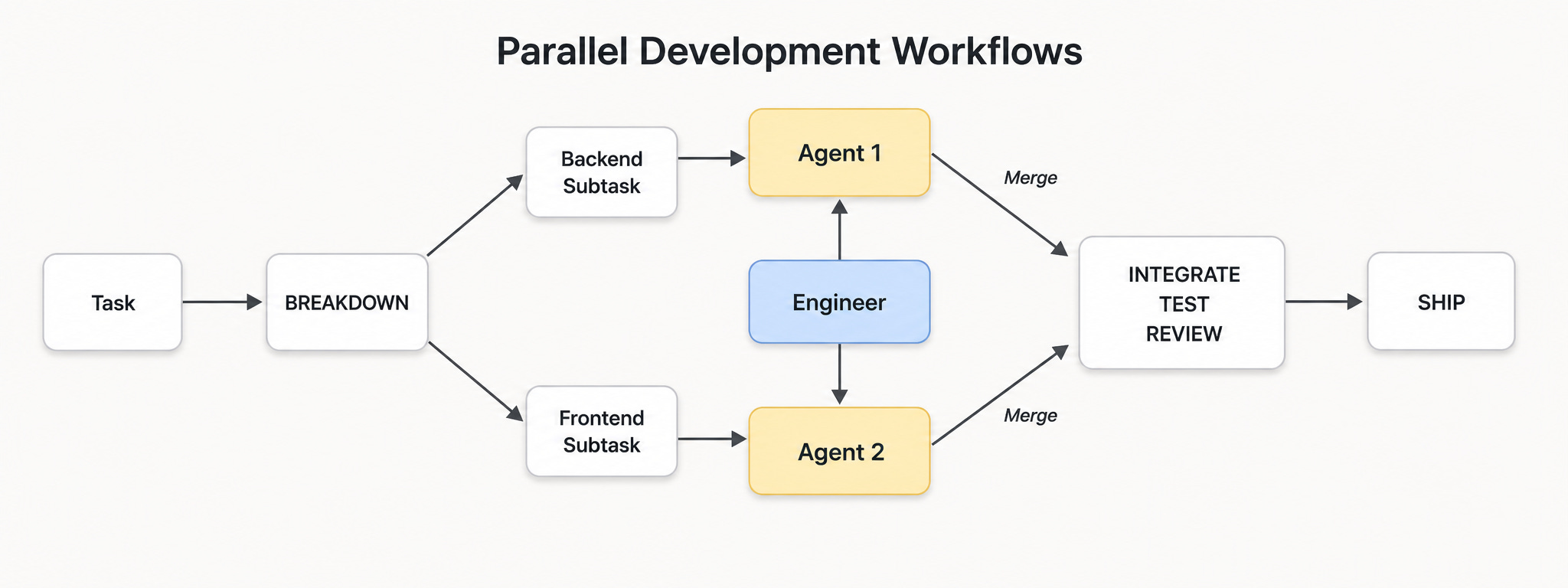
This is where parallelism comes in: you run multiple agents simultaneously, each working on a specific sub-problem. But parallel agents writing to the same file system will conflict (the same reason Git was invented). You need each agent working in its own isolated environment.
To address this, Marius built a solution into his own custom IDE, before building Kilo’s Agent Manager: a tool for running multiple agent sessions simultaneously, each in its own isolated workspace, with its own file system. Instead of supervising agents one at a time, an engineer can delegate across several concurrent workstreams and review the results as they come in. Things that look good get merged; things that don’t get discarded without the cost of untangling a week of compounded decisions.
Not every task demands the multi-agent treatment. Marius works across three categories depending on complexity:
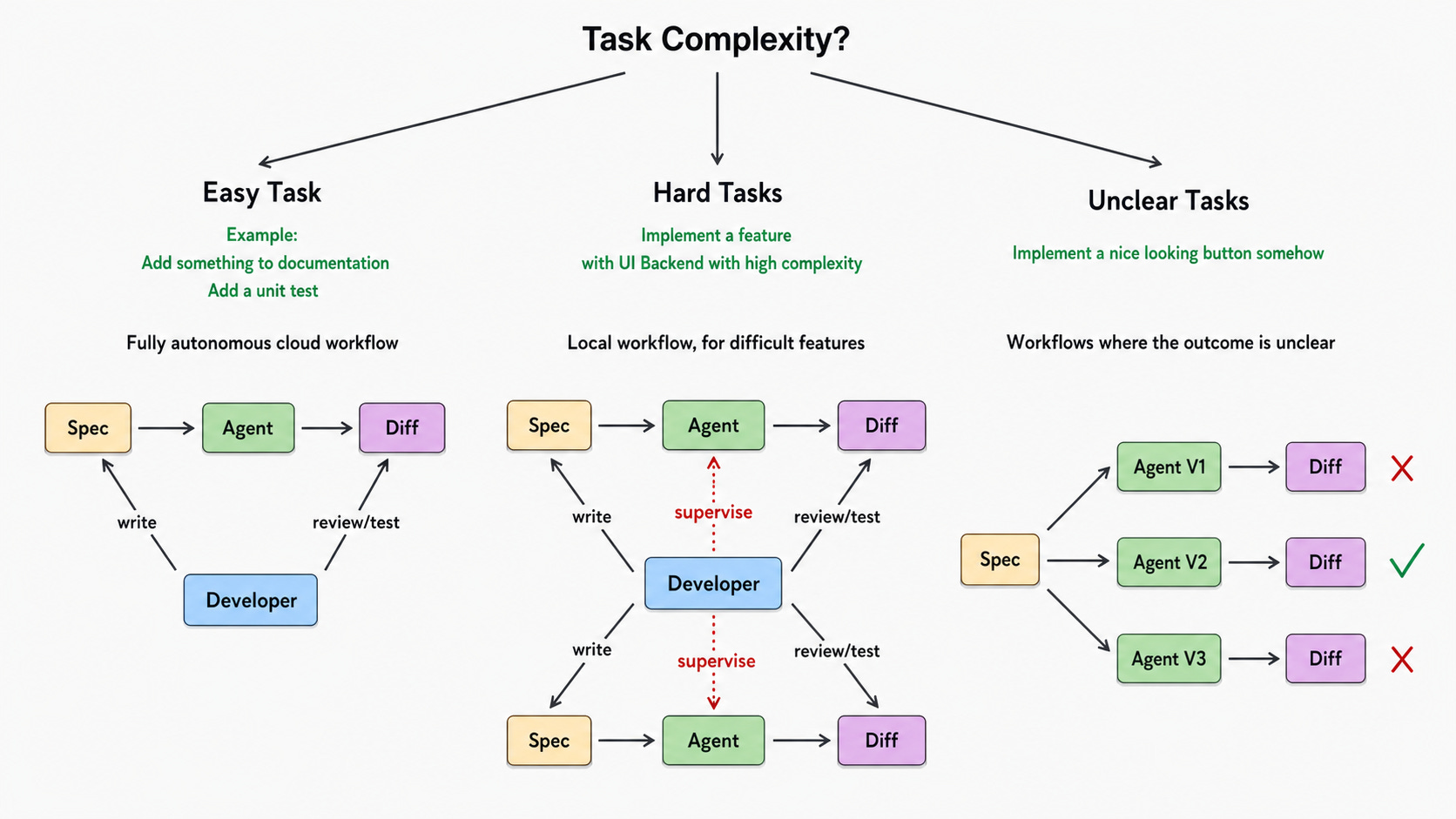
Easy tasks: Things like adding documentation, writing a unit test, or well-scoped bug fixes go to a fully autonomous cloud workflow. The developer writes the spec, the agent executes, the developer reviews the diff. No supervision is required mid-session.
Hard tasks: Implementing a complex feature spanning UI and backend, or anything with meaningful architectural decisions, gets handled locally with Agent Manager. The developer supervises multiple agents working in parallel on decomposed subtasks, stays close to the work, and makes the judgment calls as diffs come in.
Unclear tasks: When the outcome isn’t well-defined, it’s hard to write a spec precise enough to constrain the agent toward a single solution. For these, Marius runs multiple agents in parallel against the same spec and compares the results. Instead of splitting work, the parallelism here is about generating variants and selecting the best one. The engineer’s job is choosing the right route.
3. How to Stay on Track: Context Engineering and Judgment
Context engineering, as Marius defines it, is how you structure and optimize the context of the agent. The goal is to limit an agent to doing exactly what you want, over time, in your codebase. It’s the ongoing work of keeping agents oriented, and knowing how to reorient them when they’ve drifted.
For upfront orientation, Marius uses Handy, a speech-to-text tool, to interact with agents verbally before locking in a plan. A lot of the context that matters for a task lives in the engineer’s head and never gets written down, because it’s too tedious to type everything out. Speaking it aloud removes that barrier, and an LLM can distil the rough transcript into a precise problem statement. The rough transcript also becomes the raw material for the plan the agent writes before executing.
When an agent session ends—whether it hit a context limit or simply reached a natural stopping point—continuing the work is usually straightforward. The original prompts, the Git diff (Agent Manager measures the delta from when the session started), and the current state of the codebase give a new agent enough to pick up where the previous one left off. Tools like Repomix can help with collecting specific file trees for this purpose. All of this can happen locally or in GitHub, where an issue describes the task, the PR contains the changes, and the history provides the thread. Most agents can continue from that context without much intervention.
What this process makes visible is what’s actually irreplaceable: the context that isn’t captured anywhere. Code and prompts are always an approximation—there are causal relationships in software that are hard to capture in prompts or code alone. Some of them, like another team’s architectural decision creating a dependency you didn’t know about, can be surfaced and handed off. Others only become visible when you run the code or at scale. An agent can’t know what hasn’t surfaced yet—that’s still the engineer’s job.
This is the difference between just coding and software engineering. The easy mistake with agentic work is treating it as a handoff: you describe what you want, the agent builds it, you ship it. In that approach, the critical last 20% can get lost: things like evaluating architectural choices and catching when an agent has veered off course. These require engineering judgment, and they’re often much harder than the first 80%.
The mental shift Marius describes is about learning to apply engineering judgment at the right moments, across multiple concurrent threads, rather than sequentially inside a single one.
Read the other posts in our Kilo Speed series:




