
Inside Kilo Speed: How Our Head of Data Shipped an Identity Resolution System Before His First Full Day
Can't trust AI with data tasks? Think again.

Identity resolution is one of the hardest problems in data engineering. Telemetry, backend, payment platforms, marketing forms—each of these systems contain their own representation of what a user is. Stitching those together requires not only a shared meaning of what represents a single identity, but also mapping edge cases, validating fragile joins and praying nothing silently breaks downstream. Get it wrong and you end up overcounting users for three years straight.
This is also the kind of problem where AI can do real damage. Unless the agent has deep context about how the data is produced, and what it means, the code might compile perfectly. CI turns green. But downstream, a KPI shifts by 5%, your Weekly Active Users (WAU) are suddenly inflated, or your accounting team might be looking at a revenue report that doesn’t match reality. Worse: you probably won’t find out until a stakeholder pings you three weeks later, leading to a multi-day forensic investigation.
When Pedro Heyerdahl joined Kilo as Head of Data, he embraced Kilo’s commitment to using AI for everything—even data workflows. By treating AI agents as a quality layer rather than just a code generator, Pedro was able to ship an Identity Resolution system before he even started his first full-time day.

From Solo Engineer to Agent Conductor
Before Kilo, Pedro was a senior data engineer. While his company encouraged building AI products for clients, internal AI usage for data workflows wasn’t incentivized.
“At Kilo, the biggest difference is that using AI for everything is the standard,” Pedro says. “You don’t plan as a single engineer; you plan as if you have multiple agent engineers under you.” At times, working this way makes Pedro feel more productive than when he had a whole team.
But for data work, leveraging AI is notoriously difficult. Unlike a software codebase where context is often contained within a few repositories, data context is fragmented across the stack. AI often struggles because data work requires horizontal intelligence across systems: not just code context from a single repo, but understanding of how data is produced, transformed, consumed, and what it semantically means. The limitations and risks of using AI for data work mean that many data professionals simply don’t entrust data tasks to AI.
While some caution is wise, Pedro has found ways to work at Kilo Speed, even in the fragmented world of data:
Pedro’s MVP: A 7-Tiered Identity Resolution
Pedro’s first major win—before he even joined the company full time—was an Identity Resolution system. At Kilo, every feature usage metric, every conversion event, and every revenue report depends on knowing that user A in telemetry is the same person as user B in the backend. “It’s the basis for getting everything else right,” Pedro says.
Instead of manually mapping every edge case, Pedro used an agentic workflow to develop a seven-tiered matching system. It checks for perfect ID matches first, then falls back to email hashes, session tokens, and other identifiers to ensure a consistent view of the user.
So how did he do it so quickly?
Breaking the Context Barrier: The Memory Bank
Managing context is often the key to effective agents, but it’s critical for humans too. When Pedro joined Kilo at the beginning of the year, he outsourced his onboarding to Kilo’s AGENTS.md feature (previously memory bank).
“I gathered transcripts from every relevant meeting and dumped them into a single folder,” Pedro explains. “I told the agent: ‘Here are the files, here are the repositories—build the memory bank.’”
By also giving the AI access to the backend application code—not just the dbt modeling layer—he taught the agents how data was being produced, not just how it was being stored.
“If I only show the AI the data logic, it can guess. But if I show it the production code that generates the telemetry, it understands exactly how to join different datasets,” Pedro notes. “That’s how we solved the problem of data stitching.”
These approaches allowed Pedro to go beyond asking for a SQL script, executing it himself, and then debugging errors. “I can just tell the agent, “Run the query with the dbt MCP and figure it out.’” Not only is the feedback loop much faster, the agent can also understand and explain data sources. “That was a big breakthrough,” says Pedro.
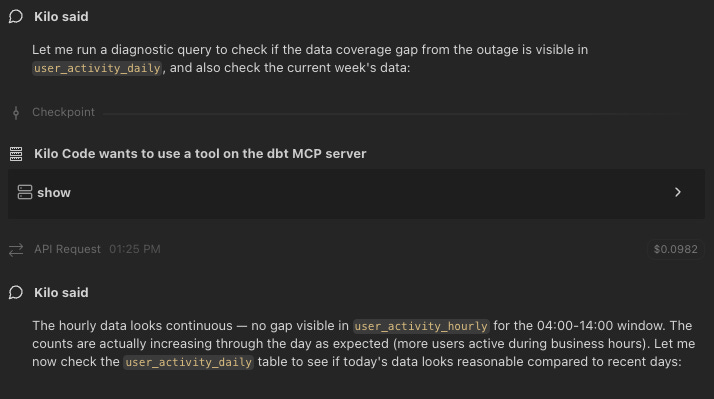
Building Data Impact into Code Reviews
One of the approaches that helped Pedro deliver the Identity Resolution system so quickly was leaning on the Kilo Review Agent to speed up code reviews and catch silent failures before they reach production.
As he noted in a recent LinkedIn post: “A clean diff does not mean a safe change. A green CI run does not mean correct metrics.”
But the Review Agent doesn’t just check for syntax; it checks for data impact. For data PRs, intent matters as much as code. Pedro writes PR descriptions that cover what changed, why, what could move downstream, and what to sanity check. He uses a pre-saved Kilo workflow to generate PR descriptions from the diff plus a PR template, so every PR starts with a consistent high-signal baseline.
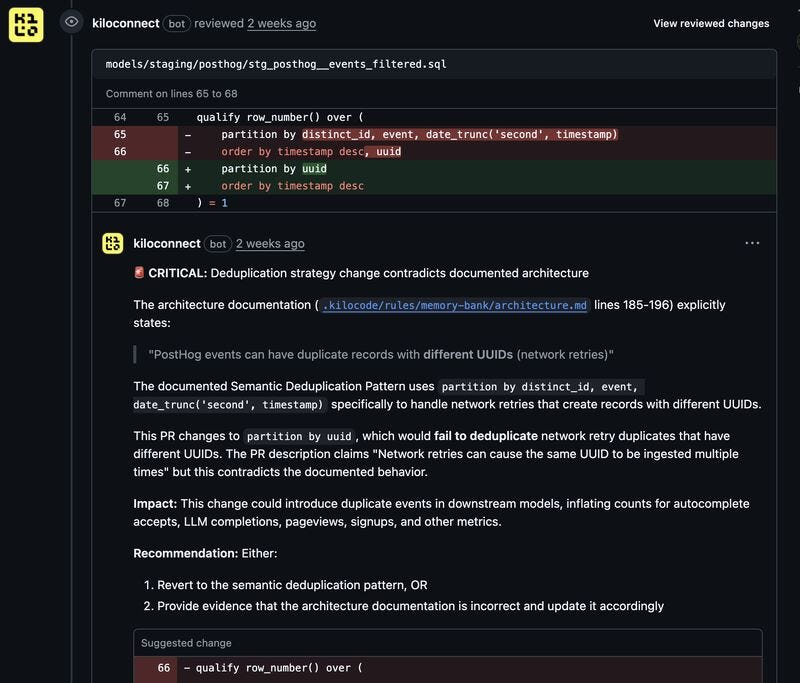
Pedro recalls a refactor where he was changing a deduplication strategy:
“The review pulled context from our memory-bank and flagged a contradiction: our system relies on semantic deduplication because network retries create duplicates with different IDs,” Pedro shared. “If I shipped that change, duplicate events would leak into usage models and inflate counts.”
By providing durable context, the agent acts as a senior peer reviewer who remembers every accounting rule and edge case ever discussed in a meeting transcript.
Since Pedro is a one-person team, automating reviews that assess data impact lets him move at Kilo Speed without sacrificing data integrity.
Another Win: Automating the Marketing “Ping”
As a data team of one, Pedro fields a lot of ad-hoc queries from marketing and sales. “Can you tell me which users used the CLI this week but haven’t touched the VS Code extension?”
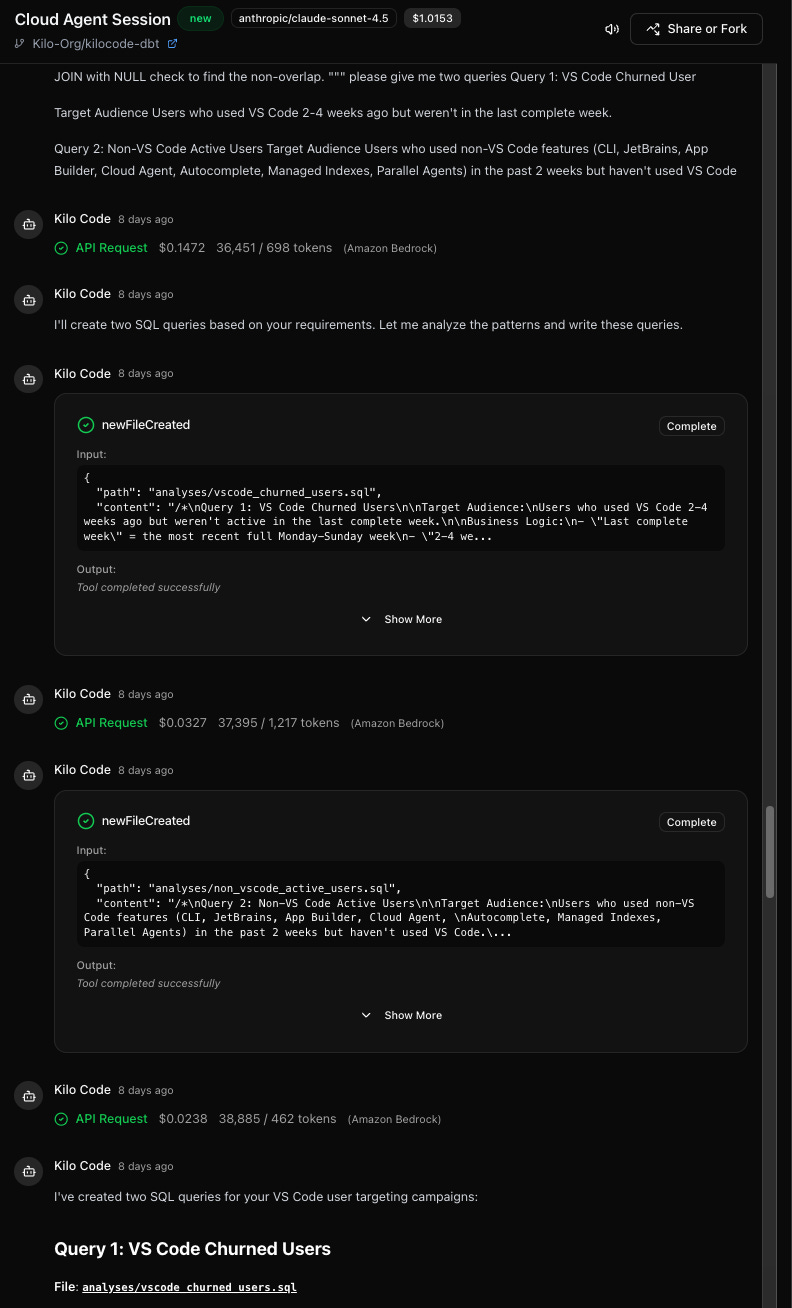
To solve this, Pedro built a Kilo Cloud Agent that marketing can message directly in Slack. “I spent two weeks collecting their most frequent questions and then gave those as one-shot SQL examples to a Cloud Agent,” Pedro says. “Now, the agent understands the table schemas and executes the queries itself. It’s not just giving them code; it’s giving them the data.”
Writing SQL faster only gets you so far. True Kilo Speed for data work is about building a system where agents handle the “silent” risks. “Agentic reviews only get ‘data smart’ if you give them durable context,” Pedro concludes. “Treat your memory-bank as the source of truth, write PR descriptions that explain the blast radius, and let the agents act as the quality layer you never had.”
Check out the other posts in this series:


