
DeepSeek V4: Rumors vs Reality for the Next Big Coding Model
Development and training are accelerating for everybody, not just DeepSeek

If you’ve been tracking the storm in subreddits lately, you know the vibe: DeepSeek V4 is currently the most anticipated drop since, well, DeepSeek R1.
(Or maybe Sonnet 5, which turned out to be Sonnet 4.6…)

The rumors are flying fast—some grounded in white papers, others fueled by “leaked” benchmark numbers of questionable origin. A supposed leak of DeepSeek V4 Lite this week focused on SVG code and found that the model could produce a detailed Xbox controller using 54 lines of code, while a separate multi-element scene was generated using 42 lines.
News outlets are even predicting that US stocks will fall in response to the big V4 release.
The reality is more balanced. At Kilo Code, we are already prepping our infrastructure to support V4 and its rumored Lite sibling, so we spent the weekend separating actual engineering signals from the marketing noise.
DeepSeek V3 Terminus has been popular in Kilo precisely because it’s predictable. Across the DeepSeek v3 family we see consistency in a variety of tasks, maybe without the best reasoning capabilities but with efficient processes overall and (for the time) strikingly effective tool use. It’s like a fisherman who goes out every day and reliably brings back a catch. Not a big catch, not the best catch, but it’s dinner.
Will V4 hold some sort of magical whale key? Why are we waiting so intently for it?
The Big Three Technical Truths
These are not just rumors; they are the architectural pillars we have seen in actual research and code commits.
Do they mean that the model itself will be astounding? Not necessarily. But they do highlight how fast our industry is evolving.
First Truth: Engram Architecture (Conditional Memory)
Verdict: TRUE
DeepSeek did not just leak this; they published the paper on arXiv in January. Engram is a “cyborg” approach that separates static memory (knowledge storage) from dynamic reasoning (GPU compute).
The Reality: By offloading boilerplate syntax and API knowledge to CPU RAM, the GPU is freed up for logic.
The Impact: Expect a 30% VRAM reduction for local dev. The model does not have to “think” about what a
forloop is; it just knows, leaving more brain power for your specific architectural challenges.
Second Truth: 1M+ Token Context Window
Verdict: TRUE
A larger context window and ability to carry it forward is a natural evolution of the DeepSeek Sparse Attention (DSA) paper.
The Reality: V3.2 already toyed with this, but V4 is built from the ground up to handle repo-level context.
The Impact: Forget chatting with a file. You will be chatting with the entire
node_modulesfolder if you are brave enough. DSA reportedly cuts long-context costs by 50%.
This is big, but it’s also in-line with recent releases from other labs like MiniMax’s M2.5, which supports parallelization (running multiple agentic workflows in parallel) and is tremendously good at caching.
Third Truth: Radical Cost Disruption
Verdict: LIKELY TRUE
DeepSeek’s entire brand is SOTA performance at a discount, so we can expect pricing to reflect that.
The Reality: Leaks suggest API pricing around $0.27 per 1M tokens. That is roughly 40x cheaper than some of the Pro/Opus tier models from US labs.
But at the same time, we’ve seen a remarkable rise in efficiency this year already, from new models like Trinity Large Preview, currently in free preview release from Arcee AI, as well as new versions of MiniMax and Claude Opus and Sonnet (more on this below).
A Crowded Field: The February Heat Wave
DeepSeek is not launching into a vacuum. The landscape has heated up significantly over the last two weeks with major releases from other frontier labs that are already setting a high bar for V4 to clear.
MiniMax M2.5 & GLM-5: Both launched earlier this month, effectively turning the “open weight” race into a sprint. MiniMax M2.5 has clocked in at an impressive 80.2% on SWE-Bench Verified, while Z AI’s GLM-5 is being hailed for its “agentic engineering” focus.
Kimi K2.5: Moonshot AI also recently dropped Kimi K2.5, introducing “Agent Swarm” technology. This allows the model to coordinate up to 100 sub-agents in parallel, reducing execution time for complex coding tasks by up to 4.5x. Already highly popular on OpenClaw / KiloClaw.
Gemini 3.1 Pro & Flash: Not to be outdone, Google’s mid-February update for Gemini 3.1 has been a sleeper hit. Gemini 3.1 Pro Preview is currently leading many intelligence indices with its “Deep Think” mode, and the Flash variant has become the gold standard for low-latency agentic loops.
The Plausible but Unverified Zone
83.7% SWE-Bench Verified
The claim is that V4 smokes Claude 4.5 and GPT-5.2 in fixing real GitHub issues. This has been all over the interwebs with various (probably made up) numbers, but.
The Reality: This number surfaced from a deleted Reddit post and a @bridgemindai tweet. While DeepSeek has a history of crushing benchmarks, we have not seen independent verification yet.
Catching Up to…the Past?: It’s worth noting that these “leaked” comparisons focus on versions of Claude and GPT that are already technically outdated. As of late February 2026, Claude Opus 4.6 and newer GPT Codex models have already hit the market (not to mention Sonnet 4.6, a huge leap forward for smaller models with big capabilities), pushing the SOTA bar even higher than the models DeepSeek was reportedly targeting in early testing.
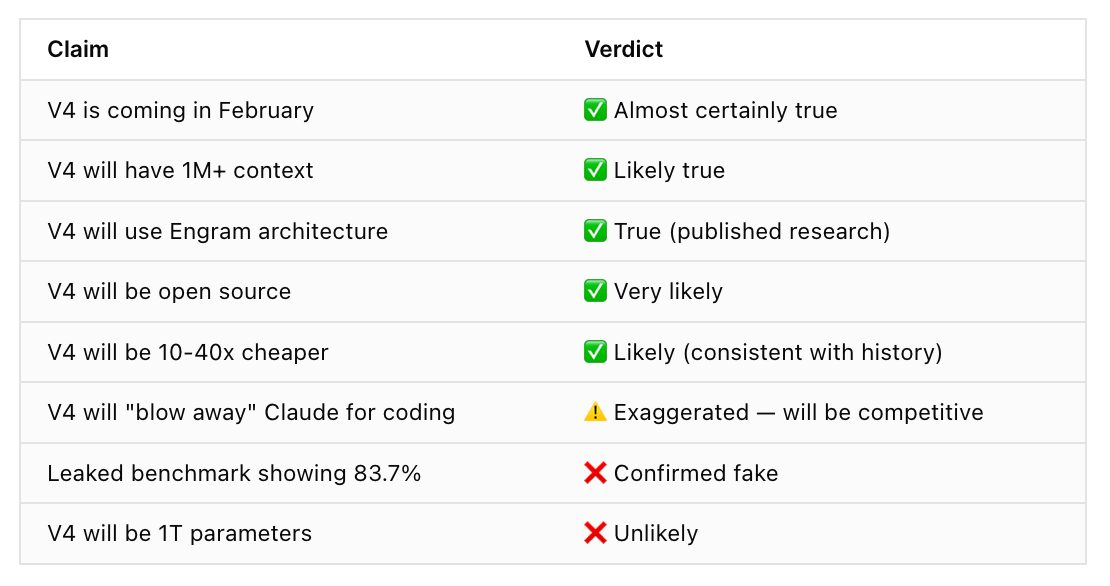
Summary: Rumor vs. Reality
A quick breakdown of the rumors we’ve explored so far. Doesn’t seem so out of step with other models…
What This Means for Agentic Workflows (Will It Claw?)
At Kilo Code, we are mostly excited about how Engram changes agents. Current agents get lost in the middle or go broke during long-running refactors.
The industry is moving at anything but a whale’s pace, and we’re here to make sure you can use the best new models the moment they go live — sometimes even sooner.
If V4 delivers on the Engram + DSA combo:
Multi-file Reasoning: The agent can see the relationship between everything—middleware, schemas, etc—without losing the thread.
Deterministic Debugging: With mHC (Manifold-constrained Hyper-connections), we expect fewer hallucinated fixes during deep reasoning traces.
Local Privacy: Running a SOTA-level coding agent entirely on-prem via dual 4090s or 5090s is the goal for enterprise security.
What excites us most at Kilo is how the new DeepSeek model seems primed to be a top model for the latest agentic technology, such as Cloud Agents and KiloClaw, our hosted version of OpenClaw.
So maybe the real question isn’t if the rumors are true, but something far more interesting:
WILL IT CLAW? 🦞
We’ll find out soon enough.