We predicted the $100k/yr-per-dev AI bill. Now the winners are routing around it.


Three of the largest IPOs in history are arriving in the same window. SpaceX went public on June 12 at a $1.77 trillion valuation, the biggest listing in history. Anthropic filed confidentially around $965 billion. OpenAI came in behind it at nearly $852 billion. Open any of the filings and you hit a word most of Wall Street didn’t know a year ago. SpaceX’s prospectus uses “token” 62 times.
Underneath all of the chatter around tokens is a single bet. These valuations assume two numbers keep climbing forever: how many tokens the world burns, and how much companies will pay for the best models to burn them. The first assumption looks safe. The second is already cracking, and it is cracking because of the most boring cost-control habit in enterprise software. The labs’ own best customers are learning to stop sending every job to the most expensive model that can handle it.
That habit has a name now. Model routing. It is the reason the people writing these checks should read the engineering org’s AI bill before they read the prospectus.
The subsidies ended
On June 1, GitHub flipped Copilot to usage-based billing for every plan. Everything agentic now burns credits at API rates. A line item that many engineering leaders treated as fixed for years became a number that sent costs sky-high, and the backlash was visible at the Gartner summit we visited recently.
On top of that, enterprises report blowing through their entire annual token budget in months. Uber blew through its entire 2026 AI coding budget in four months, by April, then capped employees at $1,500 a month. Uber was not even on Copilot. It was running Claude Code and Cursor. The point is that this is structural. Agentic workflows burn tokens faster than any flat per-seat budget could support, and when you tie yourself to one vendor, their next pricing change lands directly on you.

The obvious read is that AI got too expensive and the boom is cooling. The data says something else.
The 650x gap
Ramp publishes an AI Index built from real corporate spend. The latest cut, reported by TechCrunch, is the clearest picture yet of where this goes.
The top 1% of firms, the ones Ramp calls “AI-pilled,” spend about $7,500 per employee per month. That is $90,000 a year, per head. The median firm spends about $11.38. Roughly one enterprise seat.
That is a gap of more than 650x between the front of the pack and the middle, and it is widening, because the top spenders are accelerating. Their per-employee spend grew 14.1% last month alone. Ten months ago, in August 2025, we published a post that predicted AI bills of $100,000 a year per developer. It read as a stretch then, but the Ramp number landed at $90,000 and climbing. We were early by about a quarter.
But the ones actually in trouble aren’t the companies at the top of that curve. It is the companies that bet their whole workflow on one vendor and are starting to realize what that actually costs. The top 1% behave differently, as Ramp says: they mix and match, bouncing between multiple frontier models and platforms that give them cheaper open-weight access.
The top 1% of firms tend to mix and match, opting to bounce between multiple frontier models and platforms that give them access to cheaper open source models.
The winners are the ones who orchestrate their work to the right model, which doesn’t always equal the most expensive model that can do it.
Why routing works now
The economics are simple once you ignore the list price. A model is not expensive because its per-token rate is high. It is expensive because of how many tokens it burns to finish a job, and the most powerful models burn the most, since they reason longer and write more on the way to an answer. Default everything to the best model and you pay a premium rate times a premium token count. Match the model to the task and the same work costs a fraction.
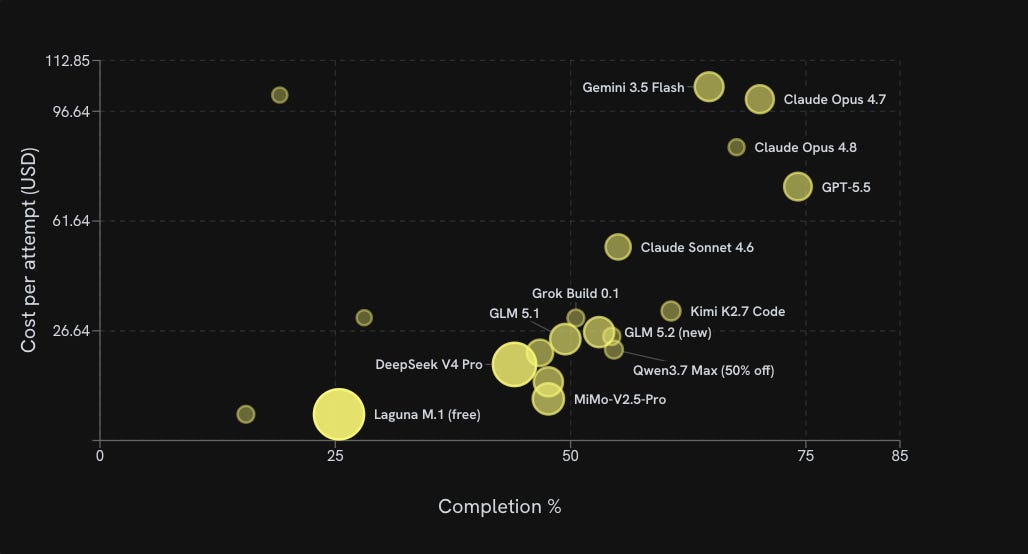
A year ago there was a catch. Routing down meant a worse result, so nobody serious did it on work that mattered. That has changed. Open-weight models have closed much of the gap with the closed frontier on real agentic coding, and we can say so with numbers because we run the models ourselves. KiloBench puts each one through Kilo’s actual agent harness on Terminal Bench 2.0 and reports the true cost and accuracy.
Here is what that looks like in practice. When we ran GLM-5.2 against Kimi K2.7 Code on the same task, the two open-weight models split on planning, where GLM’s plan scored 9.0 to Kimi’s 8.1, but built nearly identical, fully working services from the same spec. The lesson is that most of a build’s quality is decided in the plan, so you can spend your strongest model on the planning and hand the build to a cheaper model and still ship the same service. Used that way, routing is not a compromise. It puts each model where it does its best work.
The trap is the default
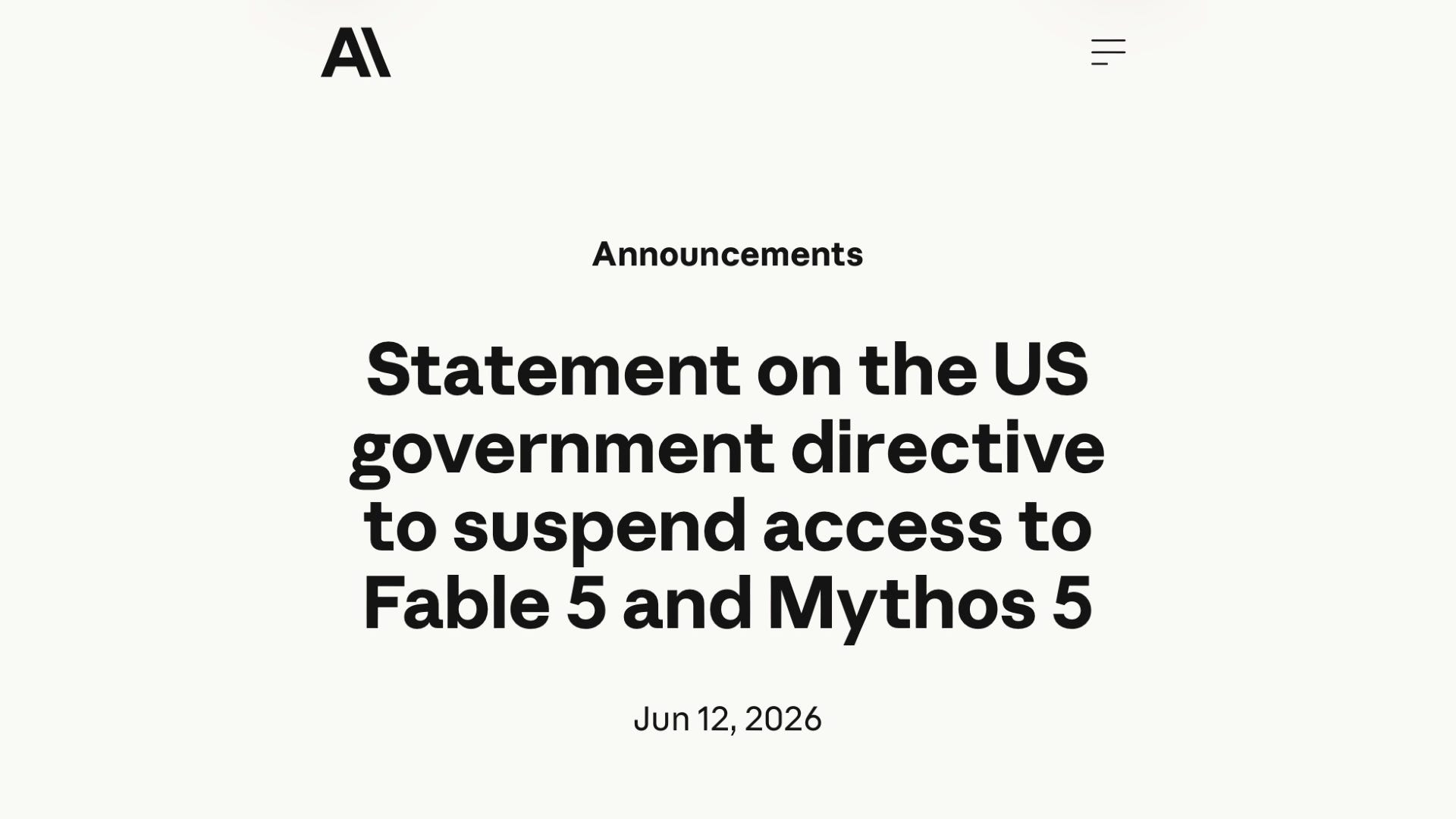
Anthropic’s Claude Fable 5 was the cleanest cautionary tale, precisely because it was an excellent model, which is what made it dangerous as a default. It topped nearly every benchmark and was priced to match, at about $10 per million input tokens and $50 per million output, and because it reasoned longer it burned more tokens on the same job, quietly leaking money out of a budget on work a cheaper model could finish.
Then it vanished. Days after launch, a US export-control directive forced Anthropic to pull Fable 5 and its sibling Mythos 5 for everyone, including paying enterprise customers and Anthropic’s own staff. The most capable coding model on the market was live one day and gone the next, and the teams that had wired their workflow to it had no recourse. You did not need that ceiling to keep shipping. On KiloBench, Kimi K2.7 Code, GLM 5.2, and MiniMax M3 all post solid completion rates at a fraction of frontier pricing. Pricing can double, terms can change underneath you, and a whole model can be revoked by a directive nobody at your vendor controls. That is what betting your workflow on one model buys you.
The power is moving to the buyer
As routing spreads across corporate America, pricing power rebalances from the companies selling premium AI toward the companies buying it. When buyers route the routine, high-volume work to cheaper models, the frontier labs increasingly earn on the hard jobs, the complex work that genuinely needs their best reasoning. The revenue does not vanish, since that work is also the best paid, but its shape changes, and so does who holds the leverage. What shifts is the assumption some valuations lean on, that buyers will reach for premium models by default rather than by fit.
For any single model, that means earning each task on the merits, against a field of cheaper models that are now good enough for the routine work, with little to keep a buyer in place out of habit. The advantage premium AI assumed it had, enterprises standing on one flagship, becomes a question the buyer re-asks for every task: which model is the right fit here?
This is also why the routing layer is best kept separate from the model layer. A router built by a model vendor will, understandably, favor its own catalog, and for teams already committed to that stack it can do that well. But a buyer weighing options across providers is better served by a layer with no model of its own to favor, one whose only job is to match the work to whichever model wins it, wherever it runs.
You don’t pick a model anymore
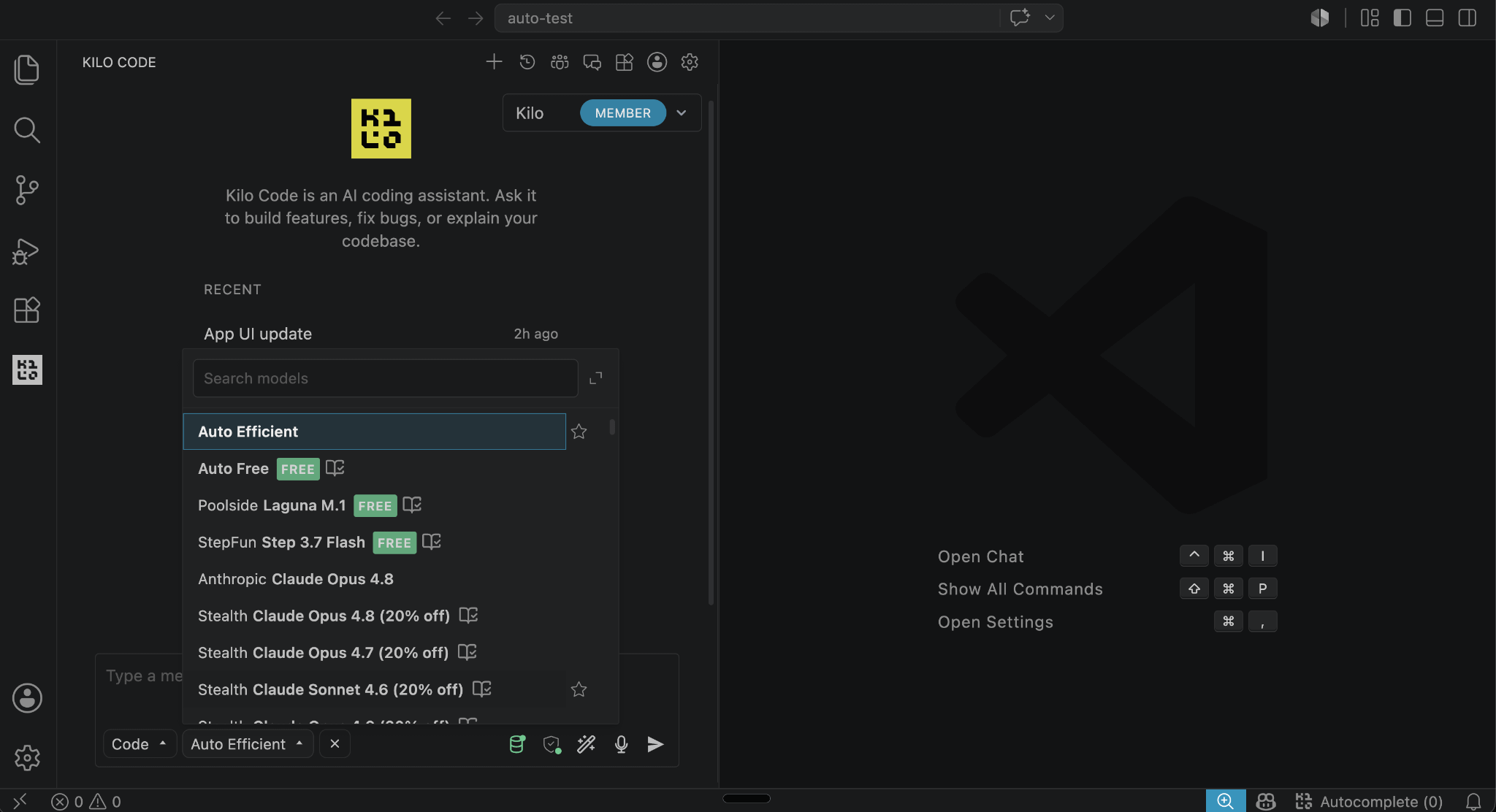
The value is moving from the model to the layer that chooses between models, and that layer has to be neutral to be trusted. That is what we built Kilo to be. When the prevailing wisdom said everyone would consolidate onto one or two providers, we bet the other way: open source, bring your own keys, zero markup, real model choice across 500-plus options, and routing that follows real-world usage data and public benchmarks, so you can see why a given model won a given task.
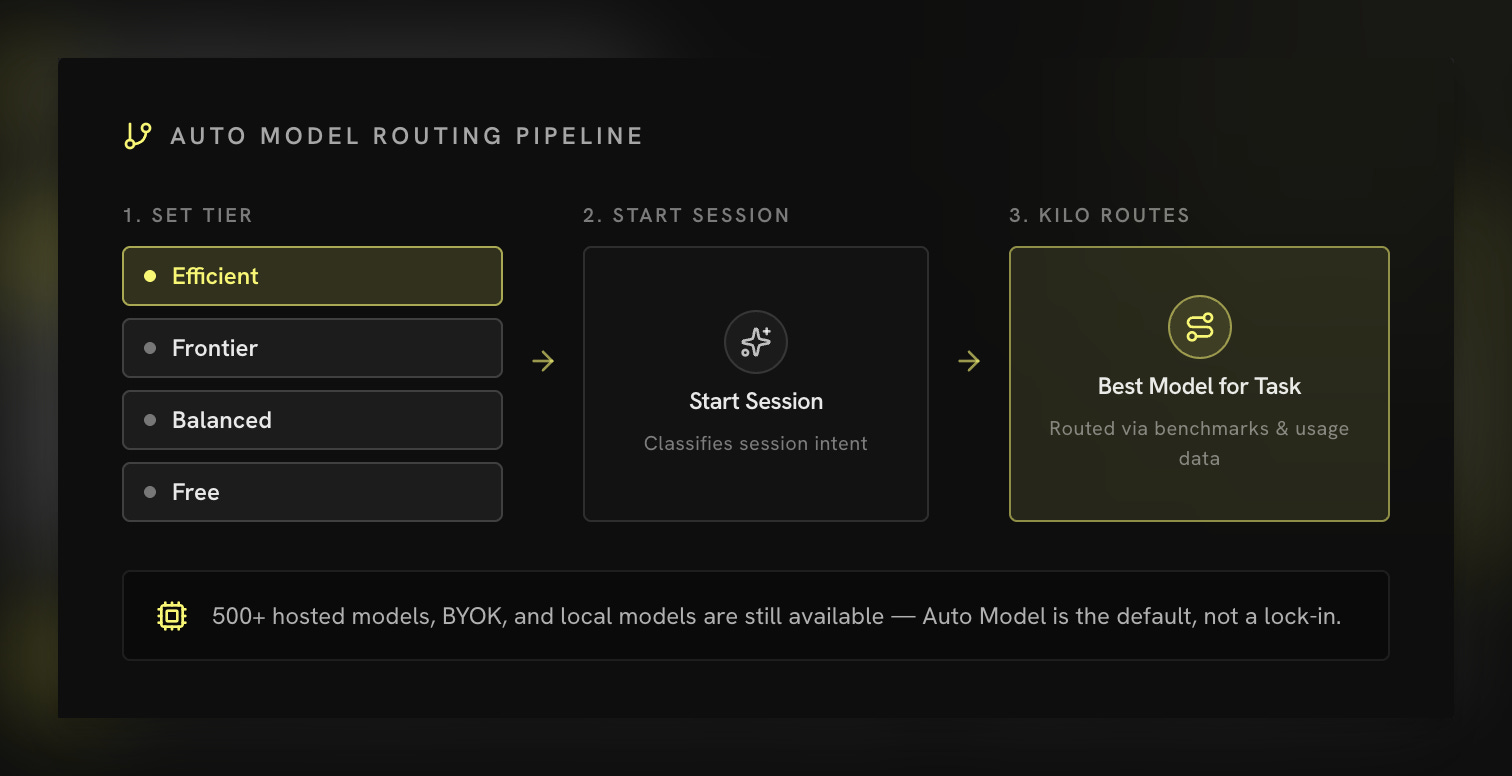
Nobody wants to weigh hundreds of models at different prices for every step of every task. So the answer is a layer that makes the question disappear. That layer is Auto Model. You pick a tier, Frontier, Balanced, or Free, and every request goes to the model that fits the work, with frontier reasoning where it earns its price and cheaper or open-weight models where it does not. It shows you the cost while it runs and steps aside the moment you want to drive.
Today we are taking that further with the launch of Auto Efficient, where the routing is driven by the session itself. When you turn it on, your session is first classified by the kind of work it is, and then, using that classification together with our public benchmarks, KiloBench and PinchBench, Kilo picks the model that wins that specific session. You are not choosing a model, or even a tier per task. The session tells the router what it needs, and the router answers with the model the benchmarks say is best.
The teams that come out ahead are the ones that stopped betting their roadmap on a single model. That is what Auto Efficient is built to do. You no longer choose a model. You choose how you choose models.