
GitHub Copilot Will Soon Train on Your Data
Kilo remains devoted to transparency and model freedom

GitHub recently announced updates to their Copilot interaction data usage policy. Moving forward, unless users explicitly opt out, GitHub Copilot may “collect and leverage” a comprehensive list of interaction data to train and improve their AI models.
According to their update, this interaction data includes:
Outputs accepted or modified by you
Inputs sent to GitHub Copilot, including code snippets shown to the model
Code context surrounding your cursor position
Comments and documentation you write
File names, repository structure, and navigation patterns
Interactions with Copilot features (chat, inline suggestions, etc.)
Your feedback on suggestions (thumbs up/down ratings)
From an AI engineering perspective, their rationale makes perfect sense. Real-world data creates smarter models. And we should note that only Copilot Free, Pro, and Pro+ users will be opted into their new policy by default.

But from a developer’s perspective, this highlights a fundamental structural reality: when you choose a software vendor that is also building and training a foundational AI model, your incentives are not aligned. Their need for massive amounts of interaction data will naturally conflict with your need for default codebase privacy.
At Kilo, we have taken a different path. Transparency is in our DNA. Just last month, we released the source code for Kilo Gateway and our Cloud backend infrastructure. We’ve always offered broad BYOK coverage, and the Kilo Gateway also gives you easy access to all of the best models, including the latest drops from labs like MiniMax and Anthropic.
Let’s talk about what that means for your daily workflow.
The Kilo Philosophy: We Build Agents, Not Models
Kilo Code is a leading open-source AI coding agent designed specifically to help you build, ship, and debug faster. As we expand to support a broader range of personal AI use cases, we’re staying focused on building the best products. Because we do not train foundational LLMs, our ecosystem isn’t hungry for your data.
Our incentive is 100% aligned with yours: make the best, most reliable agents possible.
We don’t store your code, we don’t use your interaction data for training, and we don’t bury an opt-out toggle in a settings menu. Whether you are using our specialized Architect Mode to plan a massive refactor, or debugging an elusive error inside an IDE like VS Code or JetBrains, your codebase remains entirely yours.
We build to support a broad range of users and use cases, without needing to train on your data. We couldn’t be launching powerful agentic tools like KiloClaw if we were focused on training models instead of building the best agents.
True Model Freedom (No Lock-In)
We believe that developers shouldn’t be locked into a single proprietary ecosystem. Kilo Code acts as a neutral orchestrator, giving you absolute freedom to choose the right intelligence for the job.
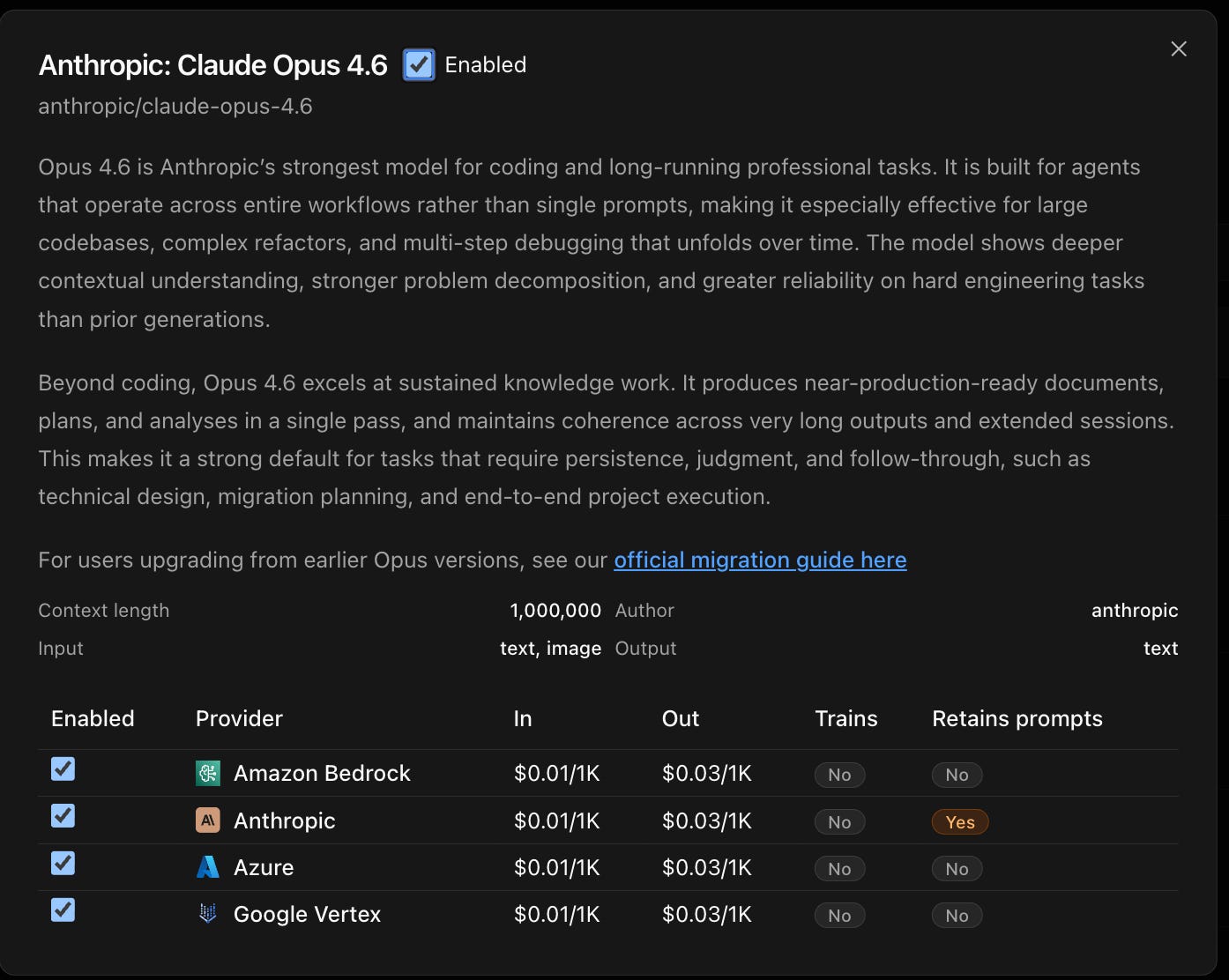
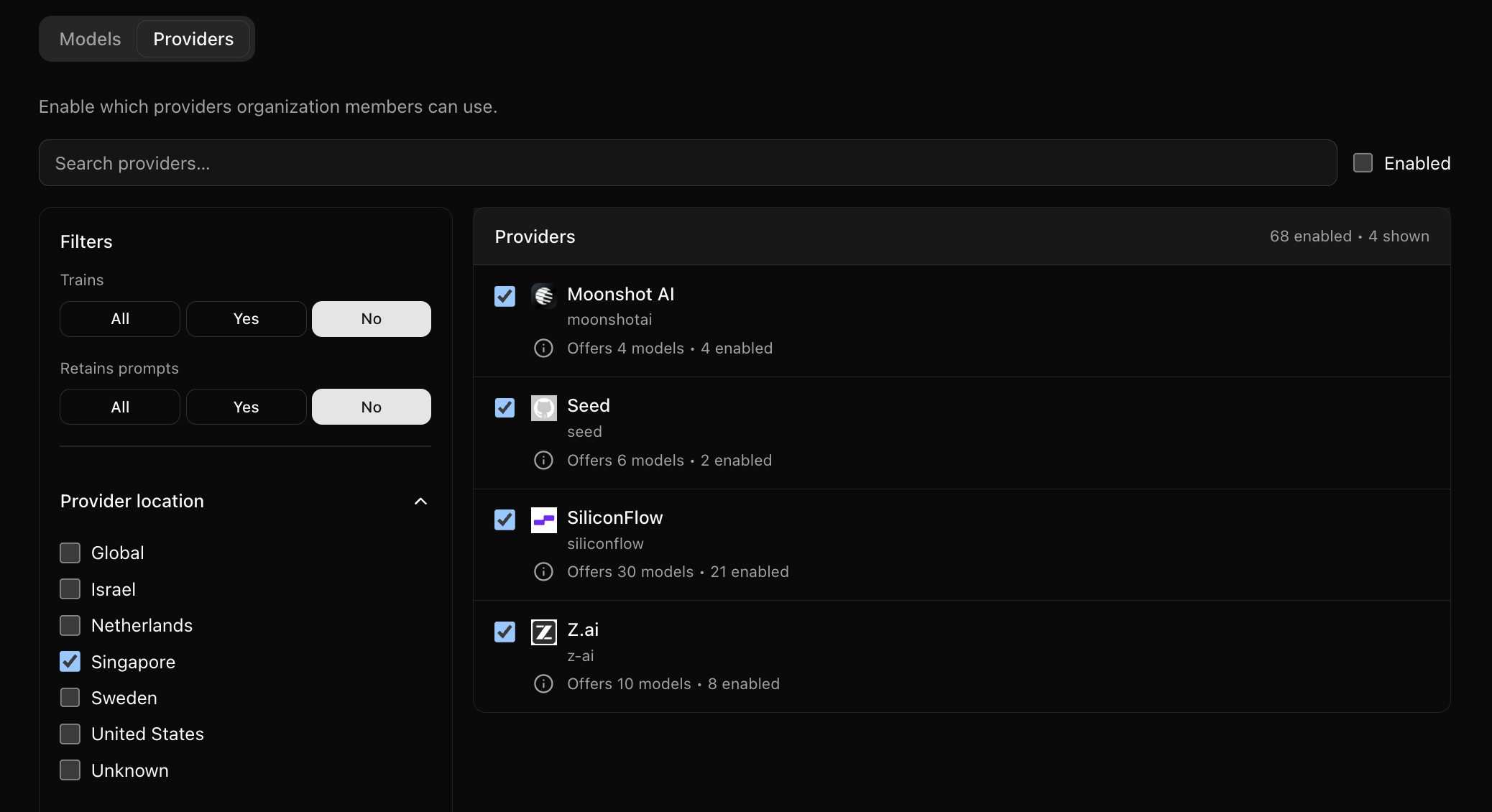
500+ Models on Demand: Through our integrations, you can connect to hundreds of different AI models instantly. You can check model and provider data policies from your Kilo admin dashboard.
Mix and Match: Use the deep reasoning power of Claude 4.6 Opus to plan complex features, switch to Kimi K2.5 or Nemotron 3 Super for agentic work, or just try one of Kilo auto modes to automatically switch between the best models for the job.
BYOK: Want to bring your own API key to Kilo? No problem. BYOK setup is easy, and you can even use external subscriptions like your GLM coding plan.
Want even more privacy and control? Kilo also supports running local models using tools like Ollama. Your code, your prompts, and your interaction data never even leave your laptop.
Open, Flexible, and Built for the Community
Building software is a collaborative effort, and the tools we use should reflect that. That is why Kilo Code remains proudly open-source under the Apache 2.0 license. We are committed to keeping Kilo open and free, allowing you to seamlessly integrate AI into your workflow without worrying about unexpected policy changes.
With a massive community of developers already actively using Kilo, we are proving every day that you don’t need to trade your codebase privacy for cutting-edge AI assistance.
I hope that Kilo migrates away from Github to a first class FOSS platform like Codeberg. From their homepage: "No tracking. No third-party cookies. No profiteering. Everything runs on servers that we control. We will not sell your data."
For now, I'm self hosting my private repos on gitea/forgejo and hope that a similar platform for private repos emerges (one that is resistant to enshittification).
Very nice. Please where in Kilo is it possible to find information about models and providers which are shown in this article? I mean select which provider will be used for given model. And filtering providers based on their location. Thanks!