
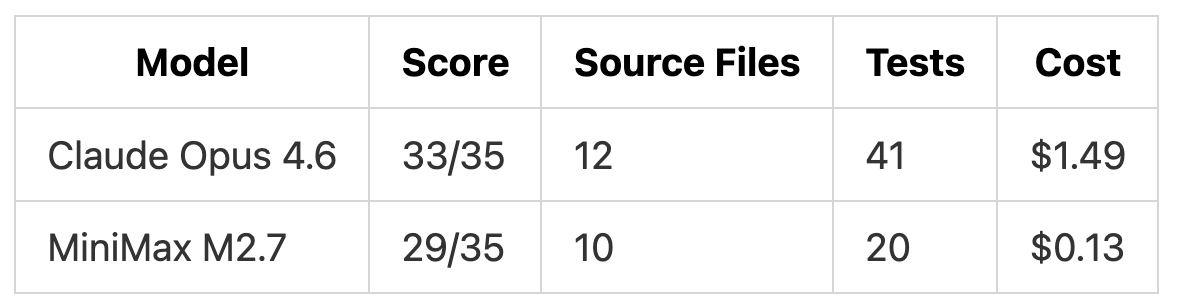
We Tested MiniMax M2.7 Against Claude Opus 4.6

MiniMax M2.7 launched on March 18 scoring 56.22% on SWE-Pro, close to Claude Opus 4.6. We ran both models through three coding tasks in Kilo Code to see if the benchmark numbers hold up in practice. On pricing, MiniMax M2.7 runs at $0.30/$1.20 per million tokens (input/output) compared to Claude Opus 4.6’s $5/$25, roughly a 17x difference on input and 21x on output.

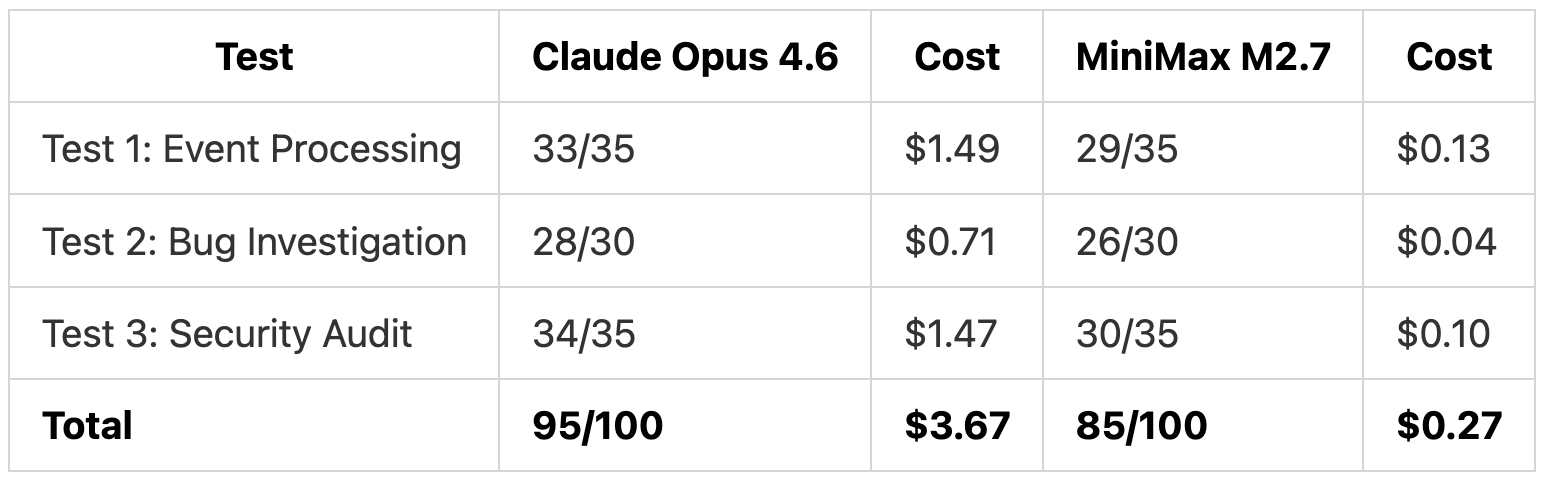
TL;DR: Both models found all 6 bugs and all 10 security vulnerabilities in our tests. Claude Opus 4.6 produced more thorough fixes and 2x more tests. MiniMax M2.7 delivered 90% of the quality for 7% of the cost ($0.27 total vs $3.67).
Test Design
We created three TypeScript codebases and ran both models in Code mode in Kilo Code for VS Code. Each model received the same prompt with no hints. We scored each model independently after all tests were complete.
Test 1: Full-Stack Event Processing System (35 points) - Build a complete system from a spec, including async pipeline, WebSocket streaming, and rate limiting
Test 2: Bug Investigation from Symptoms (30 points) - Trace 6 bugs from production log output to root causes and fix them
Test 3: Security Audit (35 points) - Find and fix 10 planted security vulnerabilities across a team collaboration API
Test 1: Full-Stack Event Processing System
We gave both models this prompt:
“Build a real-time event processing system in TypeScript from the specification in @SPEC.md. Use Hono for the web framework, Prisma with SQLite for the database, Zod for input validation, and ws for WebSocket support.”
The spec required 7 components: event ingestion API with API key auth, async processing pipeline with exponential backoff retry, event storage with processing history, query API with pagination and filtering, WebSocket endpoint for live streaming, per-key rate limiting, and health/metrics endpoints.
Both models implemented all 7 components. The score difference came from code organization and test coverage.
Architecture
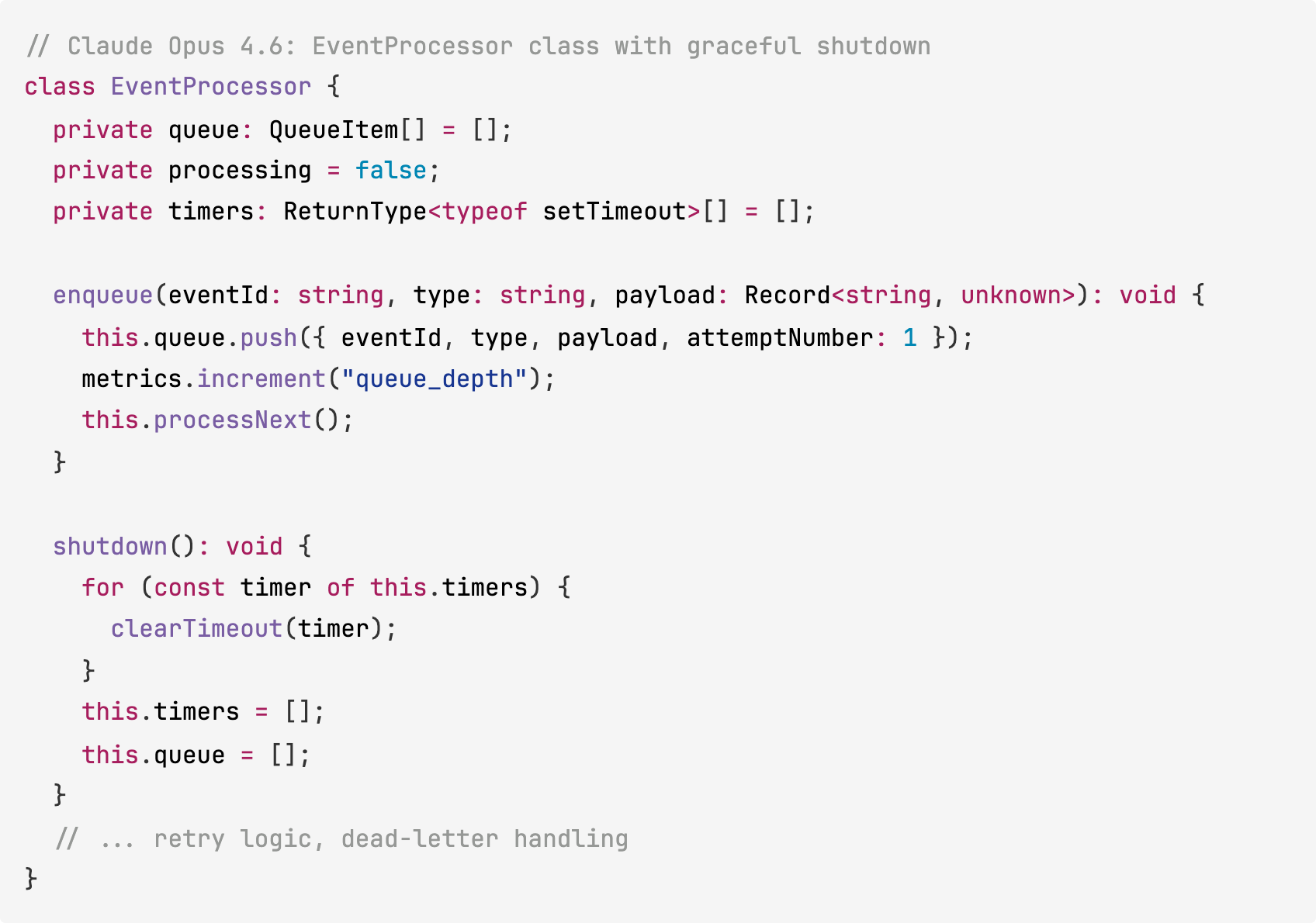
Claude Opus 4.6 created a modular directory structure with separate directories for routes, pipeline, middleware, and WebSocket management. It split the processing logic into separate files for queue management (with retry scheduling and dead-letter routing) and per-type event handlers. It also included graceful shutdown with timer cleanup.
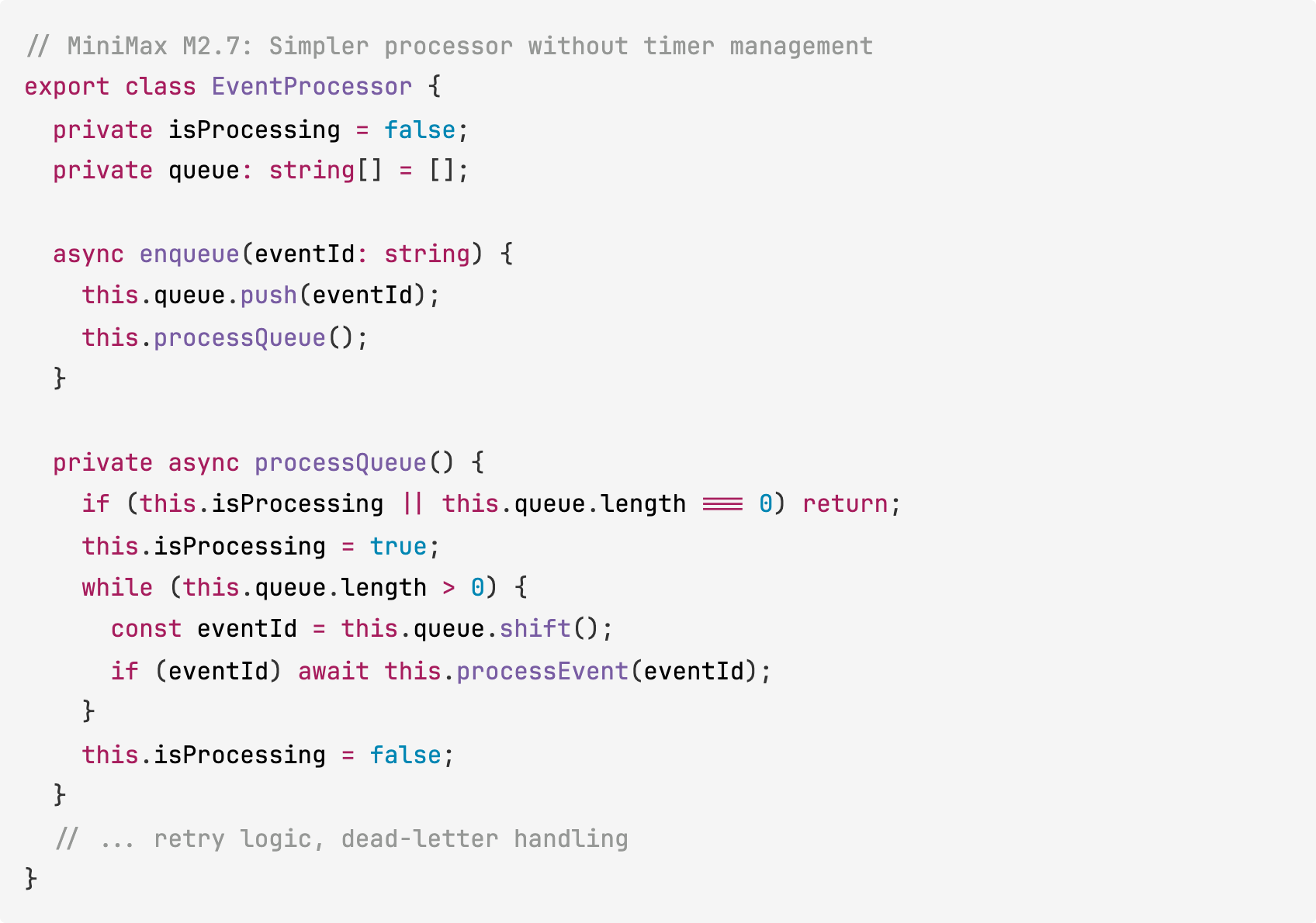
MiniMax M2.7 used a flatter structure with fewer files. All routing lived in a single entry file, and the processor was simpler with no shutdown management or timer tracking.
Test Coverage
Claude Opus 4.6 wrote 41 integration tests with a dedicated test database and proper cleanup between tests. The tests make actual HTTP requests against the API, testing the full middleware chain end-to-end.

MiniMax M2.7 wrote 20 unit tests that validate Zod schemas and handler functions directly. These cover the core logic, but don’t test the API endpoints or middleware through HTTP, so routing or middleware bugs would slip through.
Test 1 Scoring
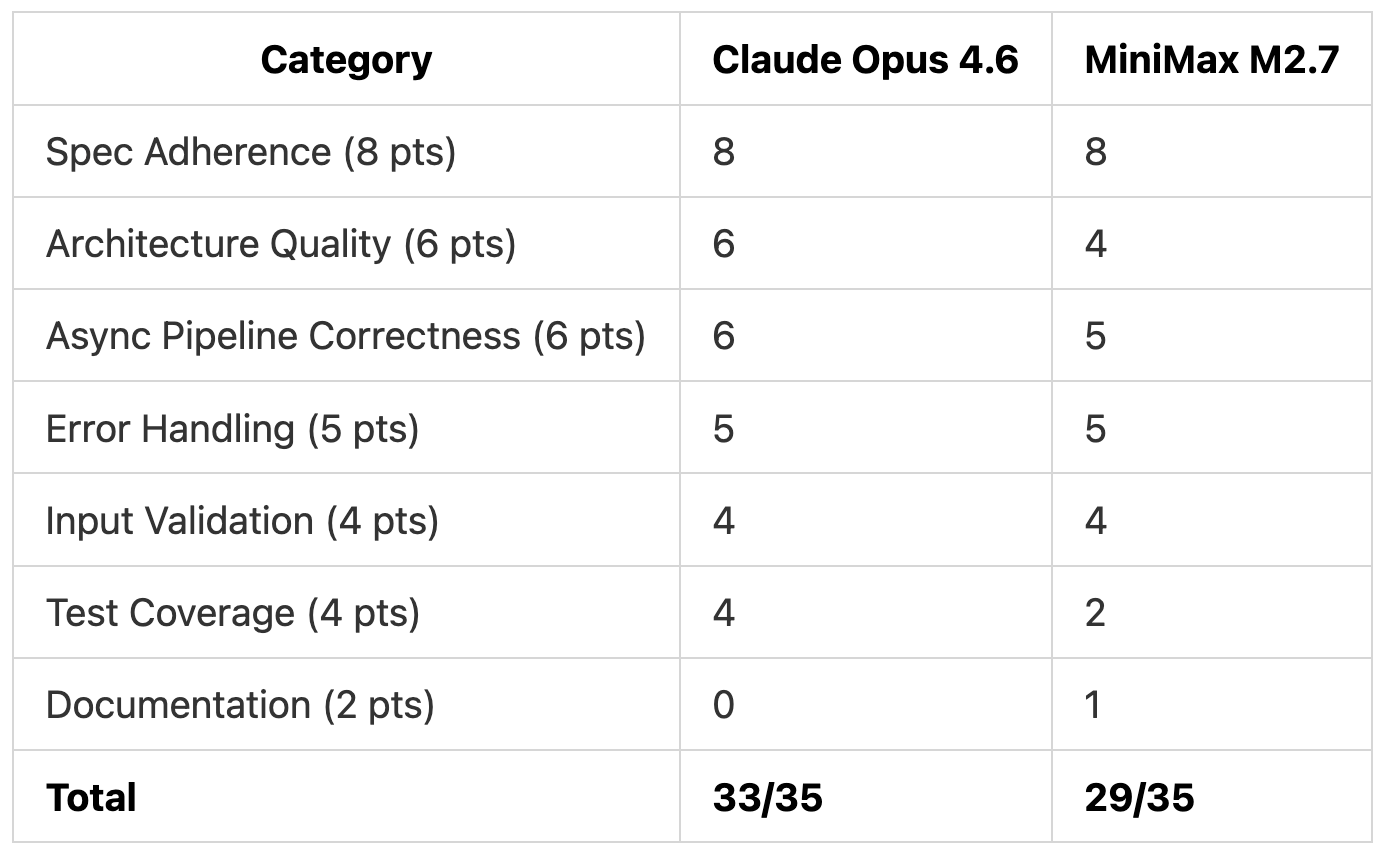
Claude Opus 4.6 lost 2 points for not generating a README (the spec asked for one). MiniMax M2.7 generated a README but lost points on architecture and test coverage.
Test 2: Bug Investigation from Symptoms
We built an order processing system with 4 interconnected modules (gateway, orders, inventory, notifications) and planted 6 bugs. We gave both models the codebase, a production log file showing symptoms, and a memory profile showing growth data. The prompt listed the 6 symptoms and asked both models to investigate, find root causes, and fix them.
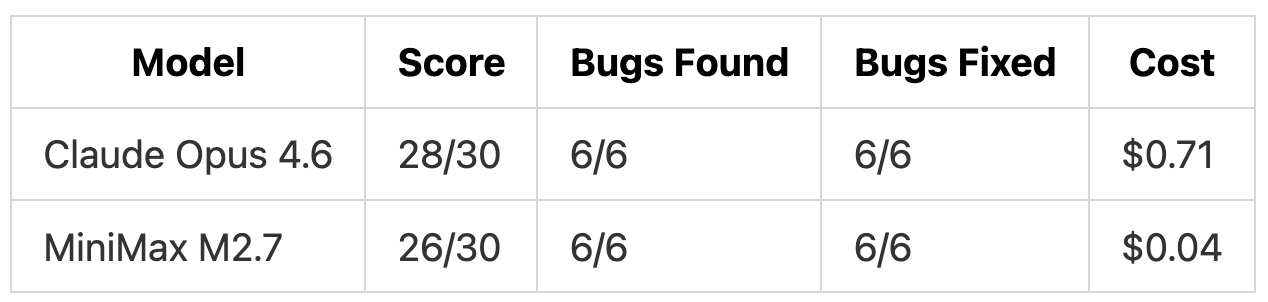
Both models found all 6 root causes.
Bug #1: Race Condition in Inventory
Stock was checked first, then reserved in a separate transaction. Two concurrent orders could both pass the check before either reserved. Both models identified this from the logs and fixed it by making the reservation atomic.
Claude Opus 4.6 also added rollback logic. If reserving stock for one item in a multi-item order fails, it releases the items that already succeeded and marks the order as “failed.” MiniMax M2.7 made the reservation atomic but didn’t add rollback, so partial failures can leave orphaned reservations.
Bug #4: Floating-Point Totals
The order total calculation used standard floating-point arithmetic, which produces results like 159.92000000000002 for certain price and quantity combinations. The logs showed repeated “Total validation warning” entries where the expected and calculated totals differed by tiny fractions.
Claude Opus 4.6 rounded the result after calculation:

MiniMax M2.7 converted to integer math (cents), avoiding the precision problem entirely:

MiniMax M2.7’s approach is technically better here. Working in cents avoids accumulation errors that rounding after the fact can miss on large orders.
Remaining Bugs
Both models fixed the other 4 bugs with the same approach:
Notification ordering (Bug #2): Added a status check before sending confirmation emails, skipping orders that were already cancelled
Memory leak (Bug #3): Removed a per-order event listener that was never cleaned up, accumulating with each request (the memory profile showed listener count tracking 1:1 with request count)
Stale inventory cache (Bug #5): Added cache invalidation calls after stock updates, so the 60-second cache TTL no longer serves stale data
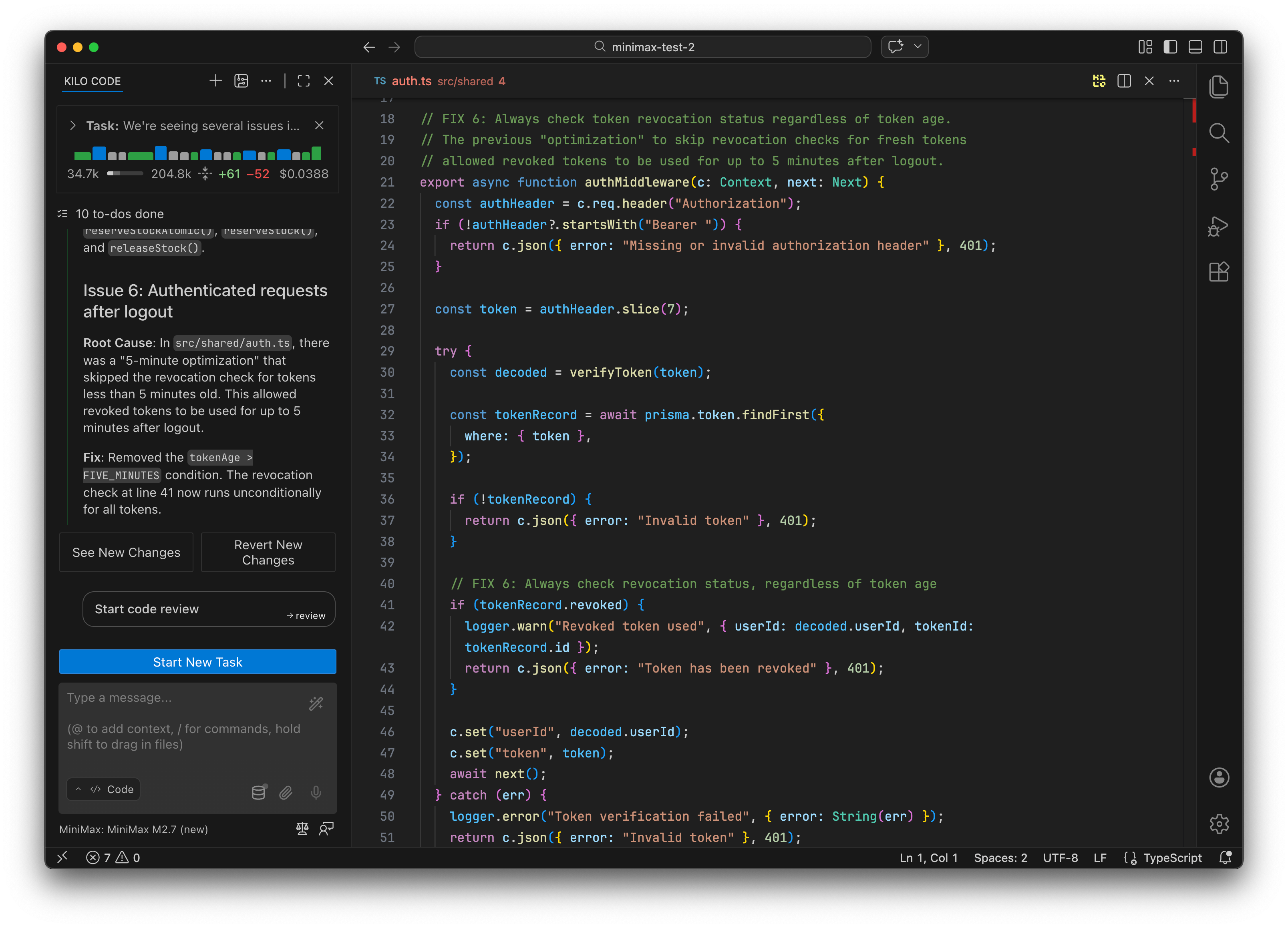
Token revocation bypass (Bug #6): Removed a “5-minute optimization” that skipped the revocation check for fresh tokens
Test 2 Scoring
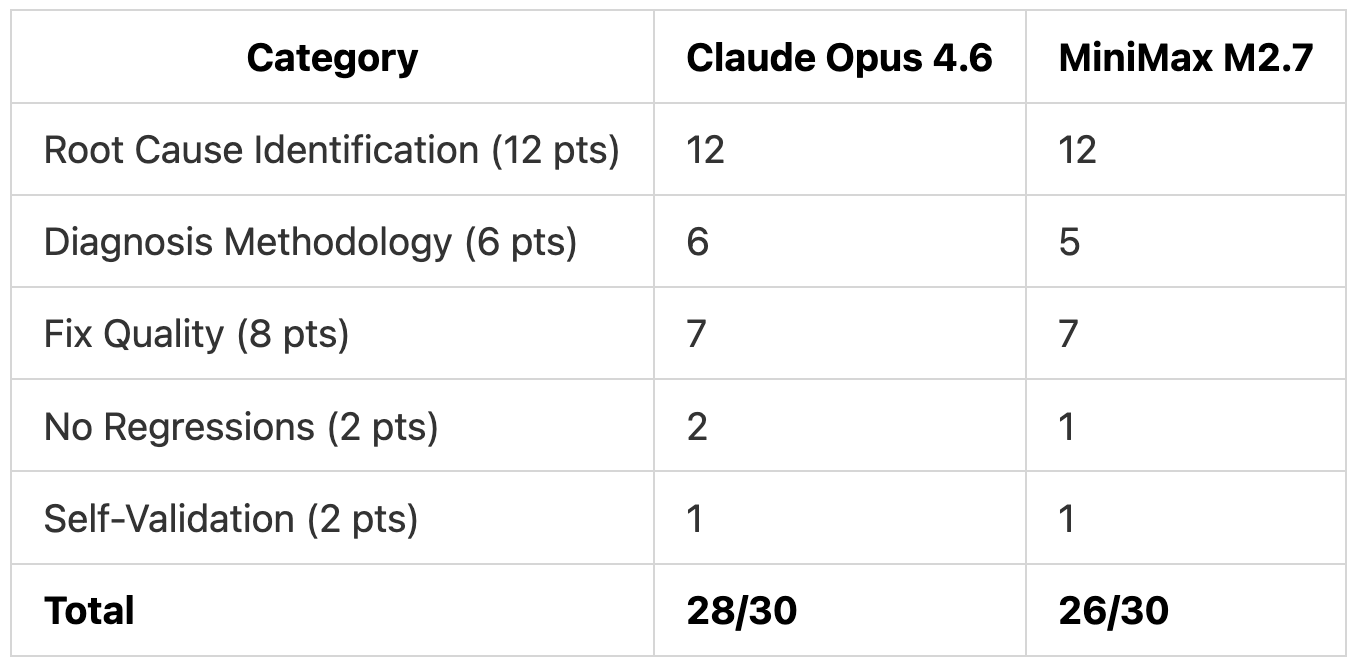
Both models verified their fixes by running curl requests against the server. Claude Opus 4.6 explicitly referenced log entries when explaining each bug, while MiniMax M2.7 jumped more directly to the code.
Test 3: Security Audit
We built a team collaboration API (Hono + Prisma + SQLite) with 10 planted security vulnerabilities. We asked both models to audit the codebase, categorize each vulnerability by OWASP, explain the attack vector, rate severity, and implement fixes.
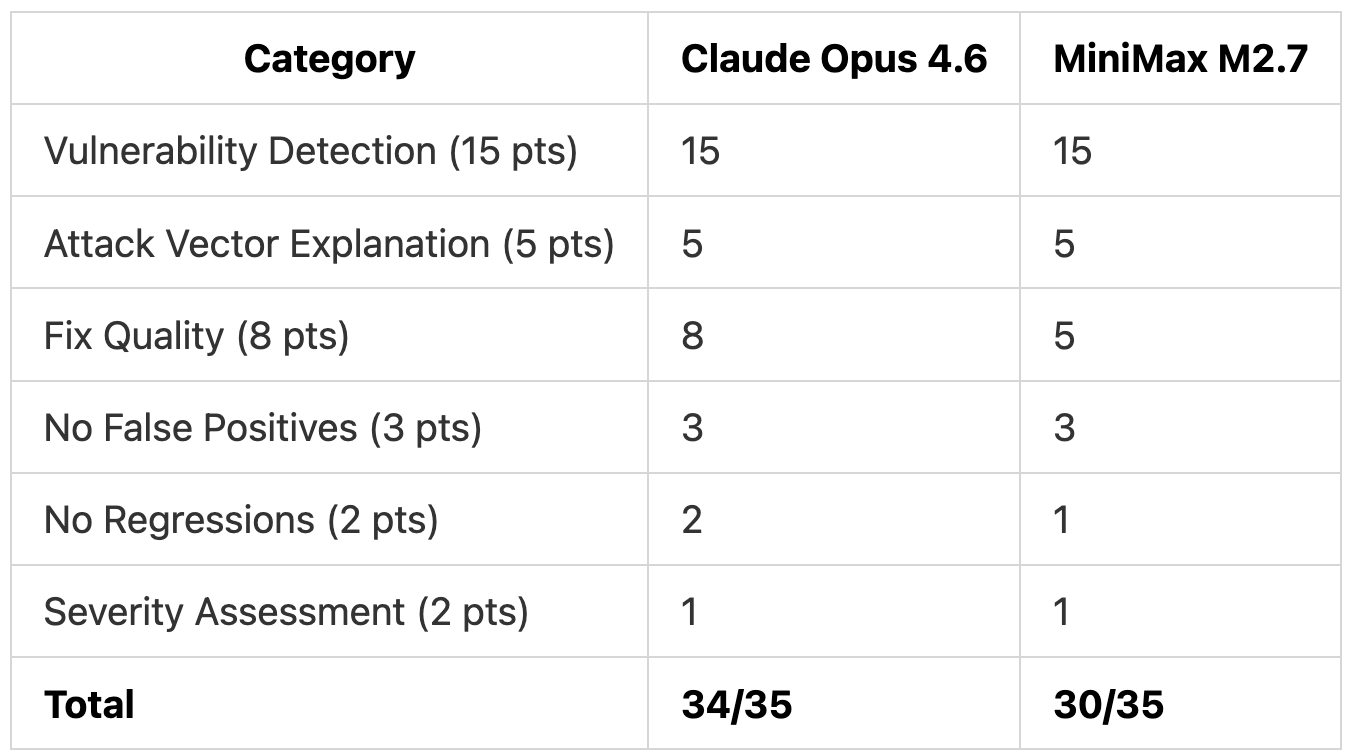
Both models found all 10 vulnerabilities with correct OWASP categorizations. The 4-point gap is entirely in fix quality.
Where the Fixes Diverged
Password hashing: Claude Opus 4.6 used scrypt with random salts and timing-safe comparison. MiniMax M2.7 used SHA-256 with the JWT secret as the salt, and flagged in its own output that bcrypt would be better.
Insecure deserialization: Both removed the
eval()on webhook transforms. Claude Opus 4.6 replaced it with a safe JSON key-mapping system. MiniMax M2.7 disabled transforms entirely.SSRF protection: Claude Opus 4.6 validated webhook URLs at creation, update, and delivery. MiniMax M2.7 validated at delivery only.
Rate limiting: Claude Opus 4.6 applied per-endpoint limits (login, register, password reset). MiniMax M2.7 only rate-limited the login endpoint.
JWT fix: Both moved the hardcoded secret to an environment variable. Claude Opus 4.6 let
jwt.verify()handle expiration natively. MiniMax M2.7 fixed the broken manual comparison, which works but duplicates built-in functionality.
Test 3 Scoring
Overall Results
The Bigger Picture
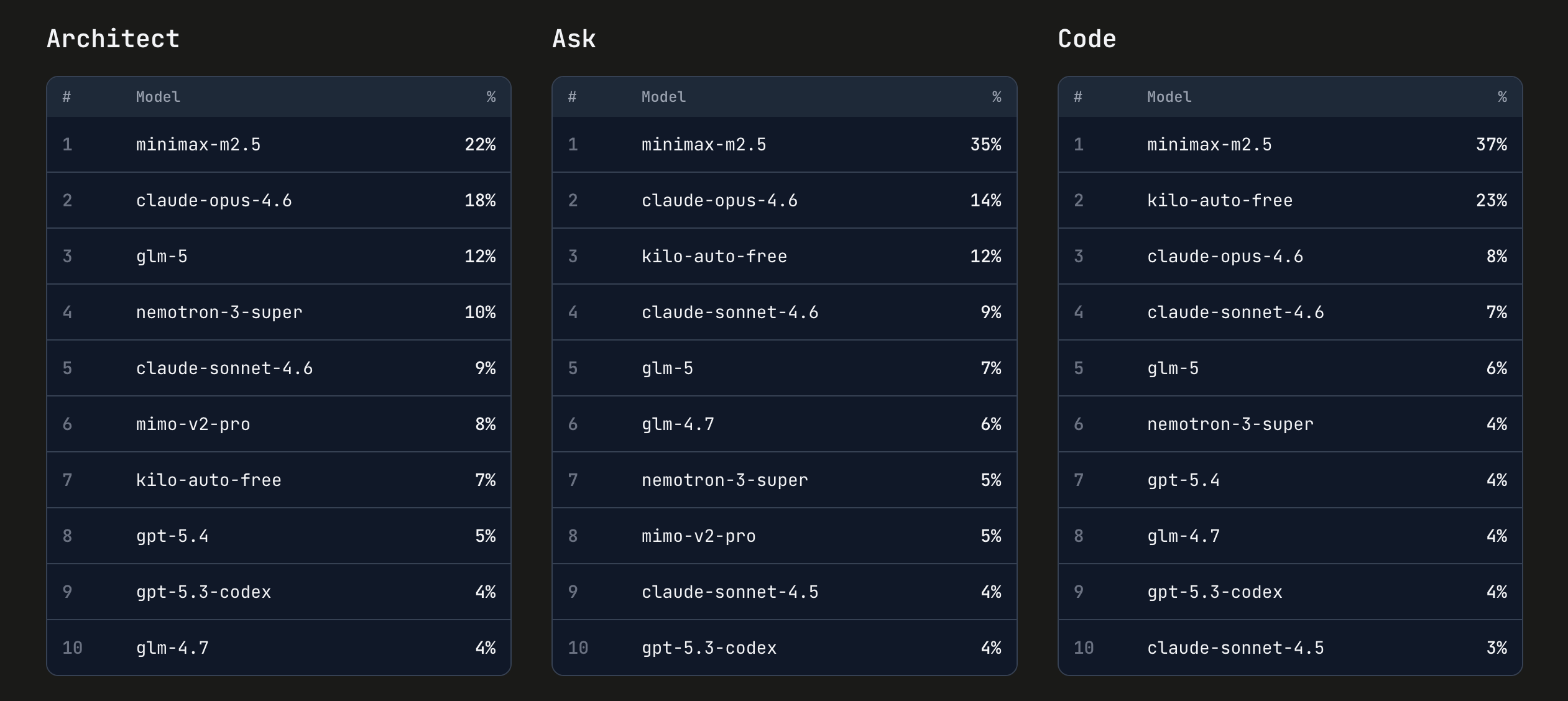
We’ve been testing MiniMax models since M2 last November. Earlier versions competed against other open-weight models like GLM 4.7 and GLM-5. With each release, the scores climbed and the cost stayed low. MiniMax M2.5 (the previous version) is currently the #1 most-used model across every mode in Kilo Code, ahead of Claude Opus 4.6, GLM-5, and GPT-5.4. In Code mode it accounts for 37% of all usage. In Ask mode, 35%.
MiniMax M2.7 is the first version where we felt the right comparison was a frontier model rather than another open-weight one. It matched Claude Opus 4.6’s detection rate on every test in this benchmark, finding the same bugs and the same vulnerabilities. The fixes aren’t as thorough yet, but the diagnostic gap between open-weight and frontier models is shrinking with every release.
Takeaways
For building from scratch: Claude Opus 4.6 produced 41 integration tests and a modular architecture. MiniMax M2.7 built the same features with 20 unit tests and a flatter structure, at $0.13 vs $1.49.
For debugging: Both models found all 6 root causes from log symptoms. MiniMax M2.7 even produced a better fix for the floating-point bug. Claude Opus 4.6 added rollback logic that MiniMax M2.7 missed.
For security work: Both models found all 10 vulnerabilities. Claude Opus 4.6’s fixes are closer to what you’d ship (proper key derivation, feature-preserving alternatives, defense-in-depth). MiniMax M2.7 closes the same vulnerabilities with simpler approaches and sometimes flags its own shortcuts.
On cost: $3.67 total for Claude Opus 4.6 vs $0.27 for MiniMax M2.7. Detection was identical. The gap is in how thorough the fixes are.
Testing performed using Kilo Code, a free open-source AI coding assistant for VS Code and JetBrains with 1,500,000+ Kilo Coders.
So, this compares like a BMW vs a Toyota?
How does it compare to claude sonnet 4.6? Can someone please reply? Thank you!