
DeepSeek-V4 is Here. So is Everybody Else.
In the crowded LLM ocean, is the newest whale worth pursuing?

A few months ago, I wrote about DeepSeek V4 rumors vs. reality — separating the benchmark leaks from the actual engineering signals buried in arXiv papers and commit histories. The TL;DR was: the technical foundations are real, the hype is mostly noise, and the rest of the field is moving fast enough that V4 wouldn’t land in a vacuum.
Well, V4 is here. And I was right about the vacuum part.
Let’s talk about what actually shipped, how the competitive landscape has evolved faster than ever, and what this all means for building with Kilo.

What Actually Dropped (And What Didn’t)
Here’s the first thing to notice: DeepSeek didn’t release a single “V4.” At least not yet. Instead they released two models — DeepSeek-V4-Pro (1.6T total / 49B active parameters) and DeepSeek-V4-Flash (284B total / 13B active). Both are live in Kilo Code today.
That’s a Pro and a Flash. Not a general V4 launch in the way the community was expecting.
Which raises the obvious question: why structure the release this way?
My read is that it’s a deliberate hedge. A single monolithic “V4” model would be benchmarked against every frontier model on every task simultaneously, as happened with DeepSeek’s legendary R1 release back in January 2025 (can you believe that was only 15 months ago?). Instead, you get a high-capability Pro tier and a fast-and-cheap Flash tier — two different horses for two different races. It’s smart positioning, but it also signals something: DeepSeek is no longer operating as the scrappy underdog with nothing to lose.
This is a mature, strategic release. The problem is that the pricing reflects that maturity too.
The Price Point Changes Everything
When V3 dropped, the pricing was genuinely disruptive. The community freaked out. US tech stocks wobbled. The headline was: “DeepSeek just made the incumbents look expensive.”
V4 doesn’t have that same energy.
The API pricing on V4-Pro has come in meaningfully higher than V3’s debut rates — and that shift matters. Because in the time between V3 and V4, the rest of the open-source and open-weight world got dramatically more capable, as did models from all of the frontier labs. When DeepSeek raised the floor on its own pricing, it accidentally made a dozen other models look equally competitive. Although listed at $0.435 per million input tokens and $0.003625 per million cache read, hosting and servicing DeepSeek models is no easy task; to get usable inference with enough context to be meaningful, pricing in the wild has ended up around $1.74/M input tokens and $0.145/M cache.
This might change as more providers host and optimize the new models, but for now this is the reality.
Just look at what’s sitting in the model switcher in the Kilo Gateway right now: equally capable models like Kimi K2.6 (and K2.5 for that matter), a variety of impressive Qwen3.6 models from Alibaba, and the V2 and V2.5 suites from Xiaomi. In practice, Qwen’s directly competitive models end up similarly priced to the new DeepSeek, and Xiaomi’s newest model, V2.5 Pro, is actually cheaper, with a weighted average input price of $0.29 per 1M tokens on OpenRouter.
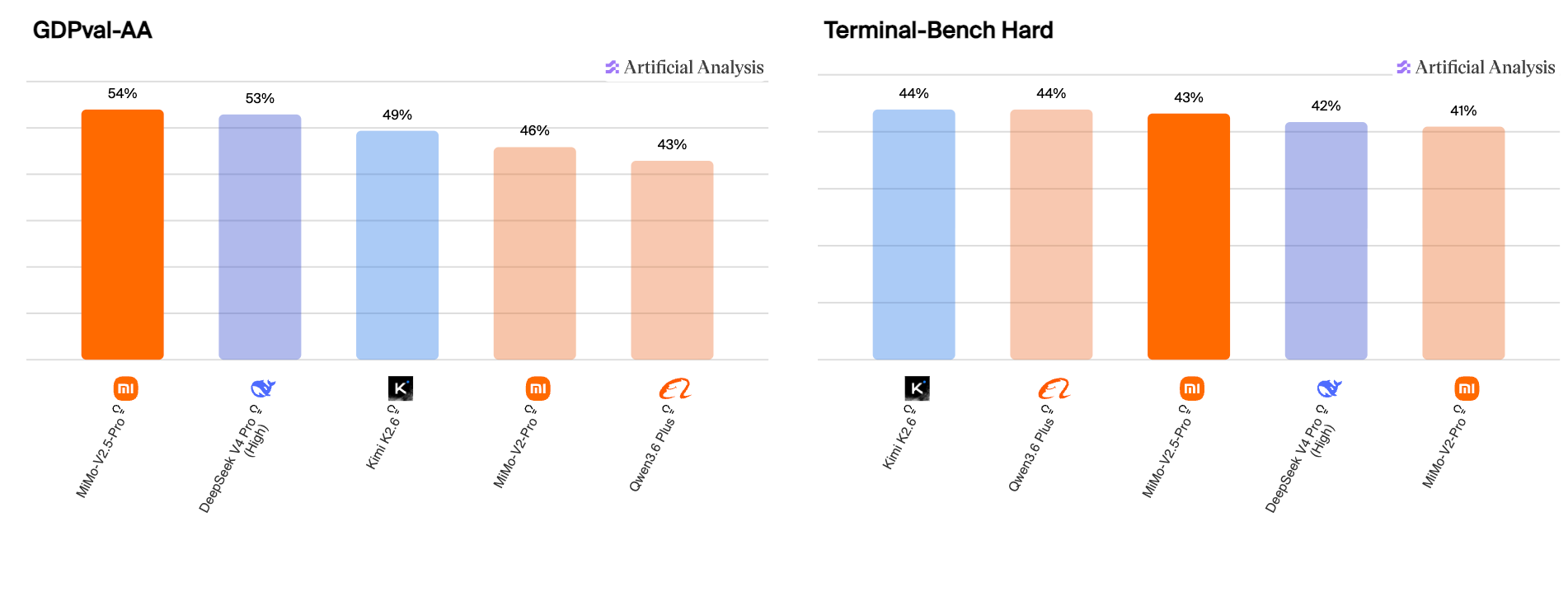
MiMo-V2-Pro launched in March and has been one of our most consistently popular budget-tier picks — even after the free period ended. I don’t mean “budget” in a derogatory way. I mean that it gives a lot of bang for the buck.
Mimo-V2 Pro is a 1 trillion parameter reasoning model with a 1M context window, built explicitly for agentic work, and it’s been quietly competitive with models that cost twice as much. Xiaomi then quickly launched V2.5 Pro and Flash models, which are also rising on the Kilo leaderboard. The point is: Xiaomi is not playing around, and at their price point, the MiMo family deserves to be in the same sentence as V4-Flash for a lot of everyday workflows.
The math that made “just use DeepSeek” a no-brainer in early 2026 is a lot fuzzier now.
The Frontier Labs Didn’t Wait Around
Here’s what I didn’t fully outline when I wrote the original post: how fast the closed-source labs would accelerate in the same window.
OpenAI released GPT-5.5 last week and that set an even higher benchmark for both intelligence and token efficiency. OpenAI models were always strong on the OckBench benchmark (along with Google Gemini and Moonshot AI), so it should come as no surprise that GPT-5.5 is super-efficient. But we’ve been blown away by the new OpenAI model’s efficiency for coding tasks, even when handling a huge codebase or refactor.
And while everyone was watching the DeepSeek release calendar, Google shipped Gemma 4 — and it’s a bigger deal than the open-weight community gave it credit for at launch. Gemma 4 is multimodal across text, image, video, and audio, making it a good fit for OpenClaw. In addition it offers:
A 256K context window on the medium models
Configurable thinking modes
Makes local deployment genuinely accessible
The E2B model runs in as little as 3.2GB at 4-bit quantization, which means a capable local coding assistant on a laptop, not just a party trick. For Kilo users who want to self-host something highly capable for daily agentic tasks, Gemma 4 is a good fit.
And of course Anthropic released Claude Opus 4.7 and an Opus Fast variant that have genuinely changed how we think about the top end of the market. Anthropic models have never left the top ten on the Kilo leaderboard. These new releases were just a bit quieter with the community distracted by Anthropic’s pricing and subscription changes.
The competitive dynamic has completely flipped from early 2025. Back then, “wait for DeepSeek to catch up” was a reasonable strategy. Now the frontier labs are the ones setting the pace, and everyone else — including DeepSeek — is playing catch-up on the intelligence benchmarks.
The Stuff That Is Impressive
None of the above means V4 is a miss. It isn’t.
The 1M context window is real, and it’s not a gimmick. Combined with DeepSeek Sparse Attention (DSA), V4 can hold a lot in context without the usual token-cost blowout that makes long-context work feel like burning money. In Kilo Code, that means you can actually point V4-Pro at your entire codebase — middleware, schemas, test suite, the works — and have it reason across all of it without losing the thread halfway through.
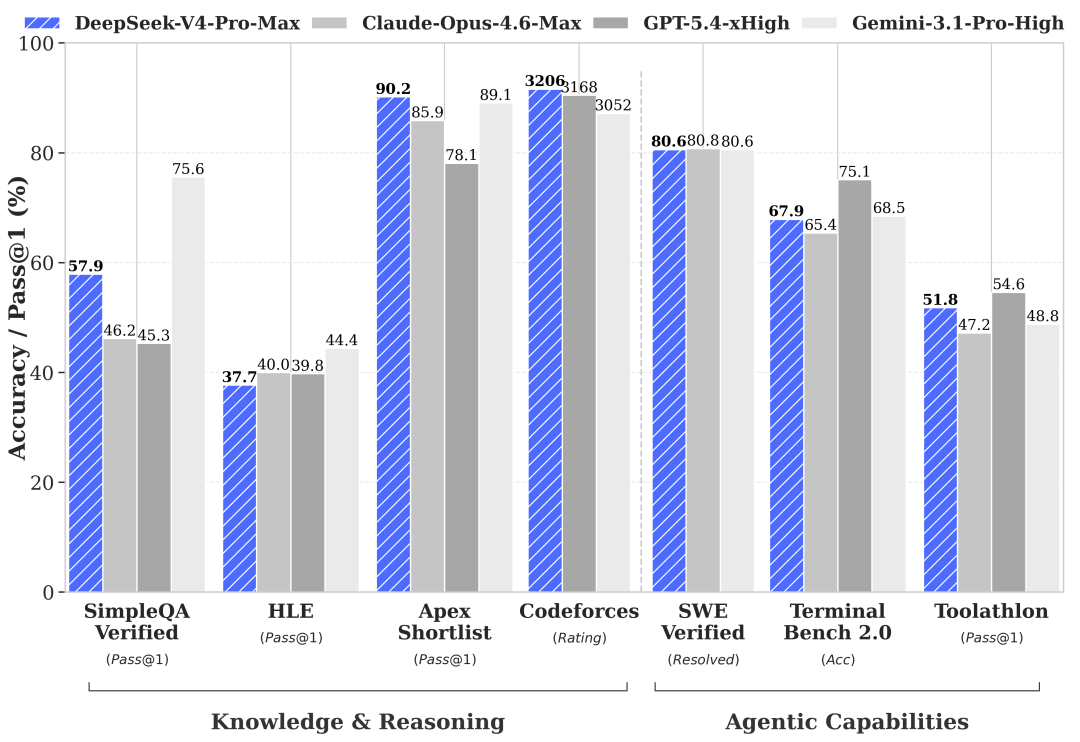
That’s not a new concept, but V4 (which is, after all, just the “preview release”) executes it better than anything we’ve seen at this price tier. And the improved reasoning quality — the “deeper thinking” you get from V4-Pro’s Think mode — is a real upgrade from Terminus. The model is measurably better at following multi-step logic chains without hallucinating intermediate steps.
What this really signals is optimized token use for harder problems. V4 isn’t just bigger, it’s better at knowing when to slow down. For Kilo Code workflows that involve deep codebase changes, V4-Pro is genuinely one of the better options available right now. Not the only one, but a serious one.
So Where Does This Leave Us?
When I wrote the original rumor post, I framed V4 as a potential category-defining release. With the benefit of hindsight: it’s a very good model that arrived in a much more competitive market than DeepSeek’s previous releases did.
The fisherman analogy from the last post still holds — but now there are a lot more fishermen on the water, some of them with better gear. DeepSeek V4 brings a bigger catch than V3, but the ocean has changed.
What this means practically for Kilo users:
If you’re running deep reasoning tasks, complex refactors, or anything that benefits from genuinely large context — V4-Pro is worth taking for a spin.
If you’re running agentic loops at scale and watching costs, V4-Flash competes with Kimi K2.6 and the Qwen3.6 models more than it does with Pro-tier closed-source models. Worth benchmarking against your specific workflow.
If you haven’t tried Opus 4.7 or GPT-5.5 recently, do that. The frontier moved while you were watching the DeepSeek calendar, and the token efficiency of those models might surprise you.
V4 is a solid release. The hype was (as usual) slightly ahead of the reality, but the reality is genuinely good. And in 2026, “genuinely good” is the starting line, not the finish.
So will it claw? Yeah. V4 will claw. So will about fifteen other new models released in the last couple of weeks.
That’s a good problem to have.
Kilo is devoted to model freedom, which means you can always use the latest models and find that perfect balance between intelligence and efficiency. Both DeepSeek V4-Pro and V4-Flash are available now in the Kilo Gateway. Try them for yourselves and see how they fit into your daily workflows.
Bro, talk about the recent GitHub copilot, they have once again gone the same way as cursor