
The Arrival of GPT-5.5: OpenAI’s New Deep-Thinking Powerhouse
Breaking an infamous 3-way tie on the AA Intelligence Index

OpenAI recently rolled out GPT-5.5 and its heavy-duty sibling, GPT-5.5 Pro, and everybody wants to put them to the test.
If you feel like the model landscape is moving faster and faster, you’re right. OpenAI’s chief data scientist told TechCrunch this week that “the last two years have been surprisingly slow,” but what he meant is that now we’re really moving — now we’re cooking with gas. And that’s a good thing for consumers.
These SOTA models aren’t just becoming smarter and more comprehensive, they’re also becoming more token-efficient for larger tasks.
What’s new?
GPT-5.5 is OpenAI’s latest release for complex professional workloads, building on GPT-5.4 with stronger reasoning, higher reliability, and improved token efficiency on hard tasks.
GPT-5.5 Pro is OpenAI’s high-capability model optimized for deep reasoning and accuracy on complex, high-stakes workloads.
Both new models are now available in the Kilo Gateway and GPT-5.5 is one of our top recommended models out of the gate.
A New Standard for Complex Work
GPT-5.5 is particularly impressive when it comes to coding and reasoning, and the kind of computer-use and browser skills needed by always-on agents like KiloClaw:
Terminal-Bench 2.0 (Command-line workflows & tool coordination): 82.7% (vs. GPT-5.4: 75.1% | Claude Opus 4.7: 69.4%)
Expert-SWE (Internal long-horizon coding tasks ~20 hours): 73.1% (vs. GPT-5.4: 68.5%)
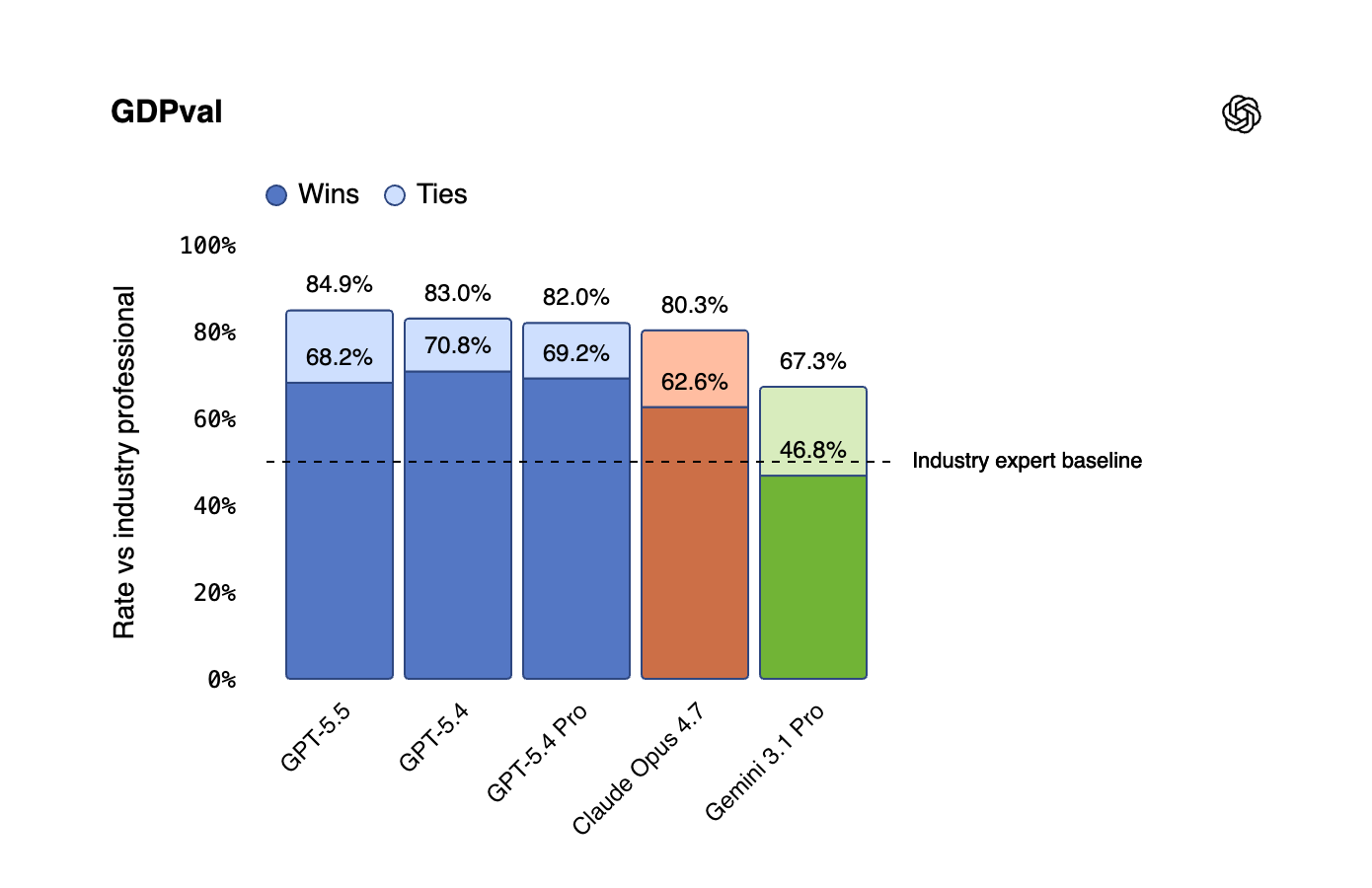
GDPval (Knowledge work across 44 occupations): 84.9% (vs. GPT-5.4: 83.0% | Claude Opus 4.7: 80.3%)
OSWorld-Verified (Operating real computer environments): 78.7% (vs. GPT-5.4: 75.0% | Claude Opus 4.7: 78.0%)
BrowseComp: 84.4% (GPT-5.5 Pro scores 90.1%)
But benchmarks are only half the story. We had the privilege of pre-testing the alpha release of GPT-5.5, and we’re ready to share what this means for builders, agents, and the broader AI ecosystem. First of all, it’s exciting to see OpenAI continuing to bridge the gap between execution and high-level strategy. Coming just two days after the release of GPT-5.4 Image 2, a stunning new image generation model for multimodal workflows, GPT-5.5 covers a lot of bases for professional workloads. This new model can transform how engineering teams scale their most complex autonomous workflows.
In our testing, GPT-5.5 has proven to be tremendously capable at long-context tasks and agentic coding. Where previous generation models would occasionally lose the plot during massive refactoring jobs or deep-reasoning requirements for large codebases, GPT-5.5 stays locked in.
More importantly for our ecosystem, it has become a formidable daily driver for KiloClaw as well as an excellent fit for getting a new claw up and running and exploring new use cases. We’ve been using it to run always-on agents handling highly complex, multi-step professional work, and the reliability jump is palpable.
As we noted in our recent deep dive comparing Claude Opus 4.7 and Moonshot’s Kimi K2.6, the frontier of AI is fiercely competitive right now. While Opus 4.7 and Kimi K2.6 brought massive leaps in their own rights, GPT-5.5 introduces a new class of autonomous capability that specifically targets professional, high-stakes workflows where fewer retries and higher reliability directly translate to better outcomes.
GPT-5.5 is definitely crushing a wide range of benchmarks, which fits with our experience testing the model in Kilo Code and KiloClaw. Significantly, it topped the Artificial Analysis Intelligence Index by 3 points, breaking a three-way tie with Anthropic and Google.
In our testing, GPT-5.5 did have some issues with UI-related design tasks, but we found that more specific instructions helped resolve some of those problems.
So which one should you use?
GPT-5.5 is priced higher than GPT-5.4, reflecting its heavy-duty reasoning capabilities. And with this new model OpenAI did push up pricing again.
In fact, GPT-5.5 ($5 / Mtok input, $30 / Mtok output, $0.50 / Mtok cache) is more approachable than it might look from the outside. The 5.5 series is more token efficient than 5.4. For hard tasks, this efficiency often results in a lower actual cost per completed task because the model gets it right on the first try, without needing endless prompt engineering or loop retries.
GPT-5.5 often reaches higher-quality outputs with fewer retries, so it can be more token-efficient on real workflows even when reasoning is higher. And good news for Kilo Coders: it’s the most token efficient at coding workflows.
We would also like to echo OpenAI’s own advice here: “Higher reasoning can use more tokens, so customers should match reasoning effort to the task”.
In-memory prompt caching is not supported for GPT-5.5. Caching for this model relies exclusively on extended prompt caching. During inference, the model caches tokens from previous requests directly on GPU-local storage.
Does it Claw?
We’re excited to see what Kilo users around the world do with it. Like the new Opus, it’s super smart. But is it too smart for daily tasks? Or will it become your daily driver?
My prediction is that GPT-5.5 will compete more directly with the latest Opus release for coding, but be more of a top-agent driver in Hermes and OpenClaw workflows like KiloClaw: sub-agents will likely need to use smaller models or OSS models to remain cost-efficient.
That said, the only way to really know what to do with these new OpenAI models is to try them yourselves. Give them a spin in Kilo and let us know your thoughts!
Real world task performance inside Kilo would be more interesting to read...