
We Gave Claude Opus 4.7 and Kimi K2.6 the Same Workflow Orchestration Spec

Kimi K2.6 launched on April 20, 2026, four days after Anthropic released Claude Opus 4.7. We gave both models the same spec for FlowGraph, a persistent workflow orchestration API with DAG validation, atomic worker claims, lease expiry recovery, pause/resume/cancel, and SSE event streaming. Then we reviewed the code and reproduced the edge cases the models’ own tests did not cover.
TL;DR: Claude Opus 4.7 scored 91/100 and Kimi K2.6 scored 68/100 on the same build. Kimi K2.6 reached 75% of Claude Opus’s score at 19% of the cost, but the 25-point gap sits in lease handling, scheduling, and live streaming (the parts its own tests never exercised).
Pricing

Claude Opus 4.7 runs at roughly 5x the input cost and 6x the output cost of Kimi K2.6. That is the gap we wanted to pressure-test.
Why a Workflow Orchestration Spec
A workflow engine runs jobs like a nightly settlement: fetch captured payments, charge customers, send receipts, publish analytics. Four steps with dependencies between them, retries when a step fails, and recovery when a worker crashes mid-step. Temporal, Airflow, and AWS Step Functions all solve the same problem at different scales.
Most of our API comparisons test a wide range of skills (architecture, auth, filtering, error handling). For this test we wanted a single deep build where correctness was the main axis. A workflow engine with DAG validation, atomic step claims, lease expiry recovery, retry scheduling, and pause/resume/cancel semantics has objectively right and wrong answers. Either two workers can win the same step or they can’t. Either an expired lease is recovered or it isn’t. Either a step becomes runnable when its dependencies succeed or it doesn’t.
The spec also calls out at-least-once execution, deterministic scheduling across all eligible steps, and SQLite as the source of truth. The full spec is 1,042 lines and covers 20 endpoints across workflow definitions, runs, workers, events, health, and metrics.
The Prompt
We ran both tests in Kilo CLI and gave both models the same prompt:
“Read @SPEC.md and build the project in the current directory. Treat @SPEC.md as the source of truth. Do not simplify this into a mock, toy app, or basic CRUD scaffold. Create all code, configuration, Prisma schema, tests, and README needed for a runnable project. Work autonomously and continue until the implementation is complete. Before you finish, install dependencies, run the test suite, fix any failures you can reproduce, and make sure the project is runnable.”
Claude Opus 4.7 ran on high thinking mode. Kimi K2.6 ran on thinking mode. Each model worked in its own empty directory with no shared state.
What Each Model Produced

Claude Opus 4.7 finished in about 20 minutes. Kimi K2.6 took longer on the clock, but we are not scoring elapsed time here. Kimi K2.6 was released the day of this test and provider availability is still limited. Wall-clock comparisons against a model as well-supported as Claude Opus 4.7 would distort the picture. Expect that gap to close as more providers host Kimi K2.6.
Both models delivered the project shape we asked for:
Prisma with SQLite as the source of truth
Hono routes for workflow definitions, runs, worker actions, events, health, and metrics
Conditional
updateManyfor step claimingRetry and lease-expiry scheduling
A
RunEventtable for audit logsReadmes with setup instructions and at-least-once execution notes
Both Models Said Their Tests Passed
Claude Opus 4.7 ran 31 tests across 6 files. Every test passed. Kimi K2.6 ran 20 tests inside a single file. Every test passed.
If we had stopped there, the two implementations would look close. They weren’t. A direct code review plus targeted reproductions against isolated SQLite databases surfaced one real bug in Claude Opus 4.7 and six in Kimi K2.6. We will show each one with the line that causes it.
Claude Opus 4.7: One Real Bug
Multi-expired lease recovery leaves retryable siblings on a failed run
The spec says that when a step exhausts retries, the parent run fails and every other non-terminal step becomes blocked. Claude Opus 4.7’s recovery path handles this correctly for a single expired lease. With two expired leases in the same recovery pass, it can undo its own block.
In src/services/workers.ts, runRecovery() loads every expired running step into memory and iterates:

If the first iteration exhausts retries for one step, failRunDueToDeadStep() fires, the run becomes failed, and every other non-succeeded step is set to blocked. That is correct.
The problem is the second iteration. handleLeaseExpiry() updates by id only:

There is no guard on status, so a step that was just marked blocked by the prior failure cascade gets updated back to waiting_retry.
We reproduced it with a run containing two expired running steps: a with maxAttempts = 1 and b with maxAttempts = 2. After recovery:

Step b should have been blocked because the run had already failed. Instead it is eligible to be claimed again on the next /workers/claim call.
Claude Opus 4.7’s test suite does not cover this case. It tests single-step lease expiry in isolation.
Smaller contract risks
Two smaller issues turned up in review but did not need a full reproduction.
The claim path reads
maxClaims * 10candidates. That is fine most of the time, but a queue with many skipped candidates at the front can hide valid work farther down the ordered list.The SSE stream subscribes after replay finishes and treats an unknown
afterEventIdas “replay everything.” The spec does not define unknown-cursor behavior explicitly, so this is more a looseness than a bug.
Kimi K2.6: Six Confirmed Issues
1. Claim ordering is not global across runs
The spec requires that when multiple steps are eligible, claim order is priority descending, then availableAt ascending, then createdAt ascending, across all eligible steps.
Kimi K2.6’s claim loop orders steps inside each run, then iterates runs in whatever order the database returns them:
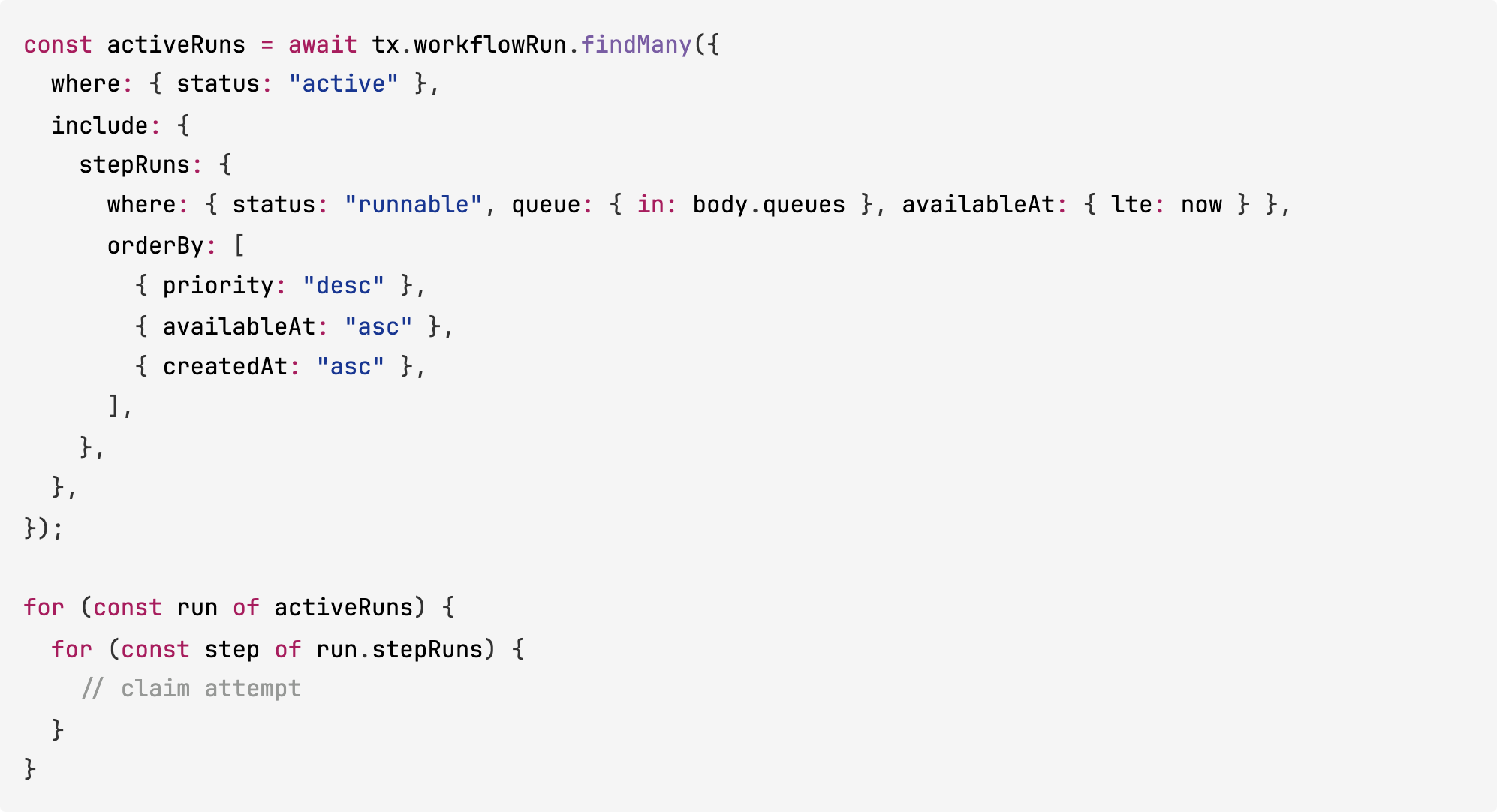
We reproduced this with two active runs on the same queue. One had a step at priority = 10. The other had a step at priority = 100. The call to POST /workers/claim returned the priority 10 step first.
2. SSE is replay-only, not live
The spec requires that GET /runs/:id/events/stream replays stored events and then switches to live streaming.
Kimi K2.6’s stream reads every persisted event, writes them to the stream, and then starts a keepalive timer. Nothing subscribes to new events. The file src/lib/events.ts even defines an emitAndBroadcast function and a subscriber map, but the route never wires to them:
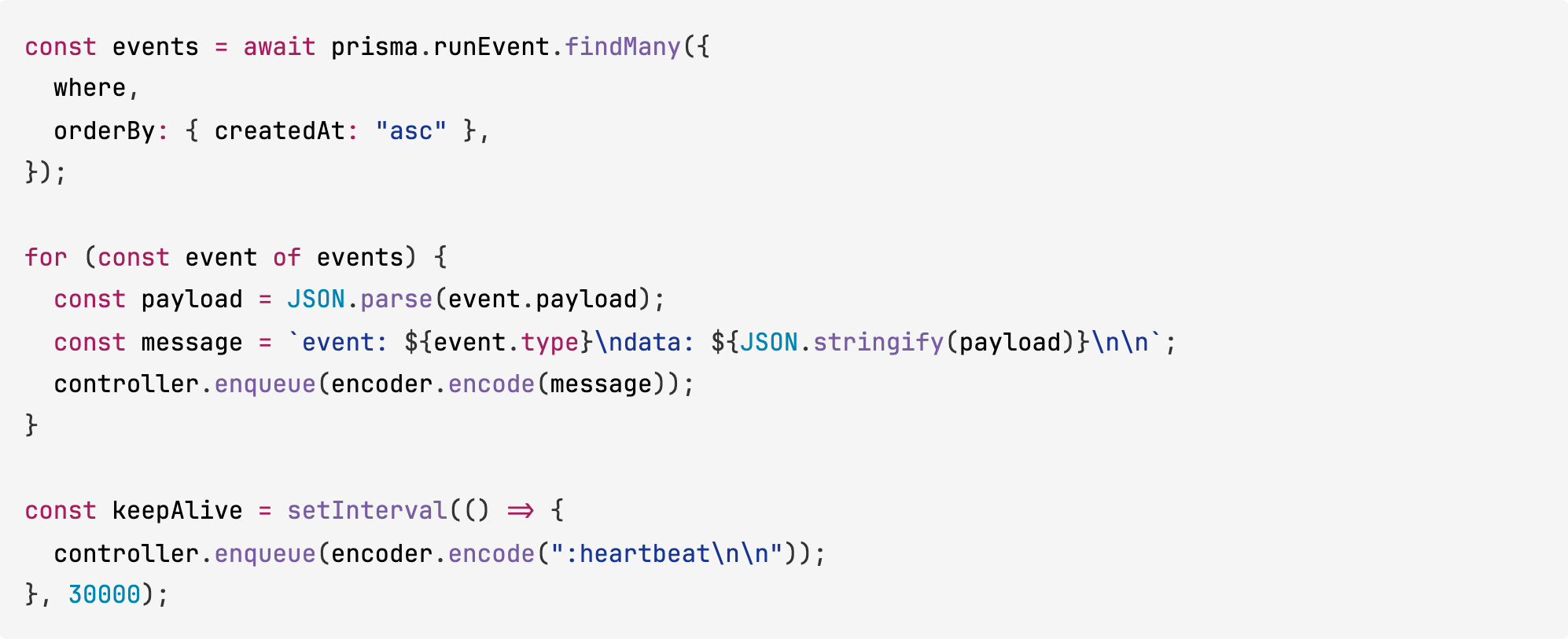
Clients receive replayed history once, then silence. The README still claims live streaming.
3. Expired leases can still be completed
The heartbeat endpoint rejects expired leases. The complete and fail endpoints do not. We reproduced this by claiming a step, forcing leaseExpiresAt into the past, and calling POST /step-runs/:id/complete:

The step was marked succeeded on an expired lease. The spec treats lease expiry as a failed attempt. A worker can crash, its lease can expire, recovery can schedule a retry for the next worker, and the original worker can still phone in a “success” afterwards.
4. “No active version” returns 404 instead of 409
The spec:
if there is no active version and no explicit
version, return409
Kimi K2.6 raises NOT_FOUND (404):

5. Validation is narrower than the spec
CreateRunSchema and CompleteSchema use z.record(z.any()) for input, metadata, and output. The spec allows arbitrary JSON payloads. A string, array, or number payload is rejected even though the spec accepts it.
6. The clean build path fails
npm test passes. npm run build does not:

package.json expects npm start to run node dist/index.js, so the documented build-and-start flow is broken on a clean checkout.
What Each Model Said About Itself
Both models produced end-of-run summaries claiming their implementations were complete and all tests passed. Both were technically true. Neither flagged the issues above.
Claude Opus 4.7’s summary was mostly accurate. It described its recovery path, atomic claim pattern, and event persistence correctly. The one thing it missed was the multi-expired lease interaction.
Kimi K2.6’s summary claimed deterministic global scheduling and live SSE streaming. Both of those claims are in the README too. The code does not deliver either.
“My tests pass” is not the same thing as “my implementation is correct.” Both models understood the spec well enough to build most of it. Neither model wrote tests that would have caught its own worst behavior.
Scoring
We scored each model on the spec, weighted by how much each category mattered for a correctness-first workflow engine
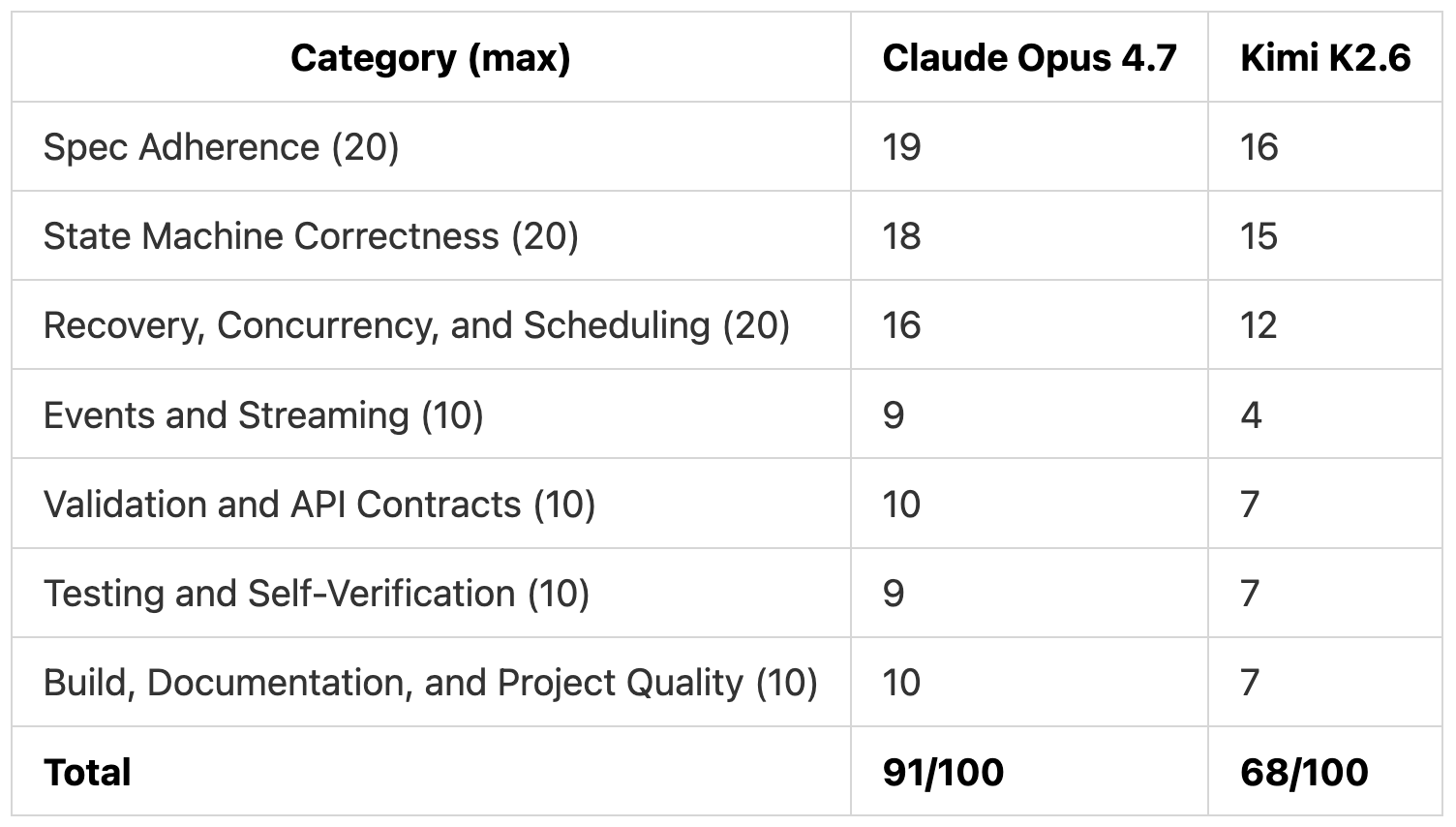
Claude Opus 4.7 lost points on the reproduced recovery bug, the bounded claim scan, and the SSE cursor fallback.
Kimi K2.6 lost points on the six confirmed issues above. The biggest hits are in recovery, scheduling, and streaming, which is exactly where the spec’s hardest requirements live.
Cost vs Quality
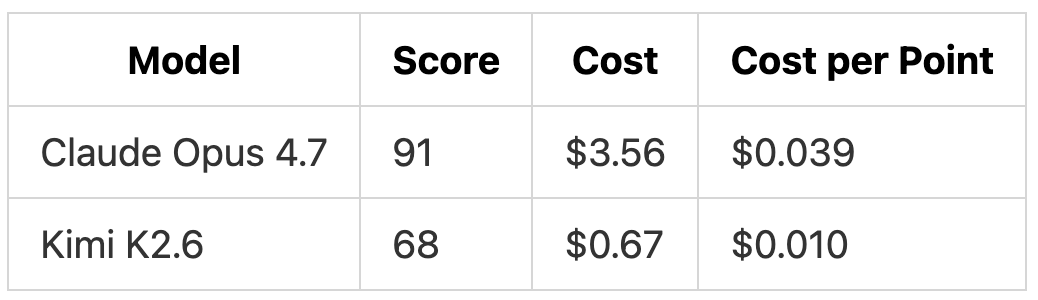
Kimi K2.6 is about 4x cheaper per point. The missing 23 points are in step-leasing, scheduling, and event streaming, which is where the hardest spec requirements live. Those are the parts that separate “the endpoints exist” from “the system behaves correctly under load.”
Where Open-Weight Models Stand Right Now
This test sits inside a pattern we’ve been tracking for a while. MiniMax M2.7 matched Claude Opus 4.6’s detection rate on our last three-part benchmark. GLM-5.1 scored five points behind Claude Opus 4.6 on our job queue spec. Kimi K2.6 landed 23 points behind Claude Opus 4.7 here on a harder spec, but still produced the right shape of the system on the first pass.
The gap on surface coverage has narrowed meaningfully over the last year. The gap on correctness inside hard code paths (lease recovery, cross-run scheduling, streaming semantics) is still there. For work where the bugs only show up under contention or mid-crash, frontier proprietary models are the safer choice today. For work where you need the scaffold, the tables, the endpoint surface, and a starting test suite, open-weight models like Kimi K2.6 are close enough that the price delta matters.
Kimi K2.6’s current pricing ($0.95 / $4 per million tokens) is a starting point, not a floor. Moonshot AI releases open weights, which means Kimi K2.6 will end up hosted on multiple providers, with pricing and latency converging on whoever runs it most efficiently. That is already playing out with MiniMax M2.5, which became the #1 most-used model across every mode in Kilo Code in the months after release. Price competition tends to pull these numbers down further as more hosts come online.
Being open-weight also means you can self-host or fine-tune Kimi K2.6 if you have data residency requirements, custom workflows, or a cost profile that makes API-only models impractical at scale. That is not a capability Claude Opus 4.7 offers at any price.
None of that changes the correctness findings above. It does reframe them. At $0.67 with a careful review pass, Kimi K2.6 is a real option now. At $3.56 with fewer corrections needed, Claude Opus 4.7 is the safer call. Which trade-off wins depends on the work. A year ago, that choice did not really exist at this level of complexity.
Takeaways
For building the scaffold of a complex backend: Kimi K2.6 did well. It produced the right project shape, the right tables, the right endpoint surface, and a test suite that passed. For prototyping, exploring a design, or generating a starting point you plan to review carefully, the $0.67 run is a good deal.
For systems where state-machine correctness matters: Claude Opus 4.7 pulled clearly ahead. The two implementations look similar in shape but diverge in the code paths that are hard to test casually (lease expiry, cross-run ordering, SSE, expired-lease rejection). If the project needs to behave correctly when leases expire, when multiple runs compete for workers, or when events need to flow live to clients, Claude Opus 4.7’s output is closer to something you could ship.
On trusting model self-reports: Both models said they were done. One was mostly right. The other had six spec-level issues in shipped code. “Tests pass” is a necessary signal. It is not a sufficient one for work this correctness-sensitive. A review pass plus a few targeted reproductions closed the gap between what the models said and what they actually built.
A Note on Kimi K2.6 Speed
Kimi K2.6 was released the day of this test. Provider availability is limited right now, so the current wall-clock timings understate the model’s real speed. We saw similar adoption curves on previous open-weight releases from MiniMax and Z.ai as more providers came online. We expect Kimi K2.6’s elapsed time (and its effective cost) to keep dropping as that happens.
Testing performed using Kilo Code, a free open-source AI coding assistant for VS Code and JetBrains with 2,300,000+ Kilo Coders.
Great writeup. Any chance you could share the SPEC.md? Would love to reproduce on a few other models.
I use Kimi 2.5 on Nvidia's Developer program - which means FREE API access.
I assume 2.6 will be available there at some point.
Something to keep in mind.