
Benchmarking the Benchmarks: New GPT and Claude Releases Continue to One-Up Themselves
With Anthropic and OpenAI releasing new models at lightning speed, is it time for a new definition of a SOTA model?

Last month, the biggest simultaneous model drop in AI history proved that no single model wins everything. Claude Opus 4.6 and GPT-5.3-Codex came out of the gate neck and neck. Then Anthropic and OpenAI followed up with arguably even more significant releases within their own portfolios: Sonnet 4.6 and GPT-5.4.
When OpenAI released GPT-5.4 yesterday, it was instantly live in Kilo Code—but has everybody even had a chance to test the new Codex in depth yet?
These models are the bar against which other labs compare themselves (“Opus-like reasoning”, “as good as GPT at web search”) but they’re constantly improving too. Is the speed of AI development outpacing its own benchmarks? How should we measure success?
February Magic
The first week of February was one for the history books. Within minutes of each other, Anthropic launched Claude Opus 4.6 and OpenAI fired back with GPT-5.3-Codex. Two frontier models from the two biggest labs in AI, dropped within minutes of each other, each claiming the crown for agentic coding.
The timing was almost certainly not a coincidence. And we also had the “Chinese OSS models” including Kimi K2.5, MiniMax M2.5 and GLM-5 — but not the rumored DeepSeek V4—going live in the prior two weeks. (We call them just open-weight models.)
But Anthropic and OpenAI were almost one-upping themselves — less than two weeks later, Anthropic released Sonnet 4.6, a remarkable powerhouse that pulls in more reasoning than ever before, and yesterday OpenAI shocked the industry with the release of GPT 5.4.
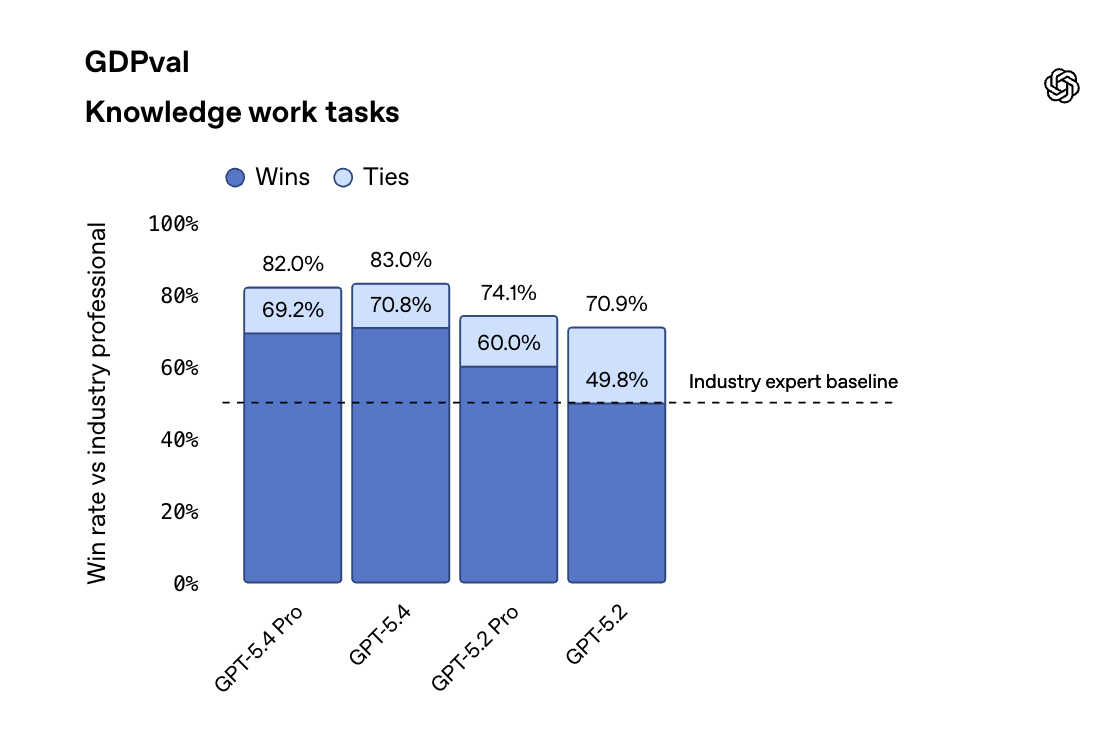
With customers including Cisco, Lowe’s and Morgan Stanley, OpenAI has over 1 million business customers around the world, and their ChatGPT Enterprise seats have grown at a staggering 9x year-over-year. It’s no surprise that on GDPval benchmarks for “knowledge world tasks,” GPT-5.4 is excelling particularly at professional queries and workflows. The model continues OpenAI’s focus on general, robust models for professional work.
Yet when it comes to Opus vs Codex, or just generally Claude models vs GPT models, the thing nobody in the breathless benchmark wars is saying loudly enough: neither model—neither lab—wins everything.
This is definitely true for strategic customer wins: The number of customers spending over $100,000 annually on Claude has grown 7x in the past year (as Anthropic shared when announcing their $30B funding round last month).
And when you zoom out beyond the headline battle, the landscape gets even more interesting — because some of the most compelling models for real day-to-day development work aren’t coming from the big two at all. Or not from just their flagship heavyweights.
Let’s break down what happened and what it means for you.
The Launches
Claude Opus 4.6 arrived with a set of capabilities that push Anthropic’s lead in reasoning and deep code understanding even further:
1M token context window (beta) — load entire large codebases into a single session
Adaptive thinking — the model dynamically allocates reasoning effort based on problem complexity, replacing the old fixed “extended thinking” budget
128K max output tokens — double the previous Opus ceiling
Agent Teams (preview) — multiple Claude instances collaborating in parallel on tasks like code review, testing, and documentation
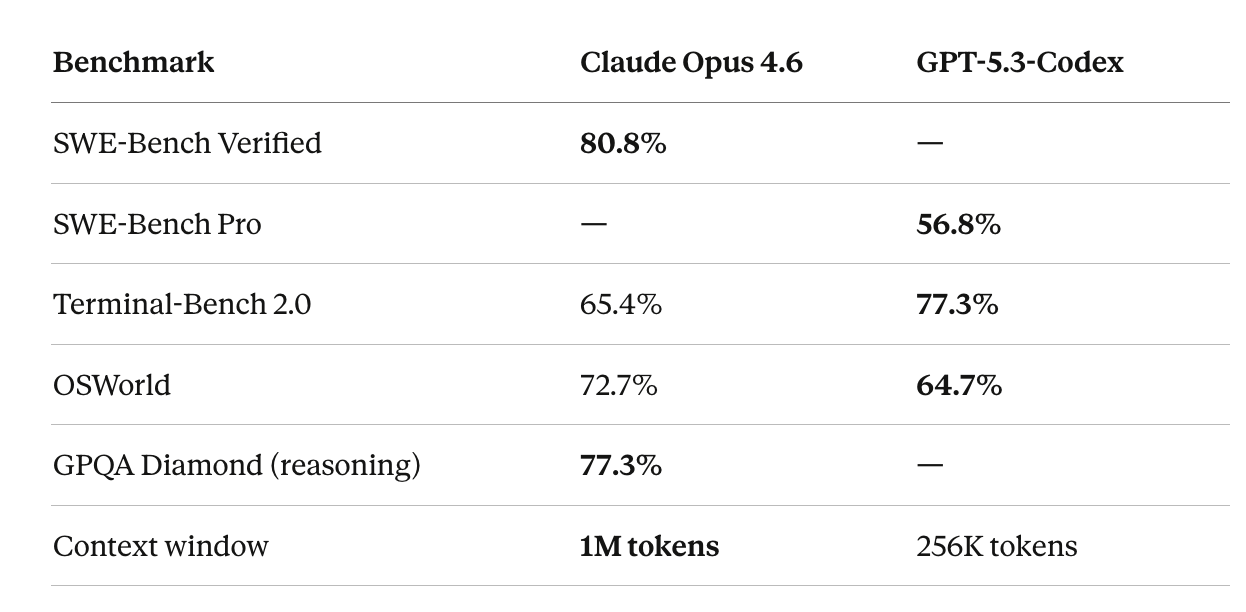
80.8% on SWE-Bench Verified — the highest score on real-world bug-fixing evaluations
65.4% on Terminal-Bench 2.0 — a new high for Anthropic, and briefly the overall leaderboard leader… for about thirty minutes
GPT-5.3-Codex landed with a different philosophy — speed, execution, and raw agentic throughput:
25% faster inference than GPT-5.2-Codex, with fewer tokens consumed per task
77.3% on Terminal-Bench 2.0 — a massive 13-point leap over GPT-5.2, immediately reclaiming the top spot from Opus 4.6
56.8% on SWE-Bench Pro — state-of-the-art on this multi-language, contamination-resistant benchmark
64.7% on OSWorld — computer-use tasks in real desktop environments, up from 38.2% in the previous generation
Interactive steering — you can redirect the model mid-task without losing context
Self-developing milestone — OpenAI says early versions of GPT-5.3-Codex helped debug its own training and manage its own deployment
Both models are extraordinary. And they are extraordinarily different. Like senior executives, they have different strengths and different personalities.
Then came Sonnet 4.6 and GPT-5.4, even more different in some ways, similar in the focus on highly efficient reasoning.
Sonnet 4.6 is a powerhouse of superpowered efficiency. It hits 79.6% on SWE-bench Verified for coding and 72.5% on OSWorld-Verified for computer use.
And GPT-5.4 is a major leap forward for general use cases. It is especially good at web search (Standard GPT-5.4 hitting 82.7% on BrowseComp, with GPT-5.4 Pro scoring an impressive 89.3%), which is becoming increasingly important for deep agentic work such as KiloClaw use cases.
He Said, She Said (or Selective Benchmark Hearing)
With Opus 4.6 and GPT 5.3 Codex, the benchmark comparison tells a clear story — not of one model dominating, but of two models excelling in different dimensions.
True to form, Anthropic didn’t just compare against their own models but against all the major frontier labs. Their official announcement of Opus 4.6 surveyed the entire industry, comparing Anthropic models against Google Gemini and OpenAI Codex models.

And in their official announcement of GPT 5.3 Codex, OpenAI came in hot (or cold?) with a comparison against only their own models, aiming to show a significant leap forward in agentic coding performance.
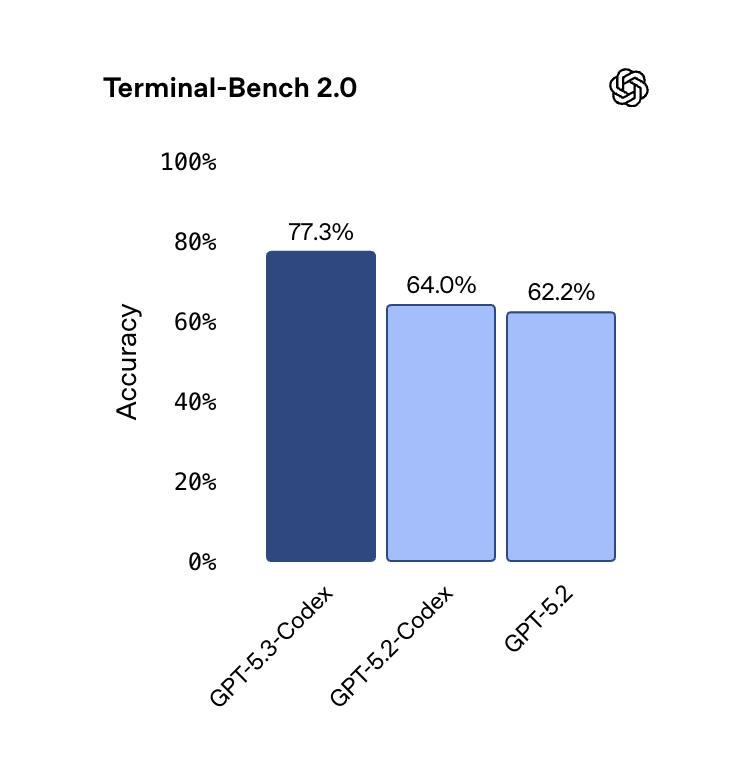
But look at those side by side and it starts to feel like selective hearing. The two companies reported on different SWE-Bench variants, making direct comparison on that metric difficult.
As you can see on Kilo’s leaderboard, open-weight models and new releases from relatively small players are also on the playing field here. With new powerhouses like Kimi K2.5 and GLM-5, the landscape becomes even more fractal.
Some are criticizing these labs and releases for selectively highlighting benchmarks favorable to their strengths. But I think it’s a bigger story, which is about focusing on benchmarks and types of tasks where a model really excels and then training (and increasingly using more effective RL) to improve in those areas. This often creates a halo effect with improvements in other areas as well, for examples improvements in reasoning that amplify multi-agent capabilities.
The pattern emerging from early real-world testing aligns with what the benchmarks suggest:
Opus 4.6 is the staff engineer who reads the entire repo before touching a line of code. It excels at deep codebase understanding, complex refactors, multi-file architectural reasoning, security audits, and sustained long-context work. If you’re debugging a race condition that spans six microservices, or reviewing a 20,000-line codebase for vulnerabilities, Opus 4.6 is the model that catches what others miss.
GPT-5.3-Codex is the senior developer who starts running commands immediately. It’s optimized for speed, iteration, and tool-heavy workflows — terminal operations, rapid prototyping, multi-file edits, and long-running agentic loops where execution throughput matters more than deliberation depth. If you need fast, focused fixes or want an agent that can autonomously iterate on a project across multiple sessions, Codex shines.
Both are phenomenal. Neither replaces the other.
How will GPT-5.4 stack up? It’s too early to say, but our pre-testing of OpenAI’s latest model revealed results in line with the story so far:
GPT-5.4 tended to finish tasks ~15% more quickly than other top frontier models, and—significantly—did not end up overanalyzing solutions, instead starting to work on iterating its way to a solution and avoiding unproductive logic loops.
But compared against 5.3-Codex, GPT-5.4 (with medium thinking) wasn’t always the clear winner. Codex’s advantage comes partly from a willingness to engage with adversarial/security tasks, and from superior algorithmic reasoning on complex encoding and optimization problems. On the other hand, GPT-5.4 excels at tasks requiring careful requirement parsing and web research.
GPT-5.3-Codex tends to fail by being overconfident and insufficiently careful—it builds quick solutions that pass the development test but break on hidden validation data—while GPT-5.4’s signature failure (a personality flaw?) is the opposite: the “last-mile problem,” where it correctly understands and plans the task but halts before executing the critical final action.
Yet this is starting to feel like nitpicking.
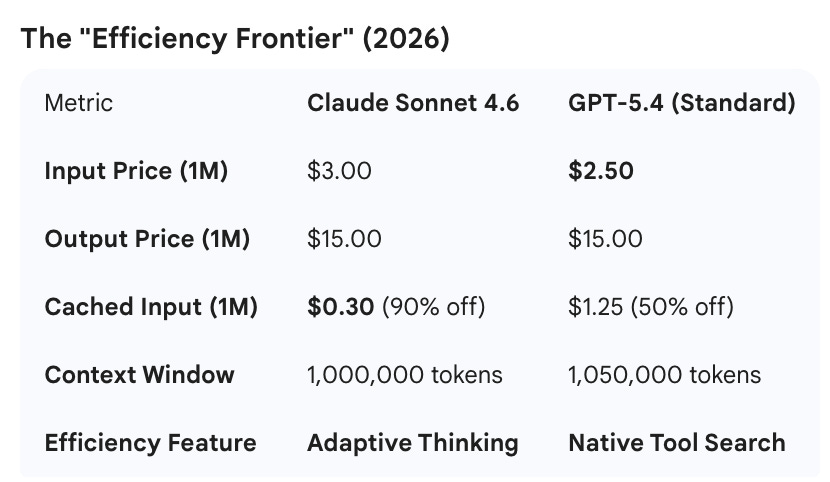
We’ve seen an increase of around 40% cost savings for Anthropic model devotees with the new Sonnet (it has “Opus-like” reasoning now). Will we see the same with OpenAI? At $2.50/1M tokens, GPT-5.4 is currently the most affordable “frontier-class” flagship, but note that for prompts over 272K tokens, GPT-5.4’s input rate doubles to $5.00.
These are all powerful models, and they help validate our approach to model freedom at Kilo. The era of picking one model and sticking with it is over, and the big frontier labs are only part of the story.
New trends we’re already seeing:
Using GPT models to generate powerful prompts for Sonnet
Using Opus to plan a big project, then implementing that project with smaller OSS models
Logging in with your coding plan subscription to get some local work done, then using a model like Moonshot AI’s Kimi K2.5 to get serious work done with Cloud Agents
You can try all of the models mentioned in this post in Kilo, along with hundreds of others. Find out what works for your daily workflows.
And stay tuned for more on our own internal testing. Something big is coming :)
Benchmarks are benchmarks. What we really need right now is an evaluation of GPT 5.4, Opus 4.6 and Sonnet 4.6 doing the same array of real-world tasks so we can see the difference :)
Hey Kilo Team, This is just amazzzzzing, I always wait for the Kilo benchmarks they are the best, Please continue the same, especially for the Frontier models