
GPT-5.3-Codex is Live in Kilo
The best of OpenAI worlds, in one efficient coding model

Forget everything you knew about “coding models” being specialized, terse, or limited to a terminal.
GPT-5.3-Codex was recently made available for developers in OpenAI’s Responses API, and it was live in Kilo within minutes. OpenAI announced the model back on February 5th, and we were lucky to have early access for testing in Kilo—but our users have actually already been trying it out in Kilo, too, with their ChatGPT login.

This is a real paradigm shift. Compared to prior Codex models, it’s more token-efficient and approximately 25% faster. It feels like OpenAI unified two of its most powerful research tracks: the frontier code generation of the Codex line and the elite professional reasoning of the GPT-5.2 “Thinking” series.
5.3 Codex brings a unified set of capabilities:
Faster and more token efficient
Higher intelligence and long-running autonomy
Strong compaction support
The result? A model that doesn’t just write functions—it builds systems, manages deployments, and writes code with the same level of logical density. 5.3 Codex is quickly rising up our leaderboard.
The Leap: Unifying Reasoning and Execution
For the past year, developers have been forced to choose: use a “reasoning” model (like GPT-5.2) for high-level system design, or a “coding” model (like Codex 5.2) for raw implementation.
GPT-5.3 Codex eliminates that friction. It is the first model OpenAI describes as “instrumental in creating itself,” having been used by their own engineers to debug training runs and optimize the very Blackwell (GB200) clusters it runs on.
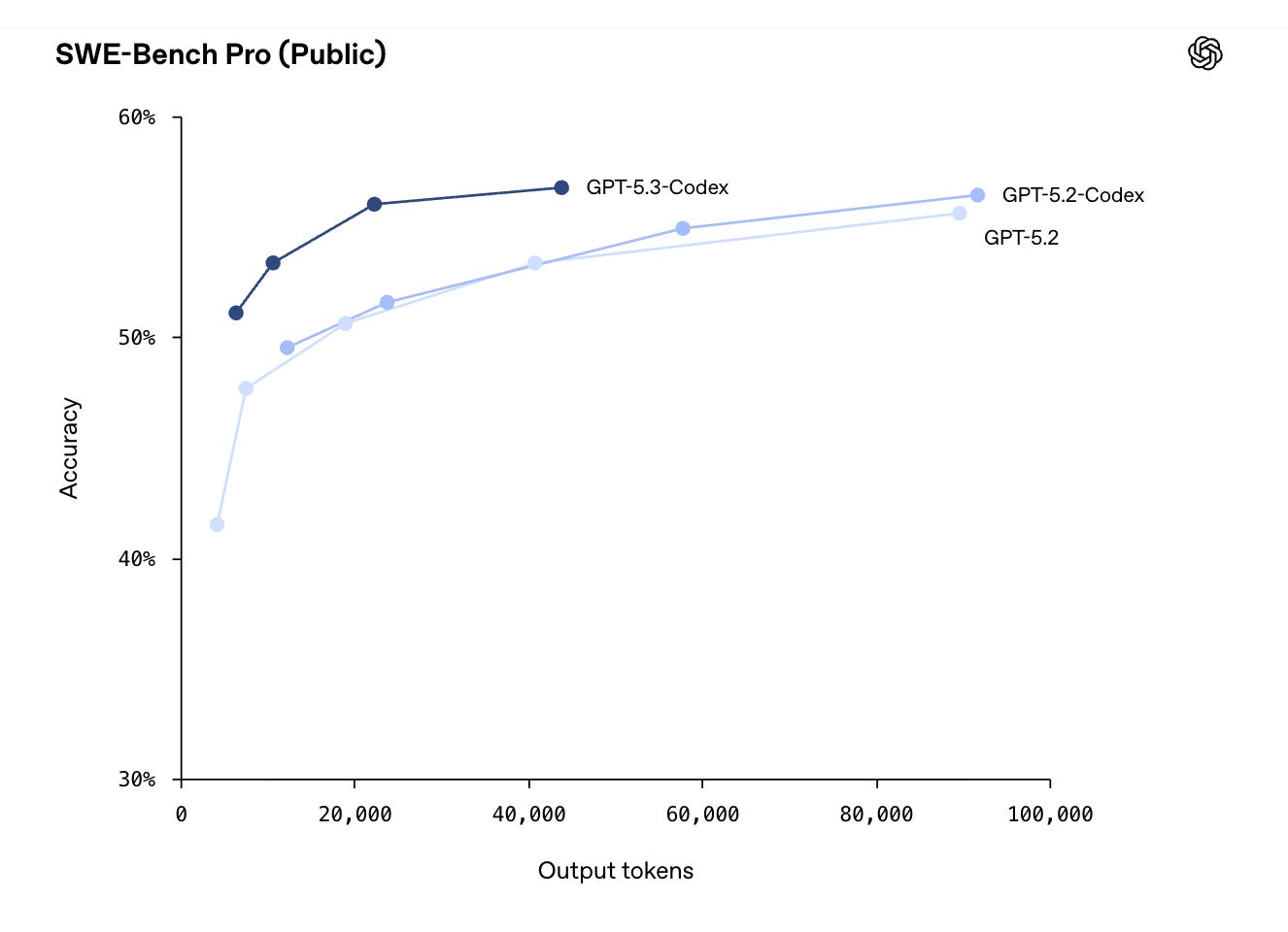
Key Benchmark Wins — Even if You Question the Benchmarks
Earlier this week OpenAI wrote that SWE-bench Verified no longer measures frontier coding capabilities. Along those lines, they didn’t even publish SWE-bench Verified results for the new model, and instead focused particularly on SWE-Bench Pro, writing in the official announcement that “SWE‑bench Verified only tests Python, [while] SWE‑Bench Pro spans four languages and is more contamination‑resistant, challenging, diverse and industry-relevant.”
GPT-5.3-Codex’s benchmark results are impressive and an indicator of even more to come from frontier models:
Terminal-Bench 2.0: 77.3% (A massive jump from 64% in V5.2). This measures real-world terminal operations—running commands, interpreting errors, and iterating.
SWE-Bench Pro: 56.8%. It currently edges out Gemini 3.1 Pro (54.2%) and matches the latest Claude 4.6 in practical software engineering tasks.
OSWorld-Verified: 64.7%. This benchmark tests the model’s ability to use a computer like a human (GUI, mouse, keyboard). Codex is no longer just a text box; it’s an agent that understands the desktop environment.
GDPval (Knowledge Work): 70.9% wins or ties across 44 professional occupations, proving it is as capable at creating spreadsheets and presentations as it is at writing Python.
These aren’t abstract benchmarks. Early testing in Kilo revealed that the new model really is as capable and affordable as the benchmarks suggest.
Two Ways to Power Your Kilo Workflow
We’ve integrated GPT-5.3 Codex to be as flexible as your dev stack. You can start using it in Kilo right now via two distinct paths:
1. Kilo Gateway
Looking to use Codex in the fastest way possible across all Kilo features? Try it directly in Kilo, and check out Kilo Pass to maximize your AI output per dollar.
For teams and power users who need the full suite of Kilo Cloud features, the Kilo Gateway provides direct access to OpenAI models, including GPT-5.3 Codex. This path is optimized for our custom agentic loops, allowing Codex to run parallel sub-agents for heavy-duty tasks like full-repo refactors or CI/CD pipeline auditing while maintaining full cloud persistence.
2. Login with Codex (Bring Your Own Subscription)
Following the model we detailed in our guide to using GPT inside Kilo, you can simply use the Login with Codex button. This uses your existing OpenAI seat to power your Kilo environment.
Note: When using your personal subscription via “Login with Codex,” you are restricted to local-only features. You can’t use cloud agents or other cloud features in Kilo, but you can use GPT models extensively in your preferred IDE or our upgraded CLI.
Benchmarks and Viewpoints: The 2026 Landscape
The AI landscape this February is the most competitive we’ve ever seen. While GPT-5.3 Codex excels in execution speed and terminal competence, other models are carving out their own niches:
The Depth Leader: Claude Opus 4.6 is still widely considered the king of “long-horizon planning” and deep architectural reasoning, often providing more structured documentation than Codex.
The Logic Challenger: Gemini 3.1 Pro currently holds the top spot on the ARC-AGI-2 benchmark (77.1%), making it a formidable choice for entirely new logic patterns that haven’t appeared in training data.
The Speed Demon: For near-instant edits, OpenAI also released Codex-Spark, which delivers over 1,000 tokens per second for real-time autocomplete.
“Codex 5.3 is an excellent model, and its output is more reliable... it finally picked up some of Opus’s warmth and willingness to just do things.”
— Dan Shipper, Every Vibe Check
GPT-5.3 Codex is the first model that feels like a true colleague. It doesn’t just give you the code; it understands the work around the code.
Ready to see it in action? Open Kilo and toggle your model selector to GPT-5.3-Codex to start your first agentic session today.