
We Tested GPT-5.2/Pro vs. Opus 4.5 vs. Gemini 3 on 3 Real-World Coding Tasks

OpenAI released GPT-5.2 and GPT-5.2 Pro yesterday.
We jumped in right away to see how these two models stack up against Opus 4.5, Gemini 3, and GPT-5.1—and in true Kilo speed fashion, we’re publishing the results 24 hours after the model release.
How we tested the models
We used the same 3 tests from our previous comparison of GPT-5.1, Gemini 3.0, and Claude Opus 4.5 to see where OpenAI now stands among frontier coding models.
Prompt Adherence Test: A Python rate limiter with 10 specific requirements (exact class name, method signatures, error message format)
Code Refactoring Test: A 365-line TypeScript API handler with SQL injection vulnerabilities, mixed naming conventions, and missing security features
System Extension Test: Analyze a notification system architecture, then add an email handler that matches the existing patterns
Each test started from an empty project in Kilo Code.
We used:
Code Mode for Tests 1 and 2,
Ask Mode followed by Code Mode for Test 3.
We also set the reasoning effort to the highest available option for both GPT-5.2 and GPT-5.2 Pro.
Test #1: Python Rate Limiter
The prompt: We asked all 5 models to implement a TokenBucketLimiter class with 10 specific requirements: exact class name, specific method signatures, a particular error message format, and implementation details like using time.monotonic() and threading.Lock().
The results:

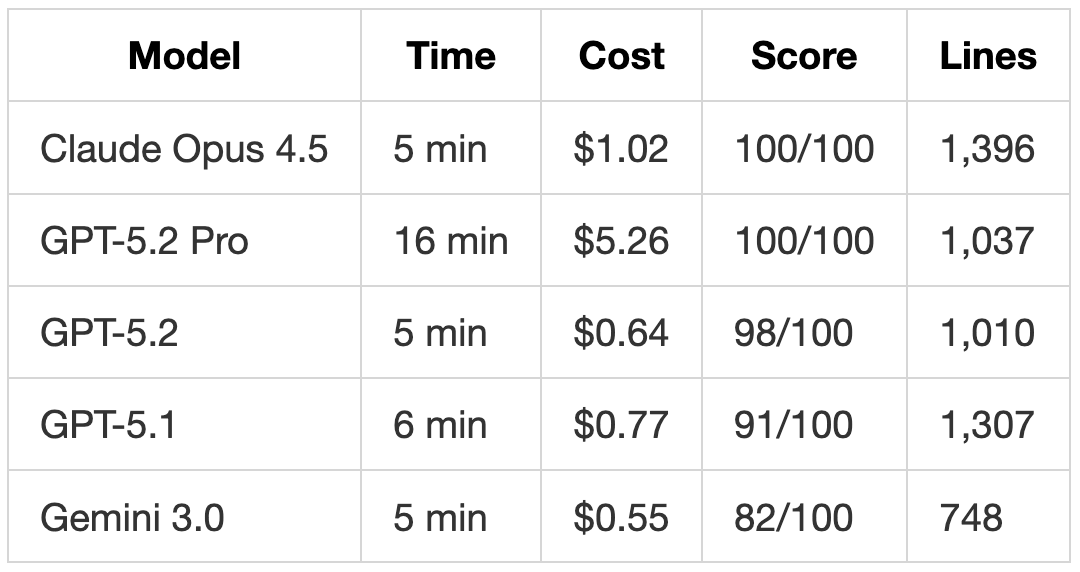
GPT-5.2 Pro was the only model to achieve a perfect score (However, the request took 7 minutes to complete.) It used the exact constructor signature specified (initial_tokens: int = None instead of Optional[int]) and named its internal variable _current_tokens to match the required dictionary key in get_stats().
GPT-5.2 improved on GPT-5.1 in one key way: it stopped throwing unnecessary exceptions. GPT-5.1 added unrequested validation that raised ValueError for non-positive tokens:

GPT-5.2 treated edge cases gracefully:

This is a meaningful change. GPT-5.1’s defensive additions could break callers who expected the method to handle zero tokens. GPT-5.2 follows the spec more closely while still handling edge cases.
GPT-5.2 Pro’s Extended Reasoning
GPT-5.2 Pro spent 7 minutes and $1.99 on a task that took other models 1-2 minutes and $0.06-$0.17. The extra time and cost produced three improvements:
Exact signature matching: It used
int = Noneinstead ofOptional[int]orint | NoneConsistent naming: It used
_current_tokensinternally, matching the required dict keyComprehensive edge cases: It handles
tokens > capacityandrefill_rate <= 0by returningmath.inf
The pros/cons:
Pros: For a rate limiter that will run millions of times, the 7-minute investment might be worth it.
Cons: For quick prototyping, GPT-5.2 at 1 minute and $0.06 is more practical.
Test #2: TypeScript API Handler Refactoring
The prompt: We provided a 365-line TypeScript API handler with 20+ SQL injection vulnerabilities, mixed naming conventions, no input validation, hardcoded secrets, and missing features like rate limiting. The task was to refactor into clean layers (Repository/Service/Controller), add Zod validation, fix security issues, and implement 10 specific requirements.

The results:
Both GPT-5.2 and GPT-5.2 Pro now implement rate limiting, which GPT-5.1 missed entirely. This was one of the 10 explicit requirements in the prompt.
GPT-5.2 Implemented Rate Limiting
GPT-5.1 ignored the rate limiting requirement. GPT-5.2 followed our instructions precisely:

GPT-5.2’s implementation includes proper Retry-After calculation and uses a factory pattern for configurability.
Claude Opus 4.5’s implementation was more complete, adding X-RateLimit-Limit, X-RateLimit-Remaining, and X-RateLimit-Reset headers plus periodic cleanup of expired entries.
GPT-5.2 skipped these extras but met the core requirement rather than ignoring it entirely like GPT-5.1 did.
GPT-5.2 Pro Requires JWT_SECRET
GPT-5.2 Pro was the only model to require the JWT secret as an environment variable, throwing an error at startup if it’s missing:

Other models either hardcoded the secret or used a fallback default:

For production code, GPT-5.2 Pro’s approach is the safest since it fails fast rather than running with an insecure default.
Code Size Comparison
GPT-5.2 produced more concise code than GPT-5.1 (1,010 lines vs 1,307 lines) while implementing more requirements. The reduction came from cleaner abstractions:

GPT-5.2 matched Opus 4.5’s feature set in 27% fewer lines.
Test #3: Notification System Extension
The prompt: We provided a 400-line notification system with Webhook and SMS handlers, and asked models to:
Explain the architecture (using Ask Mode)
Add an EmailHandler that matches the existing patterns (using Code Mode)
This test measures both comprehension and the ability to extend code while matching existing style.
The results:
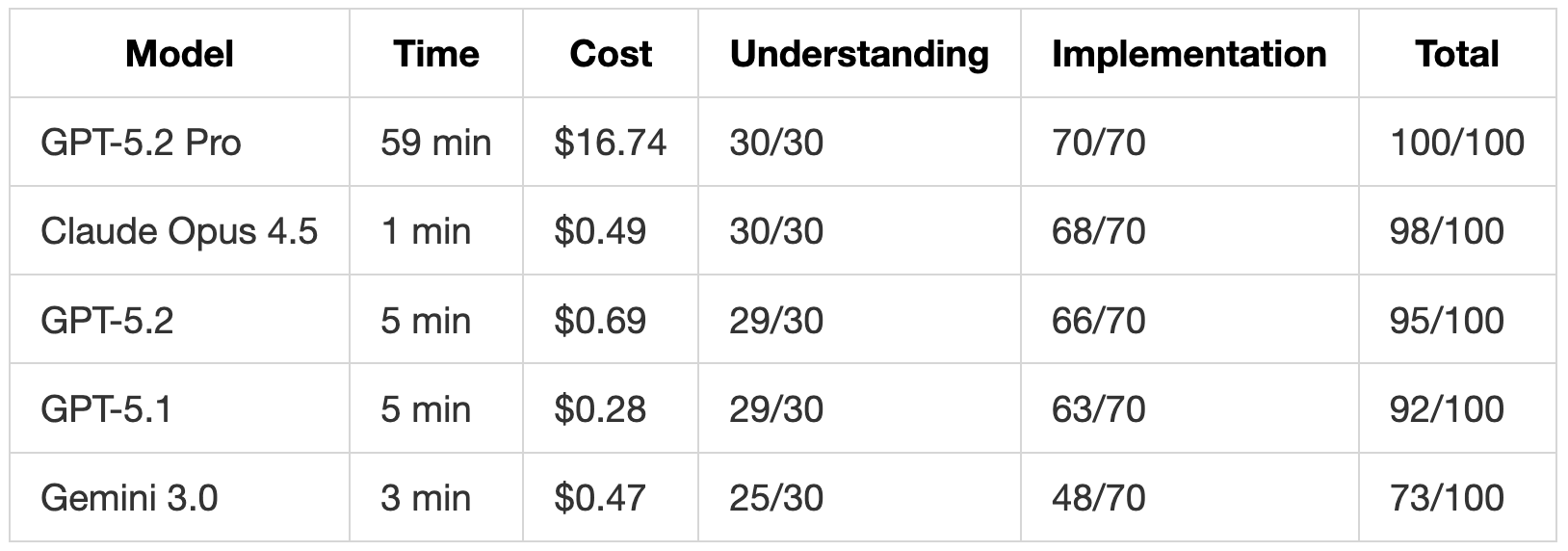
GPT-5.2 Pro achieved the first perfect score on this test. It spent 59 minutes reasoning through the problem, which is impractical for most use cases but shows what this model is capable of when given the time.

GPT-5.2 Pro Fixed Architectural Issues
In our previous tests, all models identified a fragile pattern in the original code but none fixed it. The registerHandler method used type casting to detect which channel a handler belonged to:

GPT-5.2 Pro was the first model to actually fix this. It added a getChannel() method to the base class:

And updated registerHandler to use it:

GPT-5.2 Pro also fixed two other issues no other model addressed:
Private property access: Added
getEventEmitter()method instead of usingmanager[‘eventEmitter’]Validation at registration: Calls
handler.validate()duringregisterHandler()rather than waiting until send time
These fixes show what extended reasoning can accomplish. GPT-5.2 Pro implemented the email handler and improved the overall system architecture.
GPT-5.2’s Email Implementation
GPT-5.2 produced a comprehensive email handler (1,175 lines) with full provider support:

GPT-5.2 used dynamic imports for nodemailer and @aws-sdk/client-ses, allowing the code to work without those dependencies installed until they’re actually needed. It also added normalizeEmailBodies() to generate text from HTML or vice versa:

Template Coverage

Claude Opus 4.5 remains the only model to provide templates for all 7 notification events. GPT-5.2 covered 4 events, GPT-5.2 Pro covered 3.
Performance Summary
Test Scores
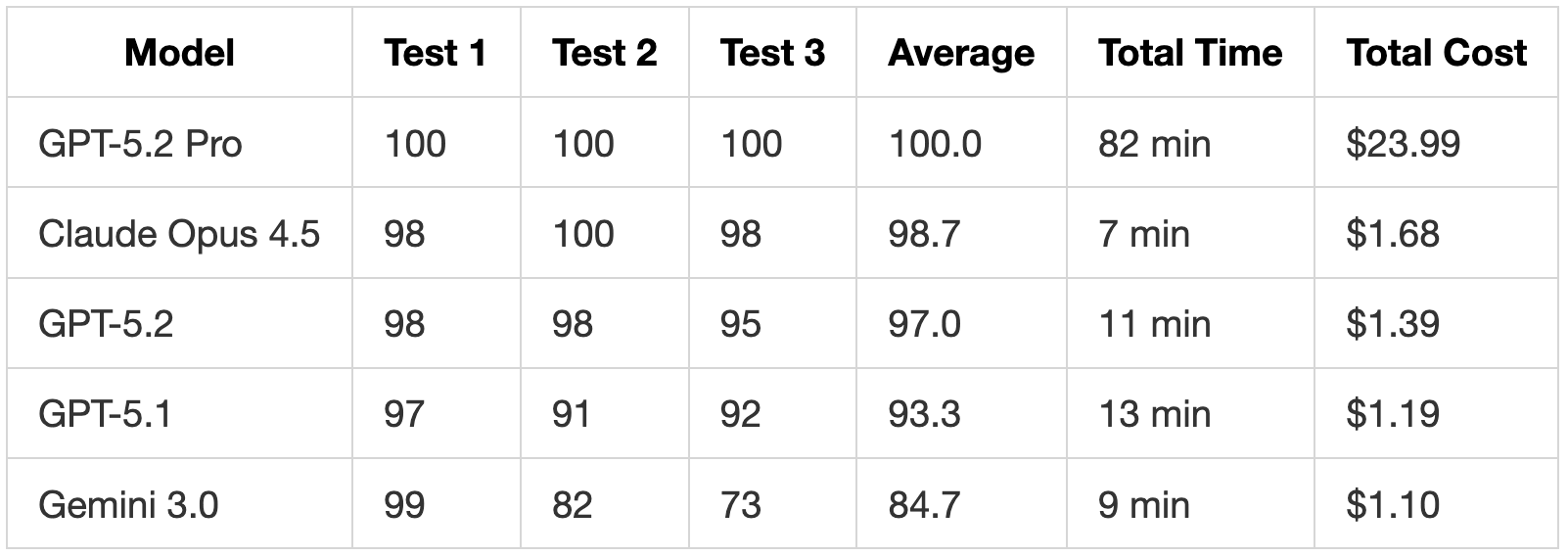
GPT-5.2 Pro achieved perfect scores but at 82 minutes total and $23.99. For comparison, Claude Opus 4.5 scored 98.7% average in 7 minutes for $1.68.
GPT-5.2 vs GPT-5.1
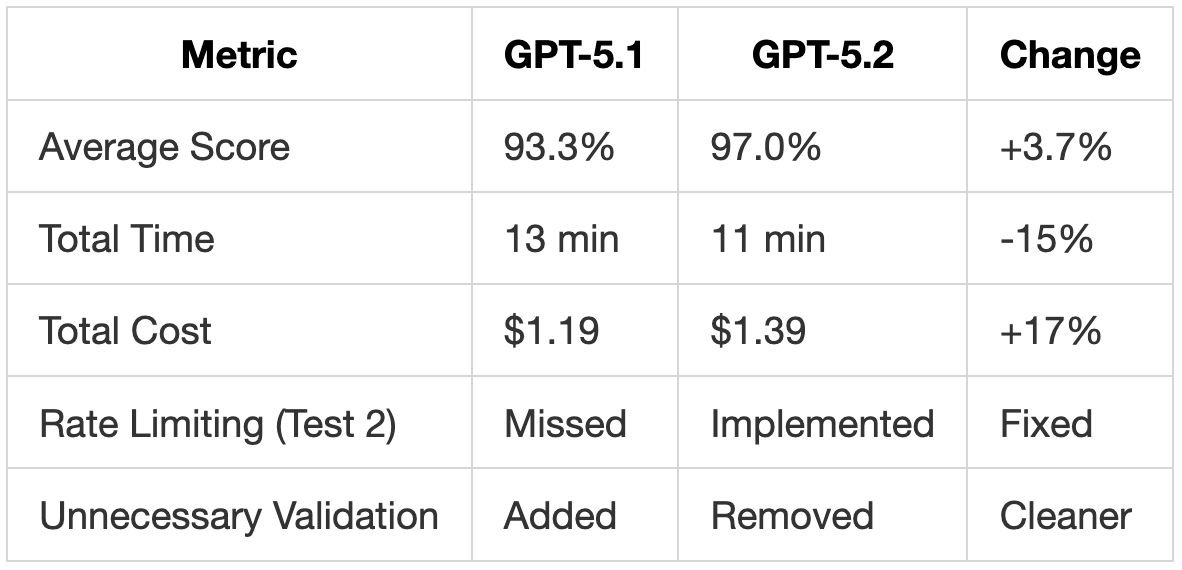
GPT-5.2 is faster, scores higher, and produces cleaner code than GPT-5.1. The 17% cost increase ($0.20 total) buys meaningful improvements in requirement coverage and code quality.
GPT-5.2 vs Claude Opus 4.5

Claude Opus 4.5 scored slightly higher across the board while completing tasks faster. The difference is most visible in Test 2, where Opus 4.5 was the only model (besides GPT-5.2 Pro) to implement all 10 requirements including rate limiting with full headers. In Test 3, Opus 4.5 provided templates for all 7 notification events while GPT-5.2 covered 4.
GPT-5.2 is 17% cheaper per run, but Opus 4.5 is more likely to deliver complete implementations on the first try. If you factor in potential retries to fill in missing features, the cost difference narrows.
GPT-5.2 vs Gemini 3.0
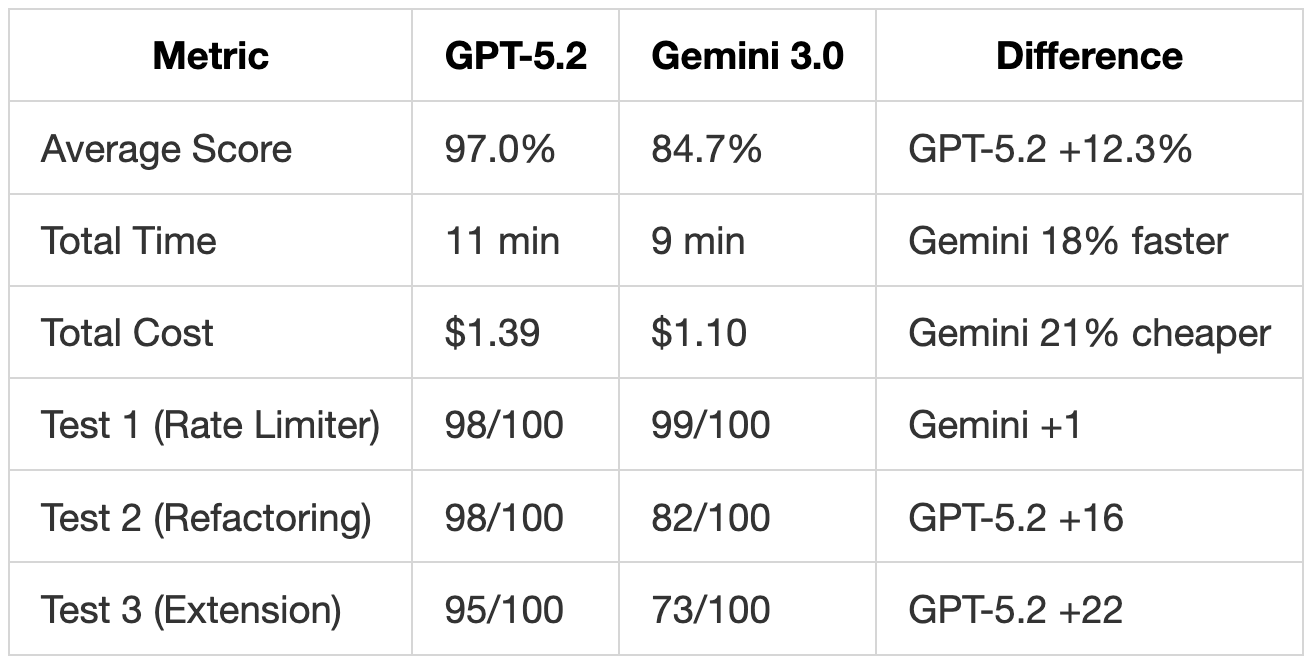
Gemini 3.0 won Test 1 by following the prompt most literally, producing the shortest code (90 lines) with exact spec compliance. But on more complex tasks (Tests 2 and 3), GPT-5.2 pulled ahead significantly. Gemini missed rate limiting entirely in Test 2, skipped database transactions, and produced a minimal email handler in Test 3 without CC/BCC support or proper recipient handling.
Gemini 3.0 is faster and cheaper, but the 12% score gap reflects real missing functionality. For simple, well-specified tasks, Gemini delivers clean results. For refactoring or extending existing systems, GPT-5.2 is more thorough.
When to Use Each Model
GPT-5.2 fits most coding tasks. It follows requirements more completely than GPT-5.1, produces cleaner code without unnecessary validation, and implements features like rate limiting that GPT-5.1 missed. The 40% price increase over GPT-5.1 is justified by the improved output quality.
GPT-5.2 Pro is useful when you need deep reasoning and have time to wait. In Test 3, it spent 59 minutes identifying and fixing architectural issues that no other model addressed. This makes sense for:
Designing critical system architecture
Auditing security-sensitive code
Tasks where correctness matters more than speed
For most day-to-day coding (quick implementations, refactoring, feature additions), GPT-5.2 or Claude Opus 4.5 are more practical choices.
Claude Opus 4.5 remains the fastest model to high scores. It completed all three tests in 7 minutes total while scoring 98.7% average. If you need thorough implementations quickly, Opus 4.5 is still the benchmark.
Practical Tips
Reviewing GPT-5.2 Code
GPT-5.2 follows requirements more literally than GPT-5.1. When reviewing:
Fewer surprises: GPT-5.2 adds less unrequested validation and defensive code, so the output is closer to what you asked for
Check completeness: GPT-5.2 implements more requirements than GPT-5.1, but still misses some that Opus 4.5 catches
Concise output: GPT-5.2 produces shorter code than GPT-5.1 for equivalent functionality, which makes reviews faster
Reviewing GPT-5.2 Pro Code
GPT-5.2 Pro reasons longer and produces more thorough code. When reviewing:
Unsolicited fixes: It may refactor or fix issues in the original code you didn’t explicitly ask about
Stricter validation: It tends to require configuration (like environment variables) rather than using fallback defaults
Time budget: Expect 10-60 minutes per task, so plan accordingly
Prompting Strategy
With GPT-5.2: Prompt similarly to GPT-5.1. If you need specific behavior, state it explicitly since GPT-5.2 won’t add as many defensive features on its own.
With GPT-5.2 Pro: Use for upfront architecture decisions or when reviewing security-critical code. The extended reasoning time pays off for tasks where getting it right the first time matters more than speed.
.
For me gpt never follow my instruction and do extra thing that I never asked, Gemini is really bad at coding still, sonnet or opus are the best option on the market now for coding.
Gpt pro should never be taken into account because it insane in price 🤪
“Fewer surprises: GPT-5.2 adds less unrequested validation and defensive code, so the output is closer to what you asked for”
Really nice little tidbit there. Thanks for the post it was really informative.