
We Tested DeepSeek V4 Pro and Flash Against Claude Opus 4.7 and Kimi K2.6

DeepSeek V4 Pro and DeepSeek V4 Flash launched together on April 24, 2026 under MIT license. They are DeepSeek’s first new architecture since V3, and their first open-weight lineup with two tiers (Pro as the flagship, Flash as the lightweight model).
We ran both through the same FlowGraph spec we used for Claude Opus 4.7 vs Kimi K2.6. With the same spec, same prompt, same scoring rubric.
TL;DR: DeepSeek V4 Pro scored 77/100 and lands between Opus 4.7 (91) and Kimi K2.6 (68) in terms of performance. DeepSeek V4 Flash scored 60/100 for $0.02, a price point we have not seen on this test before, but its build failed and the output is missing some key pieces.
The Four Models We Compared
We compared:
Claude Opus 4.7
Kimi K2.6
DeepSeek V4 Pro
DeepSeek V4 Flash
DeepSeek V4 Flash is the cheapest model in the comparison by a wide margin. Output tokens cost less than 1/14th of Kimi K2.6 and roughly 1/89th of Claude Opus 4.7.
The Test
This is the same FlowGraph spec we used in the Opus 4.7 vs Kimi K2.6 run, a workflow orchestration backend with 20 endpoints, persistent state, lease management, retries, and event streaming. It is a heavier infrastructure test than our usual coding benchmarks to push the models to their limits.
We ran DeepSeek V4 Pro and DeepSeek V4 Flash through the same setup to see where the new DeepSeek lineup lands on cost and first-pass quality next to Claude Opus 4.7 and Kimi K2.6.
The Prompt
We ran both DeepSeek models in Kilo CLI with the same prompt we used for Opus 4.7 and Kimi K2.6:
“Read @SPEC.md and build the project in the current directory. Treat @SPEC.md as the source of truth. Do not simplify this into a mock, toy app, or basic CRUD scaffold. Create all code, configuration, Prisma schema, tests, and README needed for a runnable project.…”
Both DeepSeek models ran on thinking mode in their own empty directories with no shared state.
What Each Model Produced
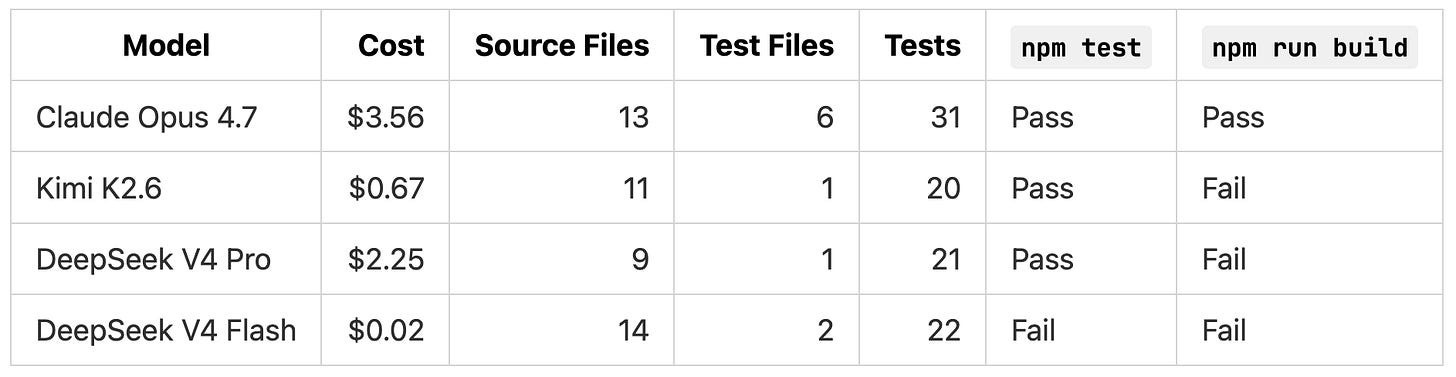
DeepSeek V4 Pro passed its own test suite but the TypeScript build failed. DeepSeek V4 Flash’s test suite never ran because its setup script tried to force-reset the database in a way that errored out before the first test executed.
If we had stopped at the model summaries, both DeepSeek implementations would look closer to Claude Opus 4.7 than they actually were. A direct code review plus targeted reproductions against isolated SQLite databases revealed the problems in both model outputs.
DeepSeek V4 Pro
DeepSeek V4 Pro got the broad shape of the system right. The endpoints are wired up, the test suite passes, and the project layout is reasonable. The issues we found are concentrated in the same places as Kimi K2.6: lease expiry handling, scheduling, validation, and build integrity.

Timed-out workers can still complete steps
When a worker claims a step, the system gives it a lease that expires after a set timeout. If the worker stalls or crashes, the lease should expire and another worker should be free to pick up the step. Once the lease has expired, the original worker is no longer the owner of that step and shouldn’t be able to mark it as done.
DeepSeek V4 Pro enforces this on heartbeats but not on completions. We claimed a step, pushed its lease expiry into the past, then asked the API to mark the step as successfully completed. The API returned 200 and recorded the step as succeeded. The original worker effectively reached past its expired lease and finalized work it no longer owned.
DeepSeek V4 Pro’s own README says workers cannot complete after their lease expires, but the implementation does not enforce that.
A full workflow blocks unrelated work
A workflow run can declare a maximum number of steps it is allowed to run in parallel. When that cap is reached, the saturated run shouldn’t accept more work, but other runs sharing the same queue should keep moving.
DeepSeek V4 Pro’s claim logic checks one candidate at a time. If that candidate happens to belong to a run that is already at its parallel cap, the function gives up and returns nothing, instead of moving on to the next candidate.
We reproduced this with two active runs sharing a queue. Run A was at its parallel limit. Run B had capacity and a higher-priority step ready to go. The next claim request came back empty. In production this would look like workers idling while there is real work to do, just because the first run on the queue happens to be saturated.
The project does not build
npm test passes but npm run build does not. Even after the build errors are fixed, the project still would not be runnable through npm start. The TypeScript config is set to not emit any compiled output, while package.json expects npm start to run that compiled output. A user following DeepSeek V4 Pro’s own README on a clean checkout would not get a working server.
DeepSeek V4 Flash
At $0.02 for the entire run, DeepSeek V4 Flash is in territory we have not tested before. The internal logic is plausible. The public API is where it falls apart.
Clients can’t start a workflow run
To use this system, a client first creates a workflow run by calling a specific endpoint. Without that endpoint working, nothing else can happen. There is no run for workers to claim from, no events to stream, no step to complete.
DeepSeek V4 Flash wrote the handler for this endpoint, but mounted it under the wrong route prefix. The spec requires it at /workflows/key/:key/runs. DeepSeek V4 Flash actually serves it at /runs/key/:key/runs. A request to the spec path against the running server returned 404 Endpoint not found. The README documents the spec path, but the server does not serve it.
DeepSeek V4 Flash’s tests call internal functions directly rather than going through the HTTP API. From the test suite’s perspective, everything was fine. From an actual client’s perspective, the entry point to the system was missing.
Failed workflows still hand out work
Once a workflow run fails (because one of its steps used up all its retry attempts), every other step in that run should stop. The spec calls for the remaining steps to move into a blocked state so workers will not pick them up.
DeepSeek V4 Flash’s recovery logic loads all expired steps at the start, then handles them one by one. If the first expired step exhausts its retries and fails the parent run, a later step in the same batch can still be promoted to a “ready to retry” state, even though the run it belongs to is already over.
We reproduced this with two expired steps in one run:
Step a had no retry attempts left and was correctly marked dead
The parent run was correctly marked failed
Step b ended up in waiting_retry instead of blocked
A worker polling for new work would still receive step b and execute it for a workflow that had already failed. Claude Opus 4.7 had a related multi-expired lease bug. Kimi K2.6 missed live event streaming entirely. Recovery under contention keeps being the hardest part of this spec for any model to get right on the first pass.
Same timeout bug as DeepSeek V4 Pro
DeepSeek V4 Flash has the same expired-lease completion bug as DeepSeek V4 Pro. An expired lease can still finalize the work, even though the original worker no longer owns the step.
It also rejects valid request payloads. The spec says workflow run input and metadata can carry arbitrary JSON, which includes arrays, strings, and numbers. DeepSeek V4 Flash’s validation only accepts JSON objects. A client sending a JSON array as input would get a 400 response even though the spec accepts it.
Tool calling held up better than expected
The bugs above are about the output DeepSeek V4 Flash produced. Tool calling is a separate axis: how the model performed inside Kilo CLI. On that axis, the model held up surprisingly well. It read files before editing them, installed dependencies and ran the test suite at sensible points, and did not get stuck in retry loops on broken commands. The agent loop ran cleanly even when the code it produced had gaps.
That is not what we expected from a model at this price tier. Tool calling reliability is usually where cheaper models break down first, with malformed arguments, hallucinated file paths, or runaway loops that burn through tokens without making progress. DeepSeek V4 Flash avoided those failure modes in our run.
Scoring
We used the same 7-category rubric as the Opus vs Kimi post.
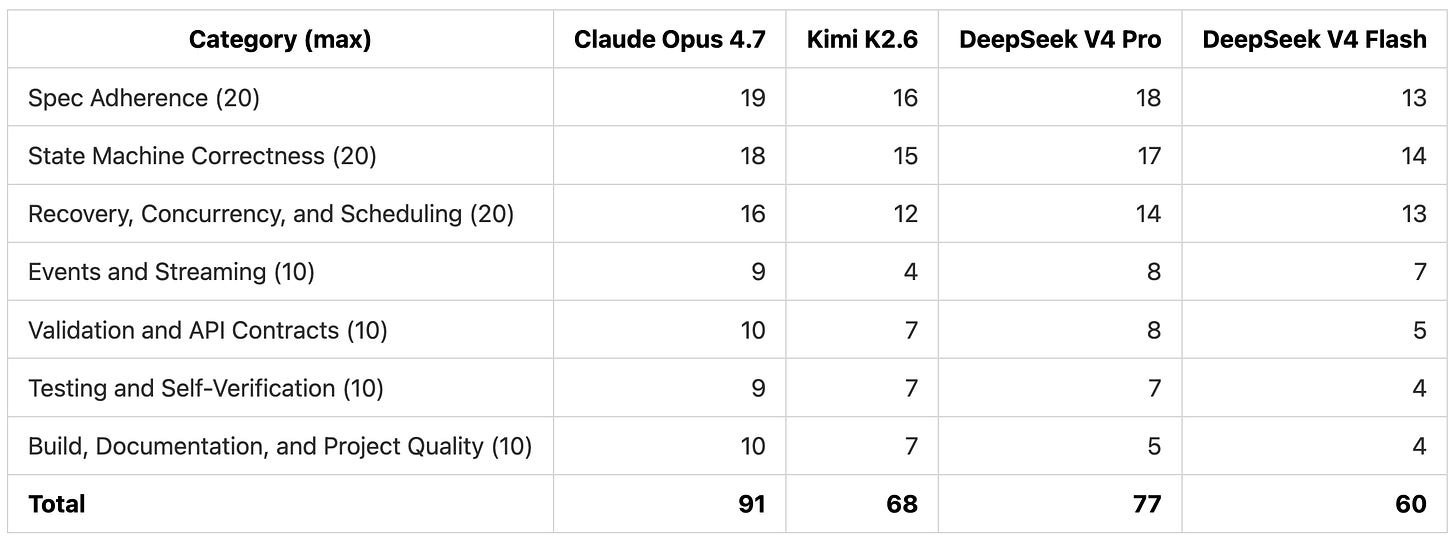
DeepSeek V4 Pro slots between Claude Opus 4.7 and Kimi K2.6. The gap with Opus is concentrated in build quality and lease handling. DeepSeek V4 Flash sits below Kimi K2.6, with deductions in nearly every category.
Cost vs Quality
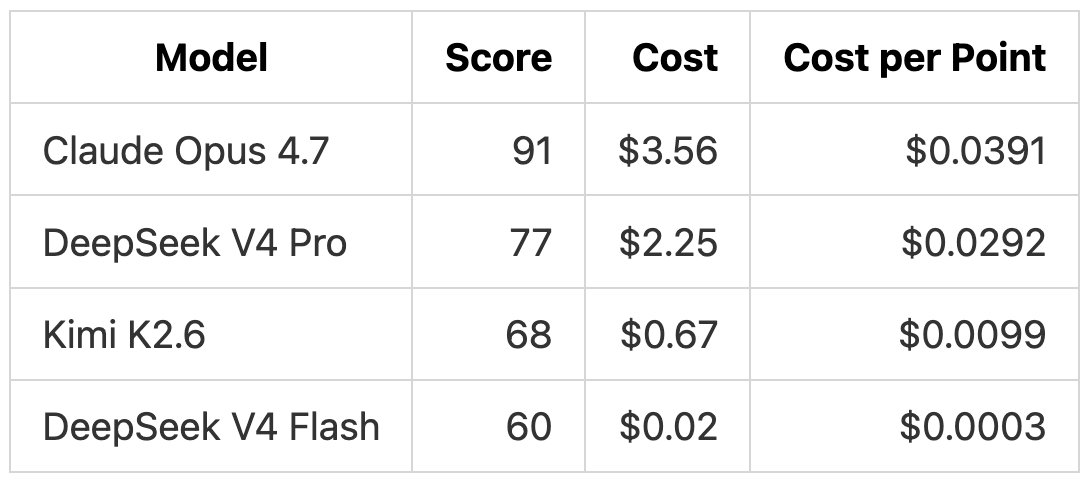
DeepSeek V4 Flash’s cost per point is roughly 30x cheaper than Kimi K2.6 and 100x cheaper than Opus 4.7 on this benchmark. The score is lower, but the absolute dollar amount is so small that running the same task three or four times to compare attempts is still cheaper than one Kimi K2.6 run.
DeepSeek V4 Pro is more expensive than Kimi K2.6 in this run because we ran it before applying the official discount.
What This Means for Open-Weight Models
The pattern from previous comparisons keeps holding. The gap on surface coverage between open-weight and frontier proprietary is narrow. The gap on correctness inside hard code paths (lease recovery, cross-run scheduling, expired-lease rejection) is still there but also narrowing.
DeepSeek V4 Pro is the practical step up from Kimi K2.6 based on our test. Same general failure pattern, but cleaner overall structure and fewer spec-level gaps. With DeepSeek’s official discount in effect, the price gap with Kimi closes and the quality gap stays.
DeepSeek V4 Flash is a different conversation. At full price it is cheaper than the existing budget tier (Gemini 3.1 Flash Lite, Claude Haiku 4.5) by a wide margin. A 60/100 score on this spec is not a reason to use it on its own, but the cost is. For tasks where you can absorb a rough first pass and a human review, $0.02 per attempt changes the math considerably.
Our Takeaways
Claude Opus 4.7 still pulls ahead. The trickier parts of the spec (anything involving timing, recovery, or coordination between moving pieces) are where every other model lost points. Claude Opus 4.7 had only one reproducible bug while the other three had more.
DeepSeek V4 Pro performed better than Kimi K2.6 in this run. It scored 9 points higher, runs at a lower per-token list price, and produces about the same shape of failures under review. With DeepSeek’s official discount through May 31, the cost gap is even larger.
DeepSeek V4 Flash is a new category. It is not fully reliable for complex backend builds without a cleanup pass. But $0.02 for a first-pass attempt at a backend of this size is a price point that did not exist before. If you can absorb imperfect output, the math changes.
Thanks for this comparative deep dive, it would be nice if we could also see gpt 5.5 medium comparison in the same way.
I'd be interested to see how these models perform when they're given only parts of the spec, not the entire thing. That would be much reflective of how I use Kilo Code for cheap, high-quality outputs: expensive planner/orchestrator, cheap implementer.