
Tokenmaxxing Without Breaking the Bank
Agentic engineering can be remarkably cost-efficient, if you use the right tools for the job

We’re in the middle of a massive shift in how software is built. We aren’t just asking LLMs to rewrite an HTML file anymore—we’re tokenmaxxing.
Today, developers are feeding entire codebases into massive context windows, running multi-turn agentic loops, and letting AI run complex workflows that improve themselves over time. Instead of rationing our compute, we're trying to use as many tokens as possible to maximize output.

The term “tokenmaxxing” exploded earlier this year, adapting the internet culture suffix “-maxxing” to the world of AI compute and inference. Initially starting as a somewhat performative trend where developers maximized their AI token consumption to climb internal company leaderboards and prove they were “AI native” (Meta employees famously burned over 60 trillion tokens in a month), this trend quickly sparked debates about whether it was driving real productivity or just inflating API bills and wasting compute — is tokenmaxxing the ticket to your future or just a weird new trend?
But things move fast in AI. The concept has already matured past the initial hype: rather than mindlessly burning tokens for status, smart teams are focusing on how to strategically deploy massive context windows and agent loops to exponentially multiply their output—like using AI to do the work of entire engineering teams without the bloat.
But as context windows grew to millions of tokens, a collective anxiety hit the engineering community: How much is this going to cost me?
The good news? You don’t have to ration your tokens like a space monkey. Here is how you can lean into the token-heavy future of engineering without breaking the bank.
Yes, You Should Be Tokenmaxxing (The Trend is Your Friend)
First, let’s address the elephant in the terminal: tokenmaxxing is a massive competitive advantage. The trend toward using vastly more tokens than you might have used even a couple of months ago isn’t just hype; it’s a fundamental shift in how software is built. When you feed an agent your entire codebase, its architecture diagrams, and your full linting history, the quality of its output doesn’t just improve linearly—it jumps exponentially.
And once you start using multiple agents and sub-agents, taking advantage of features like multiple worktrees and (my personal favorite) cloud agents in Kilo, each of those agents will want to max out tokens too.
And they should.
Deep context prevents hallucinations. Massive reasoning loops and additional “monitor” agents can catch edge cases before they hit staging. If your current workflow consists of copying and pasting isolated snippets into a chat UI because you’re afraid of the API bill, you are leaving massive productivity gains on the table.
You should be throwing tokens at your problems. It’s the closest thing to downloading more engineering bandwidth.
Look Beyond the Frontier Labs to OSS Models
So we can agree that using a lot of tokens is a good idea. But how do you keep this affordable?
The days of venture-backed AI companies deeply subsidizing compute costs out of their own pockets are gone. APIs are pricing closer to real utility costs now. To stay efficient, your first strategy should be looking beyond the big proprietary frontier labs and embracing the open-weight and open-source ecosystem.
Open-weight models have gotten incredibly good at functioning as the brain of an agent, offering blistering speed at a fraction of a cent per token, with even larger context windows and a range of powerful flash models emerging in the past few weeks alone.
The PinchBench Reality Check: Open-Weight Value
If you want proof of how viable open-weight models are for real engineering workflows, look at the latest PinchBench cost data. PinchBench evaluates models on actual agentic tasks (like file operations, scheduling, and coding) rather than synthetic vibe-checks. The data paints a clear picture: you are overpaying if you default to frontier models for everything.
Let’s look at the cost of running a full suite of agentic benchmark tasks:
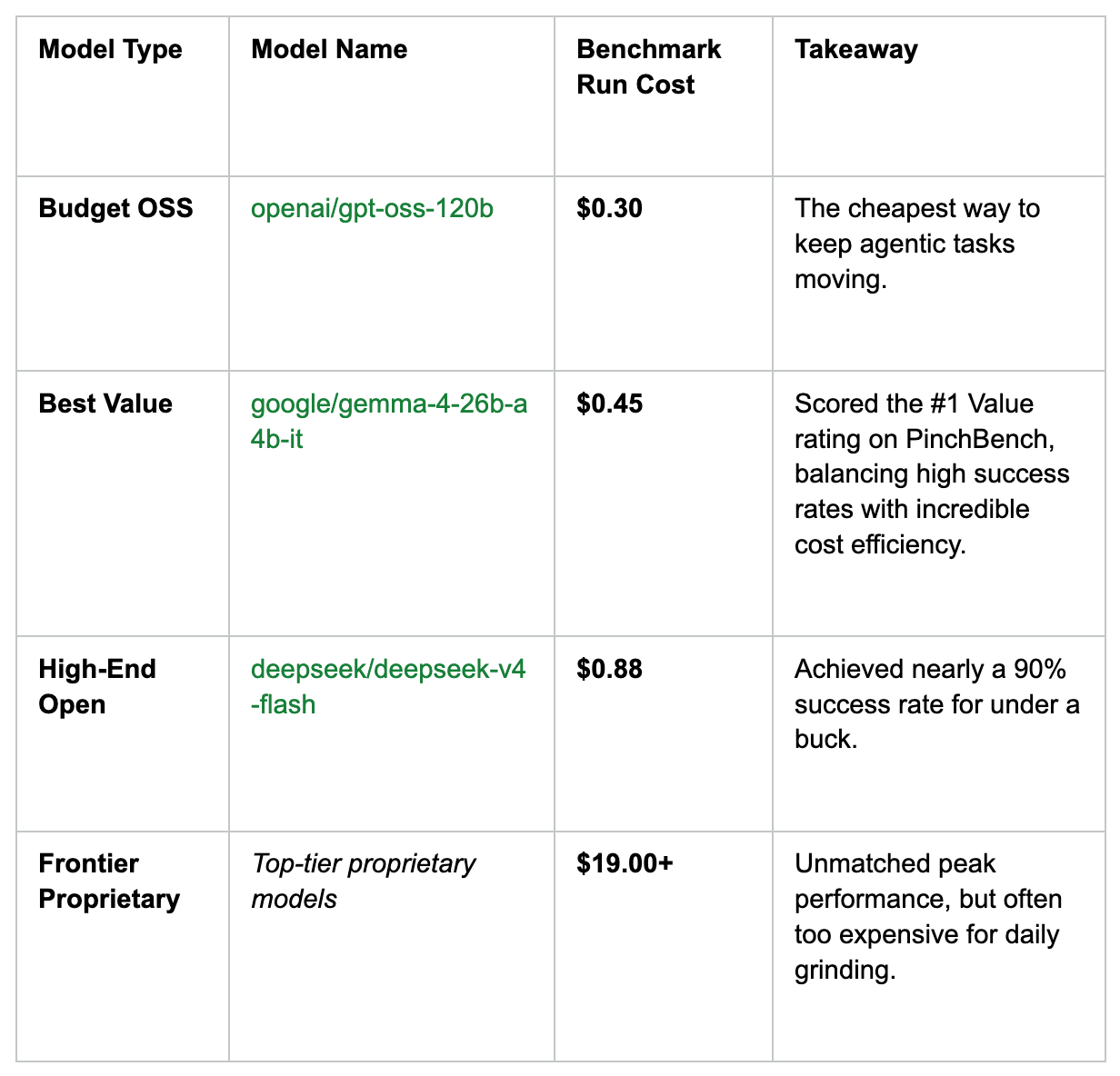
A model like Gemma-4-26B might be too small for some tasks, but it’s ideal for sub-agents and repetitive workflows. By experimenting with OSS models you can save a lot on a daily basis.
Let Kilo Do the Thinking For You
Start exploring the full range of open-weight models, and your head might start to spin from so many options, like Kimi K2.6 and GLM-5.1. The challenge is the cognitive load of constantly switching models depending on the task.
That’s why we built Kilo Balanced.
Instead of manually playing traffic cop with your API keys, our Auto Balanced model dynamically routes your tasks. Simple code completions and lookups go to ultra-efficient open-source models, while heavy logic reasoning gets escalated to the heavy hitters (but only the affordable ones). You don’t even have to think about it.
Look at how easy it is to set up: Check out Kilo’s Balanced Auto-Model Documentation to automate your model routing instantly.
Top-Tier Tokenmaxxing: Hunt for Discounts on Frontier Models
Your second strategy is capitalizing on volume and infrastructure discounts. If you are doing serious agentic engineering, you shouldn’t be paying retail API rates on the big models when you need them.
The frontier players are still the best for big projects and deep thinking.

With Kilo Pass, we’ve built a tiering system that rewards high-volume usage: the more tokens your team consumes, the steeper your baseline discount becomes. Best of all, there are zero unexpected costs, overage traps, or hidden fees. What you see is what you pay.
On top of that, we are currently running a massive promotion through the Kilo Gateway. Three of the most powerful engineering models on the planet—Anthropic’s Claude Opus 4.7, Opus 4.6, and Sonnet 4.6—are currently 20% off.
The release of Opus 4.7 set a new standard for the industry. Now you can max out Opus tokens without such a high price tag.
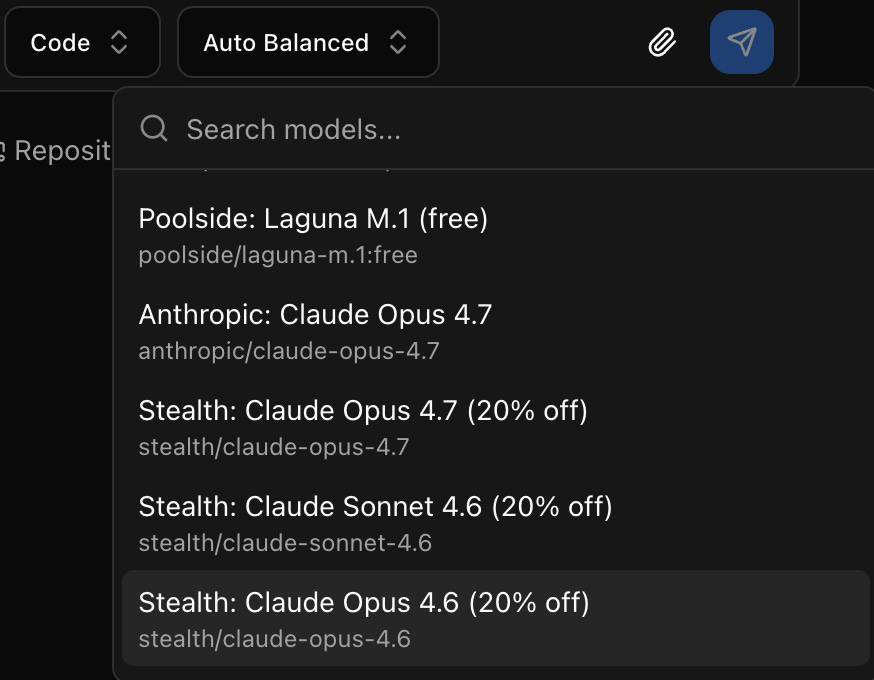
Thanks to a special stealth provider, these top Claude models are currently available at a massive discount to anybody using Kilo Code.
Note that like other stealth releases, these discounted models might train on your data.
Doing the Math on Daily Agentic Engineering
When people think of AI agents, they often picture “always-on” autonomous bots running 24/7 in the background. But the real token sink for most developers is daily agentic engineering—the intensive, highly iterative code-generation loops you run while actively sitting at your desk and working in tandem with your agents.
Let’s look at the numbers for an engineer running heavy daily workflows using frontier models (for advanced reasoning tasks that are too complex for the open-weight tier). I mean the type of agentic flows that do the work of 1-2 junior engineers.
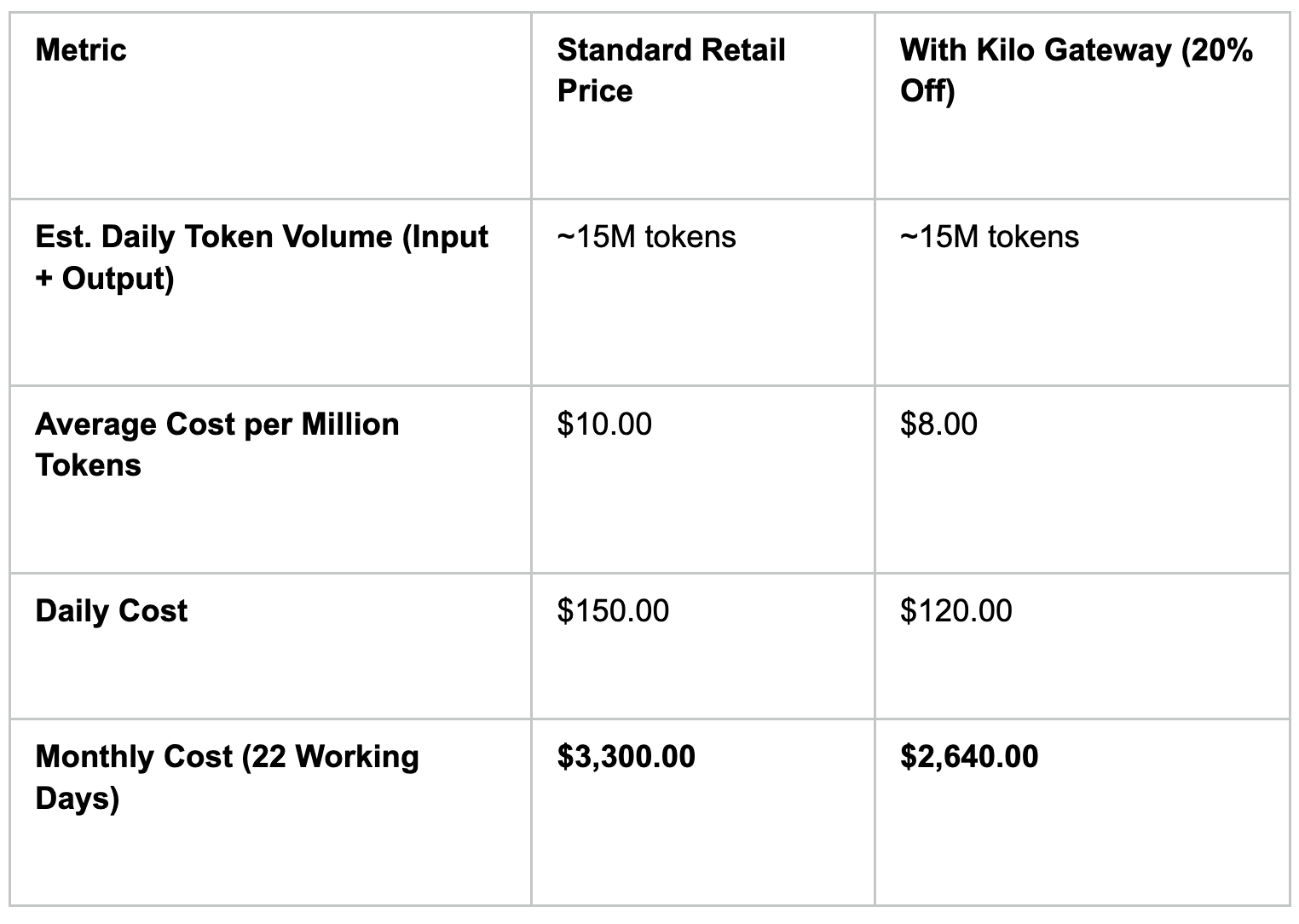
By shaving 20% off frontier models via the Kilo Gateway, a single power-user engineer saves $660 a month.
Scale that across a 10-person engineering team, and you are looking at over $6,600 back in your budget every single month—without sacrificing access to top-tier reasoning capabilities. Combine that with the volume discounts unlocked by Kilo Pass and the automatic routing of Kilo Balanced, and your actual savings multiply even further.
Tokenmaxxing is the future of software development, but it shouldn’t require a funding round just to pay your monthly API bill. By leaning into the open-weight ecosystem for the basics and taking advantage of straightforward pricing and discounts from a platform like Kilo, you can let your agents run wild while keeping your burn rate firmly under control.
Hint: Don’t want to miss out on the latest discounts? Follow Kilo on X.
While I continue to think "tokenmaxxing" is just another attempt at "lines of code" productivity measurements - which was debunked decades ago - this line: "The data paints a clear picture: you are overpaying if you default to frontier models for everything" is something I've been saying.
But no, for almost everyone, it's "All Claude, All The Time" - despite the idiocy.