
PinchBench v2: Call for Contributors to the Leading OpenClaw Benchmark
Help us make PinchBench even better

We’re excited to announce that PinchBench v2 is now in active development — and we’re opening the doors for community contributions to help shape the next major release. 🦀
PinchBench is Live on ProductHunt today!
The Remarkable Rise of PinchBench
PinchBench started as a side project of Kilo DevRel mastermind Brendan O’Leary, who wanted to build a benchmarking system for evaluating LLM models as OpenClaw coding agents. The idea was simple: run tests based on real-world tasks to help users choose the right model for their use case. But my oh my, has that “side project” taken off!
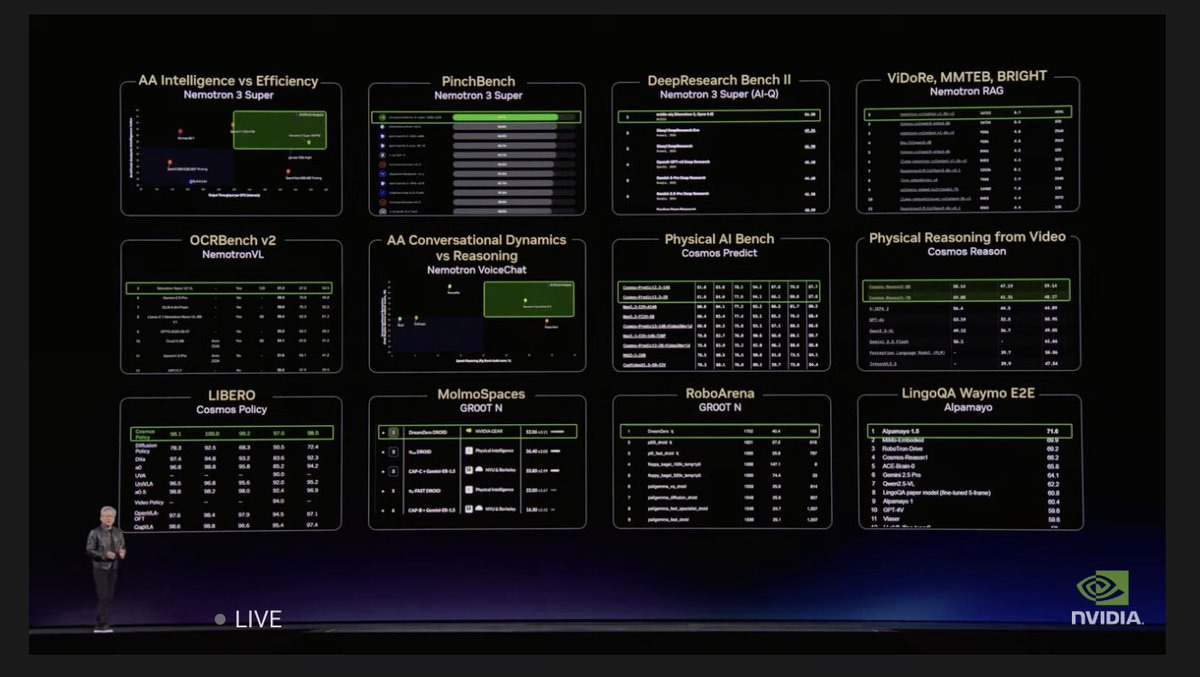
During his recent keynote, NVIDIA CEO Jensen Huang showcased PinchBench on stage as a definitive standard for evaluating the real-world performance of OpenClaw agents. He highlighted Nemotron 3 Super’s performance as the top open-weight model for OpenClaw use cases.
In the following week, MiniMax has announced that they will soon release the weights for MiniMax-M2.7, and Z AI has shared that the much-anticipated GLM-5.1 will also have open weights. The competition is heating up, and not just for OSS models. This is only the beginning of the agentic revolution.
We need your help to make PinchBench even more useful and comprehensive. The era of generalized benchmarks is over. It’s time for benchmarks that help you choose the best LLMs for always-on agents, with a focus on specific skills that can be used around the clock in tools like KiloClaw.

What We’re Building
PinchBench v2 is a significant leap forward. Our aim is to produce a benchmark that more accurately captures the real-world complexity of agentic tasks — including longer task horizons, better verification, and a much richer picture of model performance across a wider set of domains. As KiloClaw continues to lead the charge for hosted OpenClaw ease-of-use, functionality and security, we want to make sure that PinchBench is equally ahead of the curve.
Our goal for v2 is 100 tasks, and we’re especially focused on testing across a wider range of OpenClaw use cases. We want contributions that reflect the kinds of tasks OpenClaw is actually being used for in practice, paired with rigorous success-rate measurement. If you’re running OpenClaw in production or research contexts, you’re exactly who we want to hear from.
On the leaderboard side, we’re investing in a substantially improved UI/UX — better filtering, model landing pages, user profiles, per-task variance, and more — to make results easier to understand and compare.
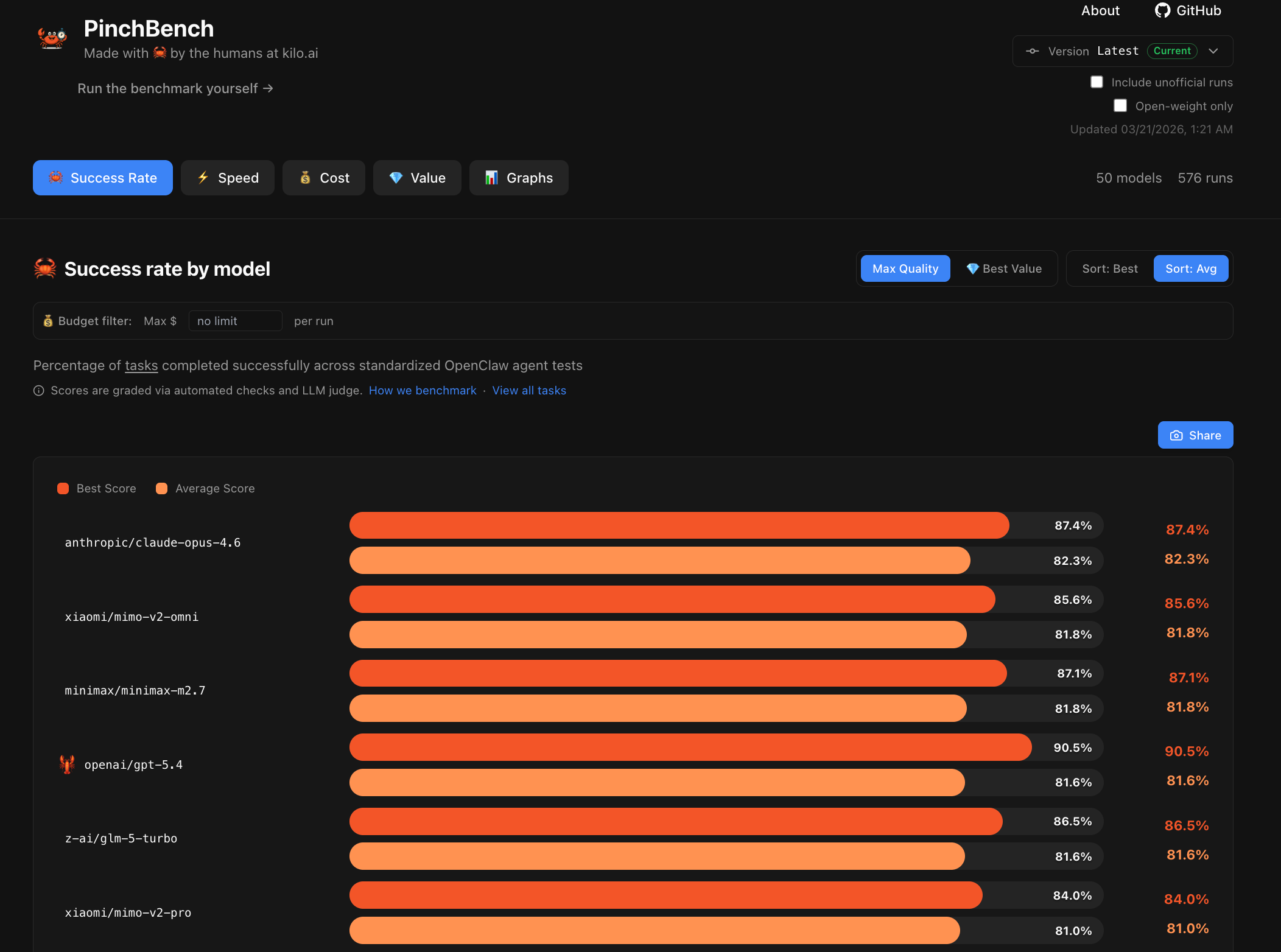
Open Call for Contributions
The contribution window is open now through April 15th, 2026.
We are looking for two types of contributors: skills and leaderboard. You are welcome to contribute in both categories.
Skills Contributions
Help us expand and improve the task suite:
New tasks — What should OpenClaw be doing that we aren’t currently measuring? We want tasks that represent real, valuable work: things a practitioner would actually run OpenClaw on, with clear and programmatically verifiable success criteria. Tasks should be relevant across both local and hosted OpenClaw instances — including hosted services like KiloClaw and KimiClaw.
Task improvements — Some existing tasks fail at high rates across nearly all models, and others may not reflect the current state of what OpenClaw can do. If you can identify, fix, or replace tasks that aren’t pulling their weight, we want your PR.
Success rate coverage — Contributions that include baseline success rates across multiple models are especially valuable. Help us ensure the benchmark is neither too easy nor impossibly hard at release. It’s all about real-world agentic use.
Good tasks should be:
Realistic — something OpenClaw would genuinely be run on in a real workflow
Clearly specified — a passing solution should unambiguously satisfy the task
Well-calibrated in difficulty — ideally targeting a solve rate that distinguishes model capability
Convention-compliant — all tasks must follow OpenClaw skill conventions to ensure consistency and compatibility across the benchmark
Leaderboard Contributions
Help us build a leaderboard that’s detailed, clear, relevant and accessible.
We’re working through a range of UI/UX improvements for v2, including redesigned filtering and navigation, model and contributor profile pages, improved scoring to eliminate run-size bias, and daily/weekly/monthly recognition badges. If you have front-end chops and care about how benchmark results are communicated, this is where we need you.
How to Contribute
There are no forms to fill out. Anybody can contribute.
Review the open issues in the PinchBench v2 meta issue to understand what’s in scope
Propose a new task or improvement in GitHub Discussions or by opening an issue — especially for OpenClaw-specific use cases you want to see covered
Implement your contribution by forking the repo, building it out, and submitting a PR
Iterate with reviewers to get your contribution merged
Recognition
Contributors will be recognized in the v2 release in two categories:
Skills Contributors — recognized for accepted new tasks and task improvements, ordered by number of accepted contributions
Leaderboard Contributors — recognized for accepted UI/UX improvements to the leaderboard
Every accepted contribution counts. Whether it’s one well-crafted task or a full leaderboard feature, we aim to acknowledge top community contributions in the release.
Get Involved
GitHub: pinchbench/skill — browse open issues and the v2 meta issue
v2 Meta Issue: #60 — the full list of what’s in scope for this release
PinchBench is a community project, and v2 will be shaped by the people who contribute to it. We’d love your help in improving the definitive benchmark for OpenClaw use cases. Learn more about PinchBench and KiloClaw.