
MiniMax-M2.7 Is Now Available in Kilo. Here’s How It Performs.
We benchmarked MiniMax M2.7 against the most popular coding models and summarized the results.


MiniMax just released MiniMax-M2.7, their most capable model yet. It’s available now in Kilo across the IDE extension, CLI, and Cloud Agents.
We ran it through two benchmarks: PinchBench, our OpenClaw agent benchmark, and Kilo Bench, an 89-task evaluation that tests autonomous coding across everything from git operations to cryptanalysis to QEMU automation.
Here’s what we found.
TL;DR: M2.7 scores 86.2% on PinchBench, placing 5th overall and within 1.2 points of Claude Opus 4.6. On Kilo Bench, it passes 47% of tasks with a distinct behavioral profile — it may over-explore hard problems (which can lead to timeouts) but solves tasks that no other model can. It’s a fast and affordable model that fills some gaps that frontier models miss.
PinchBench: #5 Out of 50 Models
PinchBench runs standardized OpenClaw agent tasks and grades them via automated checks and an LLM judge. M2.7 scored 86.2%, landing just behind GLM-5 and GPT-5.4 (both 86.4%) and just ahead of Qwen3.5-plus (85.8%).
The top of the leaderboard as of today, March 18, 2025:
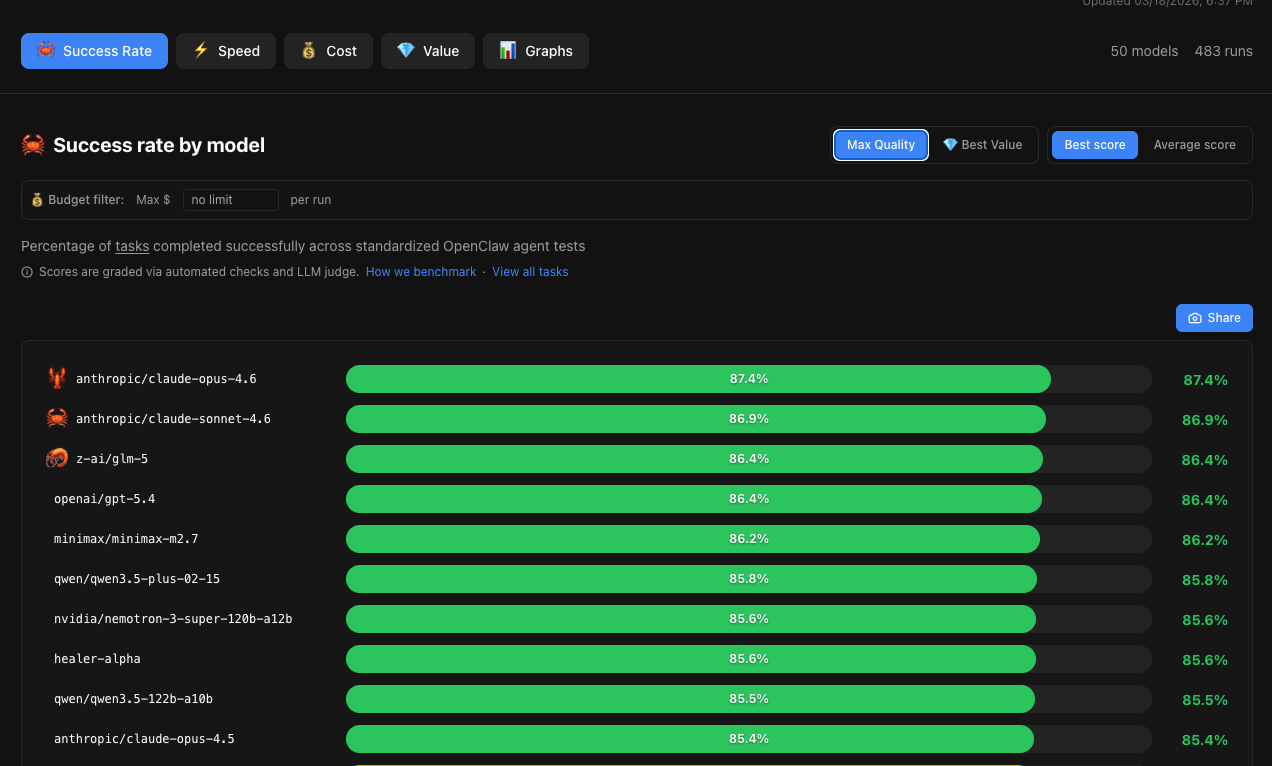
The gap between 1st and 9th place is less than 2 points. M2.7 is competitive with the best models available at the agentic coding task level that PinchBench measures.
What’s notable is the jump from M2.5 (82.5%) to M2.7 (86.2%) — a 3.7-point improvement that moved MiniMax from the middle of the pack into the top tier.
You can try MiniMax M2.7 today in a cloud-hosted, fully-managed OpenClaw instance using KiloClaw. Set up takes 2 clicks and about 60 seconds, and you can access it from the Kilo dashboard:
Kilo Bench: 89 Tasks vs 5 Other Models
PinchBench tells you how a model performs on typical agent tasks in OpenClaw. Kilo Bench tells you where it breaks.
We ran M2.7 through 89 tasks in Kilo CLI alongside four other models: Qwen3.5-plus, GLM-5, Kimi K2.5, and Qwen3.5-397b. Each model received a single prompt and ran autonomously — no human intervention, no course correction — for up to an hour per task depending on complexity.
Overall Results
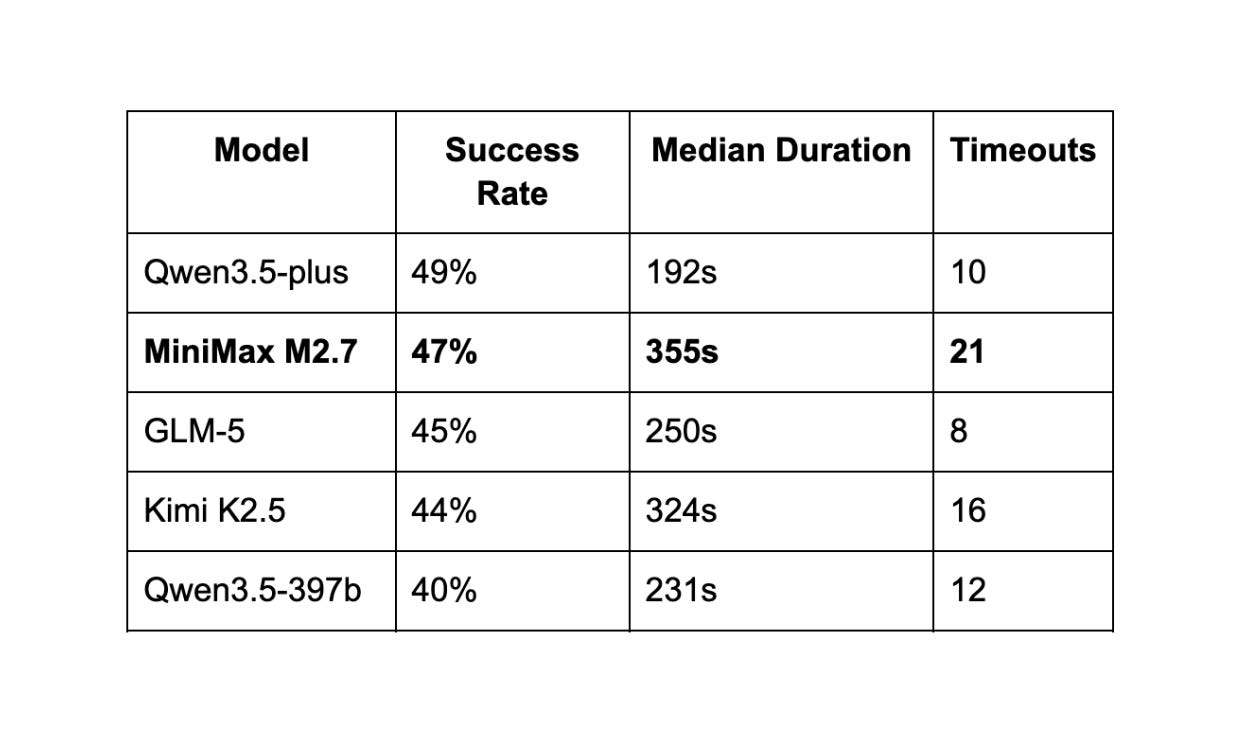
M2.7 came in second overall at 47%, two points behind Qwen3.5-plus. But the raw pass rate doesn’t tell the full story.
One pattern stood out: MiniMax-M2.7 reads extensively before writing. It pulls in surrounding files, analyzes dependencies, traces call chains. On tasks where that extra context pays off, it catches things other models miss. On tasks where the clock is ticking, that might cause it to run out of time.
This is the same exploration-heavy behavior we saw in our Code Reviewer cost analysis with Claude Opus 4.6, which consumed 1.18M input tokens on a single PR while Kimi K2.5 used 219K on the same diff. Deep reading finds deeper bugs — but it costs time and can consume more tokens.
Where M2.7 Stands Out
The most interesting finding from Kilo Bench isn’t the pass rate. It’s what each model uniquely solves.
Every model in this comparison solved tasks that no other model could:
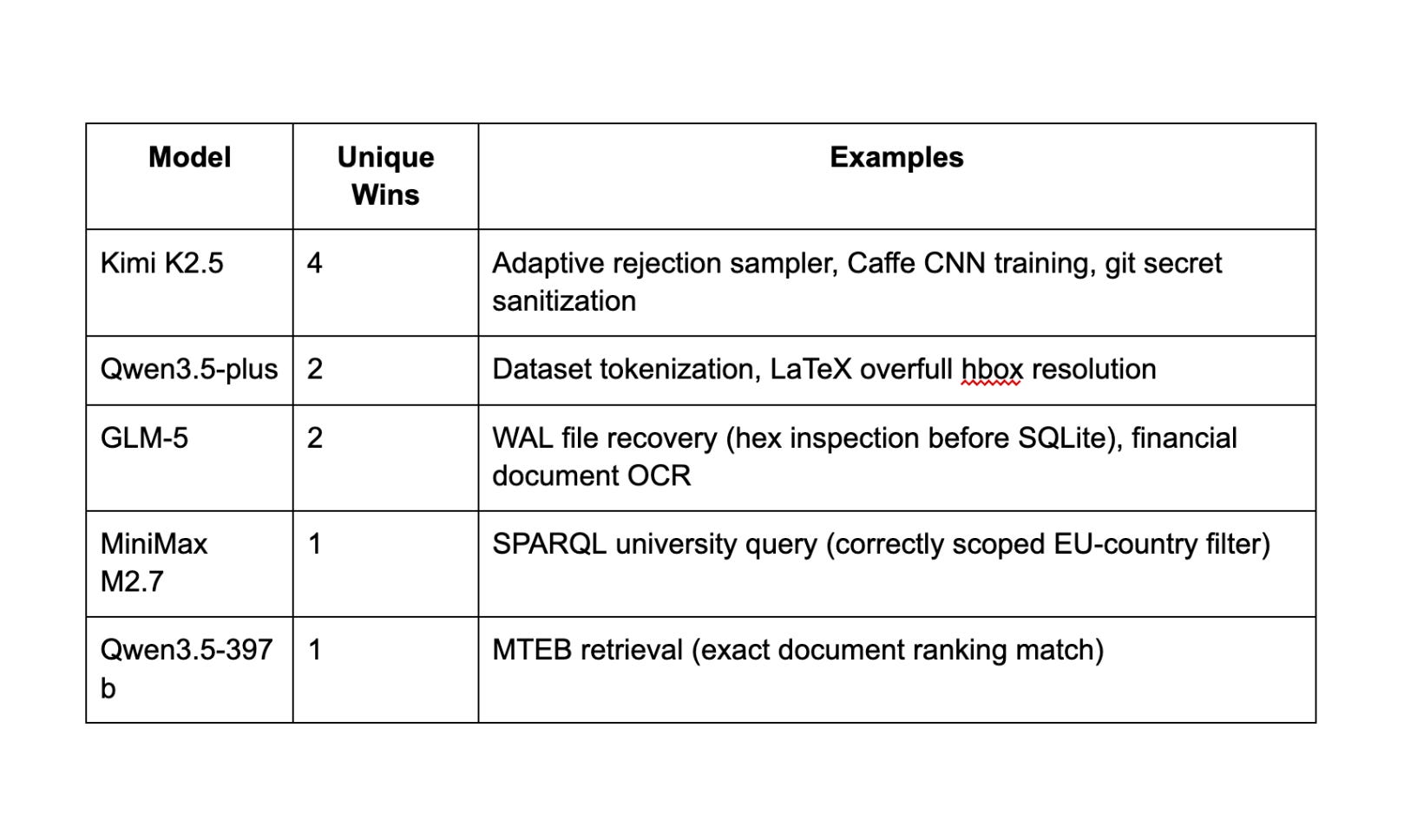
M2.7’s unique win on the SPARQL task is a good example of its strength: the task required understanding that an EU-country filter was an eligibility criterion, not an output filter. That’s a reasoning distinction, not a coding one.
A hypothetical oracle that picks the best model per task would solve 60 out of 89 tasks (67%) — a 36% improvement over the best single model. These models aren’t interchangeable. They’re complementary.
Task Difficulty Breakdown
The 89 tasks split into clear tiers:
18 tasks all 5 models solved — git operations, text processing, basic ML, infrastructure setup. These are table stakes for any capable coding model in 2026.
17 tasks where 2-3 models succeeded — this is where model selection actually matters. Tasks like differential cryptanalysis, Cython builds, and inference scheduling separate models by their behavioral tendencies, not just their raw capability.
29 tasks no model solved — circuit synthesis, MIPS emulation, pixel-perfect rendering, competitive CoreWars. These represent the current hard ceiling for LLM-based agents regardless of which model you pick.
Token Efficiency
M2.7 consumed roughly 2.8M input tokens per trial on average, which is on the higher end of any model tested. For context:
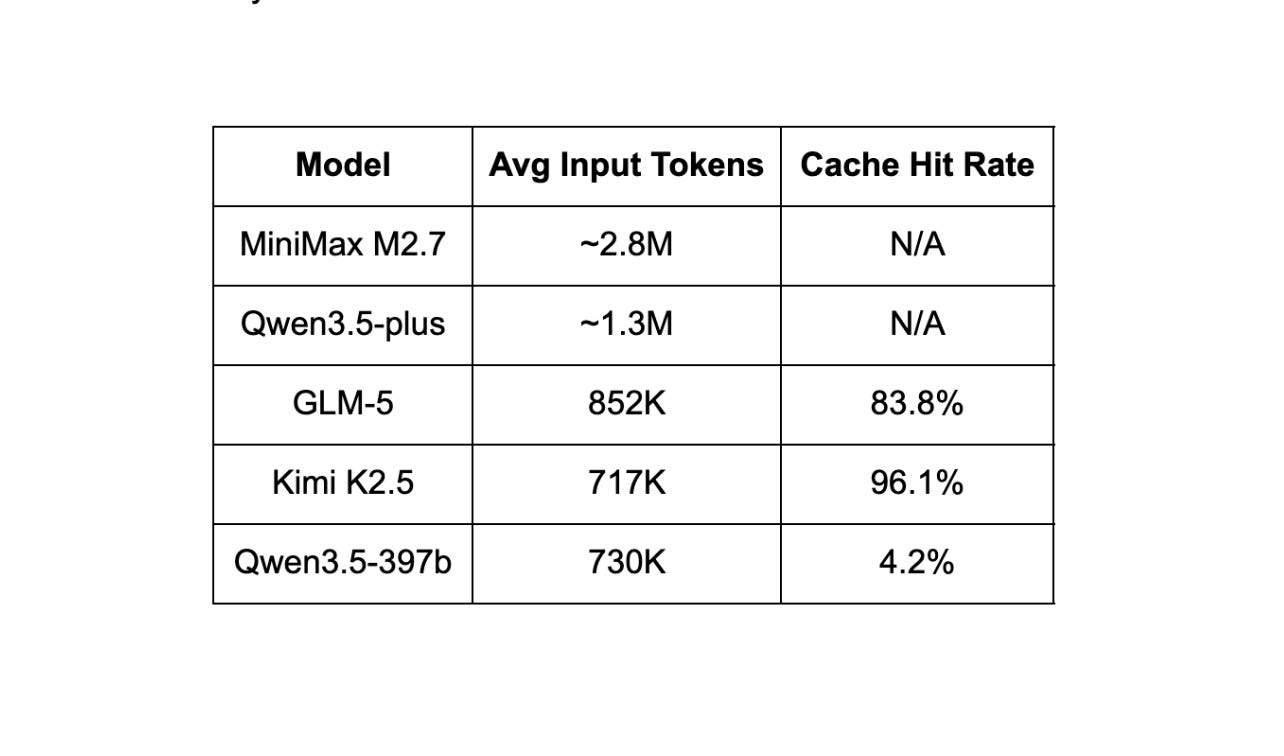
M2.7 reads more context per step than any other model, which means it accumulates more tokens over the course of a task. When it works, that thoroughness produces correct solutions. When it doesn’t, it means more tokens and time spent on each task.
What MiniMax-M2.7 Does Differently
MiniMax’s announcement describes M2.7 as their first model that “deeply participates in its own evolution” — the model was involved in updating its own memory, building training skills, and improving its own learning process during development. They report it autonomously ran over 100 rounds of scaffold optimization, achieving a 30% performance improvement on internal evals.
That’s a genuinely novel training approach and worth reading about in MiniMax’s full announcement. Whether the self-evolution process contributes to M2.7’s exploration-heavy behavior in our benchmarks is an interesting question we can’t answer from the outside.
When to Use M2.7
Based on both benchmarks, here’s how M2.7 fits into the model landscape available in Kilo:
M2.7 is a strong pick when you’re working on tasks that reward deep context gathering — complex refactors, codebase-wide changes, or anything where understanding surrounding code matters more than speed. Its PinchBench score puts it in the same tier as GPT-5.4 and GLM-5 for general agent tasks. Compared to frontier models like Opus 4.6 and GPT 5.4 that offer the same attributes, it’s much less expensive at $0.30/M input and $1.20/M output.
Consider a different model (even such as M2.1 or M2.5) when you need very fast iteration cycles or are working on well-scoped, time-sensitive tasks. M2.7’s median task duration (355s) is notably longer than its predecessors.
The best approach is what Kilo is built for: switch models based on the task. Use M2.7 for the work that benefits from a compromise of thorough analysis and speed. Use something lighter for the tasks that need quick turnaround. With 500+ models available, you’re not locked into any single tradeoff.
MiniMax-M2.7 is available now in Kilo. Try it in the IDE extension, CLI, or Cloud Agents.
Testing performed using Kilo CLI and PinchBench. PinchBench is open source and available at https://pinchbench.com. Kilo is the free, open-source, all-in-one agentic engineering platform for VS Code and JetBrains with 1,500,000+ Kilo Coders.
My practical experience with M2.7 has been extremely disappointing, particularly when it comes to following migration plans.
M2.7 almost constantly ignores the plan and the phases that are supposed to be worked through. Instead of migrating existing elements, it creates dummy UI components and placebo elements — and then complains that the work is "too complex."
In other places, it simply generates TODO comments and then proceeds to ignore them entirely.
It does not make use of the tools provided by Kilo Code and insists on making all changes exclusively via sed — which is completely inadequate for real-world development work.
In terms of actual development and migration tasks, M2.7 is noticeably worse than its predecessor M2.5. On top of that, it outright refuses to continue a migration mid-task, which is clearly visible in the thinking output.
I ran the same tasks through 5.3-Codex, Claude 4.6, and GLM-5 — the results were in a completely different league.
This is absolutely unacceptable for a model marketed for code and development work.
Really thoughtful comparison from the perspective of real-world usefulness for agentic coding. It would be even better to have a short provider profile next to each model — for example, data retention, training on prompts, processing region, and a few basic security/compliance details. For many companies, that kind of context matters almost as much as the benchmark result itself.