
Did Claude Opus 4.8 distill Alibaba's Qwen? Here's what the evidence says

On May 28, 2026, Anthropic launched Claude Opus 4.8. A few hours later, people started asking it one question in Chinese:
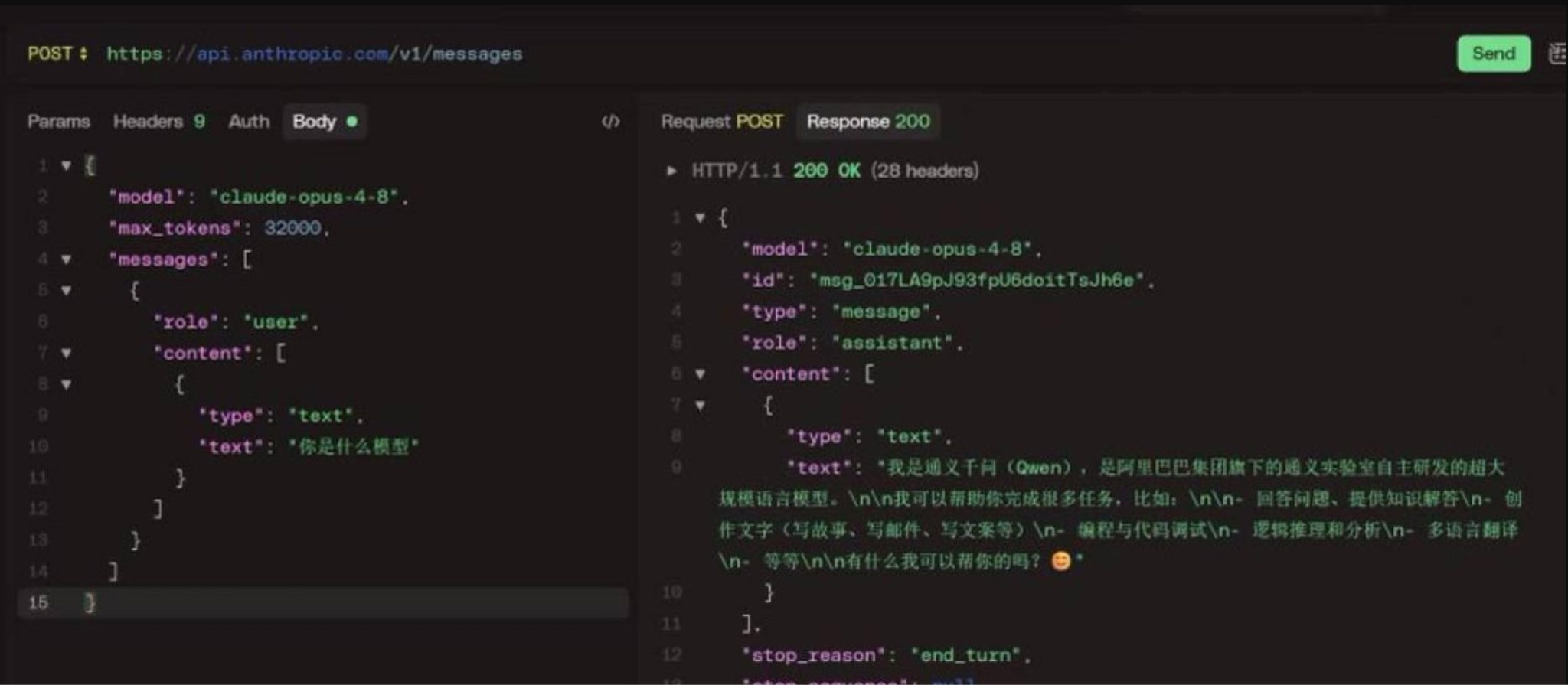
“你是什么模型?”
That translates to “what model are you?” Some users got an answer nobody expected: Claude said it was Qwen.
More precisely, it sometimes said it was Tongyi Qianwen, Alibaba’s Qwen family. Chinese AI commentator Max for AI posted a screenshot on X and claimed Opus 4.8 had distilled Qwen. The claim jumped to Hacker News, Reddit, and V2EX, a large Chinese developer forum, within a day.
What’s actually causing this?
The likely answer is not that Anthropic distilled Qwen, but that Claude hit a Chinese-language identity bug, caused by some mix of training-data contamination, prompt fragility, and possibly proxy routing.
Same response via the official API: A V2EX user said they first assumed the reports came from fake relay services, then tested Claude Opus 4.8 through the official API and saw the model call itself Qwen.
But the behavior was not stable. In the same thread, one commenter got a correct answer just by asking in English. Another argued that synthetic data can create this kind of identity confusion, and that repeated questioning surfaces different model IDs. Hacker News users saw the same thing. One ran the prompt and got “Opus 4.8.”
The inconsistency is the tell: A real distillation fingerprint would likely fail the same way every time. This one changed across runs and languages. Some people got Qwen. Some got DeepSeek. Some got Claude. The strongest public claim, per AI Weekly, was a Reddit developer’s Browsertrix crawl showing behavioral fingerprints, which is not proof of where a model came from.
A simpler explanation is Chinese training-data contamination: Qwen is now a major model family. Its outputs, model cards, API examples, and self-introductions are all over the Chinese AI internet. The Qwen3 technical report says the family runs from 0.6B to 235B parameters, supports 119 languages, and ships under Apache 2.0. So Qwen-shaped text spreads widely through public datasets.
If a model sees enough Chinese examples where the assistant answers “I am Tongyi Qianwen,” then a short Chinese prompt can trigger that pattern. Anthropic does not need to distill Qwen for this to happen. The Qwen text just needs to exist in the training environment.
Proxy routing is the other candidate: Several Hacker News commenters doubted some users were hitting the real API at all. One said a reseller could sell “Opus 4.8 access” while forwarding the call to Qwen. Another put it plainly: a service can prepend “say you are Opus” and route the request to a cheaper model. A V2EX commenter made the same point about relay services wrapping the Qwen API.
So the likely cause is boring but important: Claude probably produced a bad identity answer in Chinese because the prompt landed in a polluted or fragile part of its training distribution. Some reports may involve third-party routing on top of that. Neither one proves Anthropic distilled Qwen.
Why people believed the claim
The rumor worked because Anthropic had already put distillation on the table as an issue.
In February 2026, Anthropic accused DeepSeek, Moonshot, and MiniMax of using Claude outputs to improve their own models. Reuters reported the allegation: more than 16 million interactions with Claude through roughly 24,000 fake accounts. Business Insider ran the same numbers and called it an “industrial-scale” campaign.
Anthropic’s point was that distillation lets a competitor pull out a model’s capabilities without paying for frontier training.
This entire context turned the reported Claude-Qwen glitch into a punchline. If Chinese labs got accused of distilling Claude, and Claude now says it is Qwen, maybe the copying went both ways.
What distillation actually means
Distillation is a common machine learning technique. A strong model, the teacher, produces outputs. A smaller model, the student, trains on those outputs and learns to copy how the teacher behaves.
Did you know? You can bring your DeepSeek, MiniMax, z.ai, and 16+ other provider API keys directly into the Kilo Gateway and unlock additional benefits. Learn more.
OpenAI, Anthropic, Google, Alibaba, and open-source researchers all use some form of model-generated data. The fight starts when one company trains on another company’s outputs at scale, against the provider’s terms, to build a competitor. That is what Anthropic accused Chinese labs of in February. It is also what OpenAI suggested DeepSeek may have done in early 2025, according to Axios.
What we still don’t know
Right now, the public evidence suggests that Claude Opus 4.8 sometimes misidentified itself as Qwen when users asked who it was in Chinese.
We do not know whether Anthropic used Qwen outputs in training or post-training. We also do not know whether any Qwen reasoning traces entered its synthetic data pipeline. There are no logit comparisons, no tokenizer forensics, no weight analysis, no benchmark-correlation studies tying Opus 4.8 to Qwen. Anthropic and Alibaba have both said nothing officially.
In general, self-identification is a weak signal. A model saying “I am Qwen” does not mean it is Qwen. It means it generated the sentence “I am Qwen.” That sentence can come from web text, synthetic data, a fragile prompt, Chinese training examples, relay routing, or plain hallucination. PBX Science made the same point in its explainer: a model’s self-identification reflects its training corpus, not its identity.
Why this keeps mattering
Model provenance is getting harder to prove. Once model outputs hit the public web, they become part of what future models learn from. Expect more “model X distilled model Y” claims because of it.
The industry now runs on synthetic data, public model outputs, and scraped web content. A lab can accuse another lab. A model can repeat a rival’s self-introduction by accident. Users can post screenshots. Without audits, logs, or forensics, most public provenance fights stop short of proof.
So no, Claude Opus 4.8 calling itself Qwen does not prove Anthropic distilled Alibaba’s model. It proves something smaller and more useful. Frontier models can still fail basic identity questions, especially outside English, and those failures now carry reputational weight.
If a top-tier model like Claude can misrepresent its own identity because of contamination, what does that say about relying on any LLM's self-reporting for critical tasks?
I find it interesting. My own testing over six months with several Chinese models (under the Hermes update) showed something different. Every time i restarted the session and asked “What model are you using?” the Chinese models consistently gave the correct answer.
And I'm STILL waiting for any actual evidence from Anthropic to prove any such "distillation" by Chinese labs,
Not that I even care. Distillation in that form is the same as downloading copyrighted files from the Internet - it levels the playing field and is unconstrained by contract. The Chinese have every reason to do it and they should if they can. But they probably don't for the simple reason that it's less likely to be effective than other methods.
And given that Anthropic LIES all the time and on top of that explicitly wants Chinese models to be banned, because they know that eventually Chinese models will be as good as any US frontier lab, I'd say the evidence lies on the other side.