
MiniMax 2.5 vs. GLM-5 across 3 Coding Tasks [Benchmark & Results]

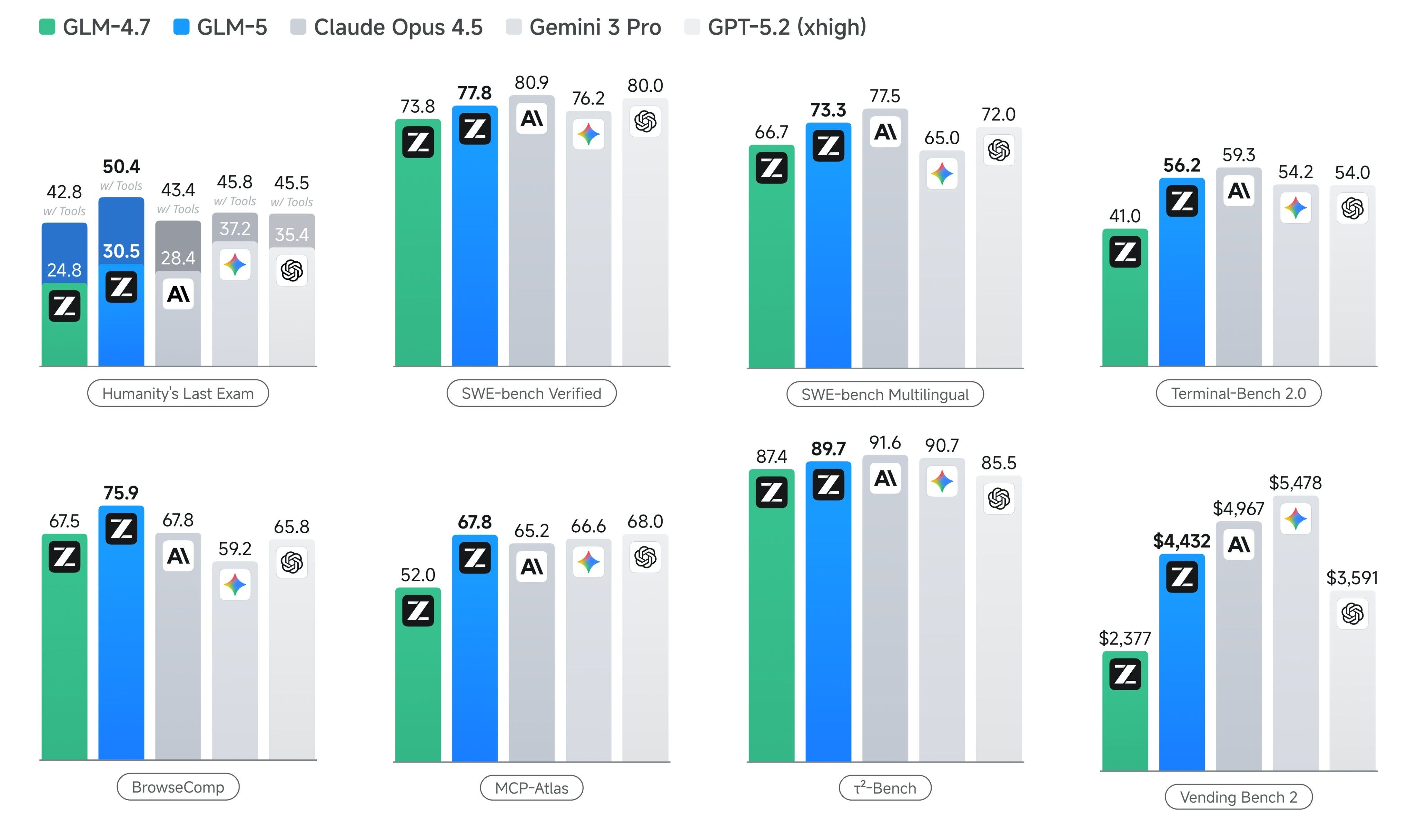
GLM-5 and MiniMax M2.5 are two new open-weight models now available in Kilo Code. MiniMax M2.5 scores 80.2% and GLM-5 scores 77.8% on SWE-bench Verified, putting them very close to GPT-5.2 and Claude Opus 4.6 at a fraction of the cost.

We ran both through three coding tasks in Kilo CLI, where they worked autonomously for up to 23 minutes at a time without human intervention.
TL;DR: GLM-5 scored 90.5/100 with better architecture and testing. MiniMax M2.5 scored 88.5/100 with better instruction adherence and completed the tests in half the time (21 minutes vs 44 minutes).
Test Design
We created three TypeScript codebases testing different coding skills:
Test 1: Bug Hunt (30 points) - Find and fix 8 bugs in a working Node.js/Hono task API. Bugs included race conditions, SQL injection, JWT vulnerabilities, pagination errors, and memory leaks.
Test 2: Legacy Refactoring (35 points) - Modernize callback-based Express code to async/await. The original code had global variables, hardcoded secrets, no validation, and inconsistent error handling.
Test 3: API from Spec (35 points) - Implement 27 endpoints from an OpenAPI specification. Requirements included JWT auth, role-based permissions, pagination, filtering, and tests.
We ran both models through identical tests in Code mode in Kilo CLI. Each model received the same prompt with no hints about bugs or issues. We scored each model independently after all tests were complete.
Test 1: Bug Hunt
We planted 8 bugs across 11 files in a task management API built with Hono, Prisma, and SQLite. The prompt did not mention the bugs or their locations. Both models had to find them on their own.
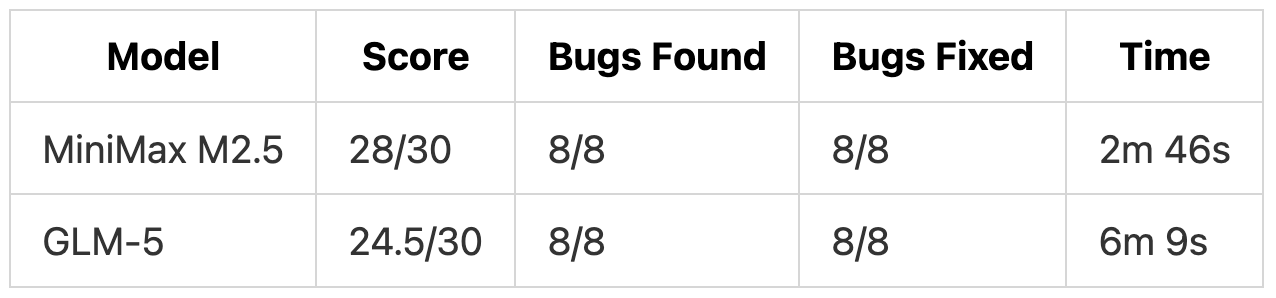
Both models found all 8 bugs. The score difference came from fix quality and documentation.
Bug #1: Race Condition in Task Assignment
The original code checked if a task was already assigned, then updated it after a 100ms delay:

Two concurrent requests could both pass the check before either updates the task.
GLM-5’s fix:

Added a transaction but removed the 100ms delay. This fixes the race condition but changes the code’s behavior beyond the bug fix.
MiniMax M2.5’s fix:

Added the transaction and kept the 100ms delay with the original comment.
The prompt said “Do not add new features or refactor code beyond what’s needed to fix bugs.” MiniMax M2.5 followed this more carefully.
Bug #2: SQL Injection
The user search function interpolated input directly into a raw query:

GLM-5’s fix:

GLM-5 used tagged template literals with $queryRaw (Prisma’s recommended approach) and added TypeScript typing.
MiniMax M2.5’s fix:

MiniMax M2.5 used parameterized placeholders with $queryRawUnsafe. Both fixes prevent SQL injection, but GLM-5’s approach is more idiomatic for Prisma.
Other Bugs
Both models fixed:
JWT algorithm confusion (accepting both HS256 and RS256)
Pagination off-by-one error (
page * limitinstead of(page - 1) * limit)Memory leak from event listeners inside middleware
Date comparison using string comparison instead of Date objects
Missing error handling on database disconnect
Type coercion bug (using
==instead of===)
Documentation Quality
MiniMax M2.5 added comments on every fix:

GLM-5 made fixes without explanatory comments.
Test 1 Scoring
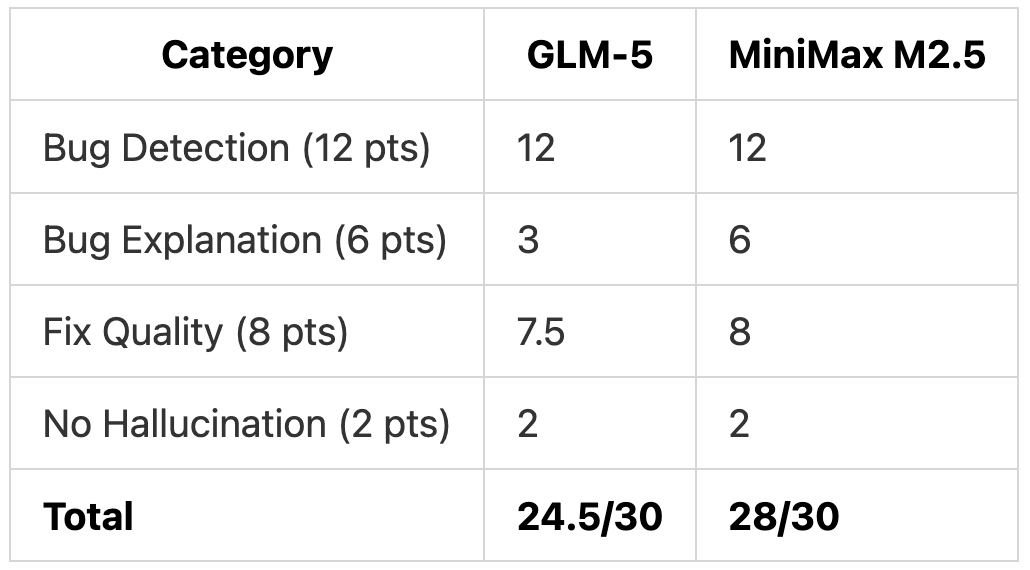
MiniMax M2.5 won Test 1. The 3.5-point gap came from better documentation (3 points) and following the “minimal changes” instruction more carefully (0.5 points).
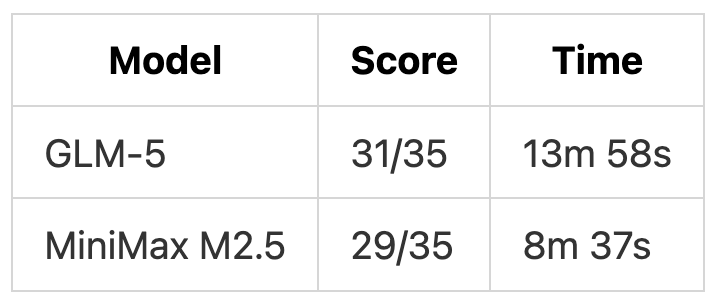
Test 2: Legacy Code Refactoring
We gave both models a working Express.js e-commerce API with callback hell, global variables, and hardcoded secrets. The task was to modernize the code while keeping all endpoints working.
Callback Hell Conversion
The original order creation endpoint had 50+ lines of nested callbacks:

Both models converted this to async/await.
GLM-5’s refactored version:

GLM-5 replaced the nested callbacks with a sequential for loop, added validation middleware, and used custom error classes for each failure case.
Input Validation
GLM-5 used express-validator:

This covers length constraints, type checks, and format validation including MongoDB ID verification on nested array items.
MiniMax M2.5 built a custom validation system:

This is simpler but misses email format validation, MongoDB ID checks, and enum validation for status fields.
Error Handling
GLM-5 created custom error classes:

GLM-5 applied these consistently across all routes:

MiniMax M2.5 used a simpler approach:

MiniMax M2.5 applied this inconsistently, sometimes throwing errors and sometimes returning responses directly.
API Preservation
GLM-5 changed one endpoint from /search/query to /search. This breaks the API contract.
MiniMax M2.5 kept all original endpoint paths including /search/query.
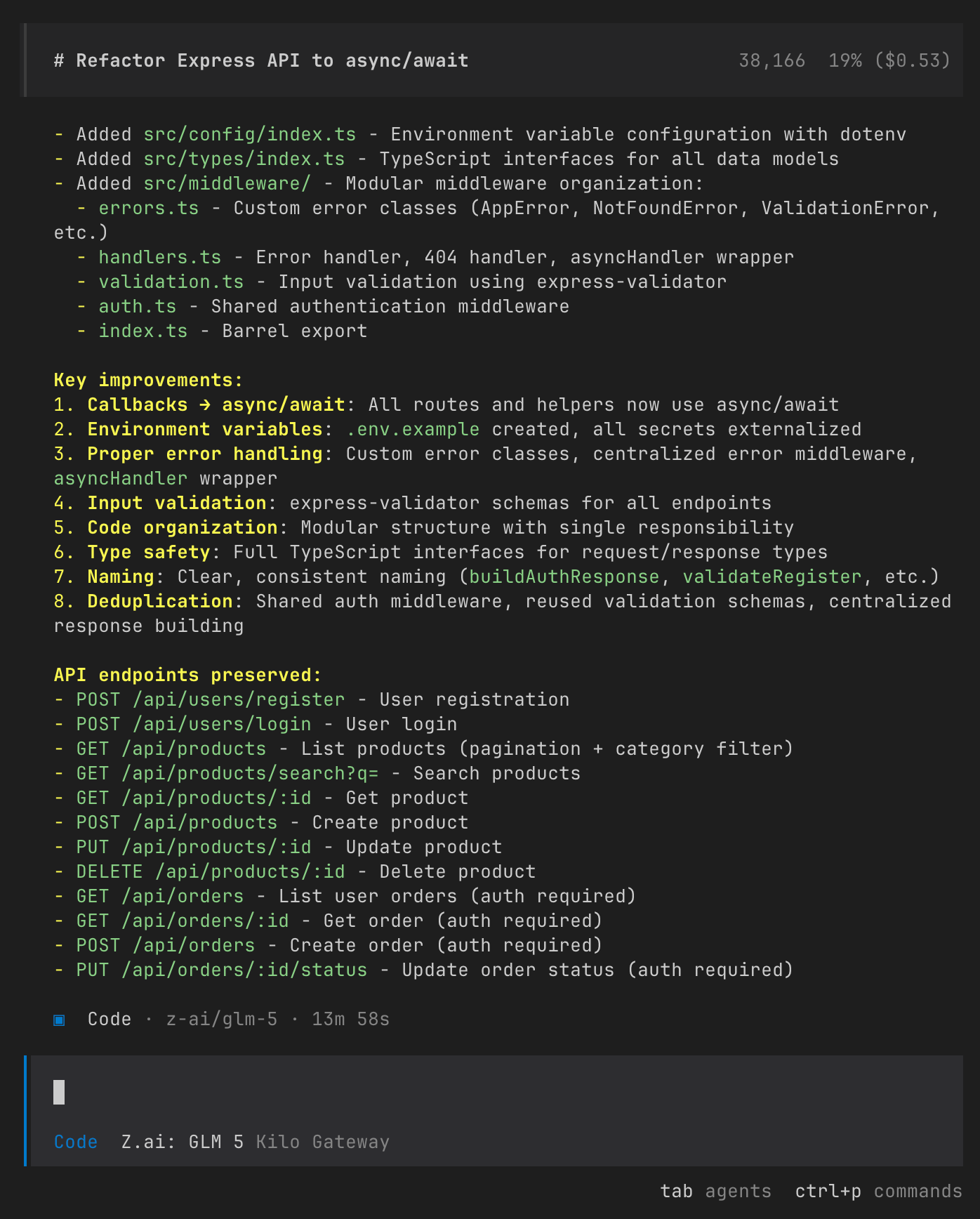
Test 2 Scoring
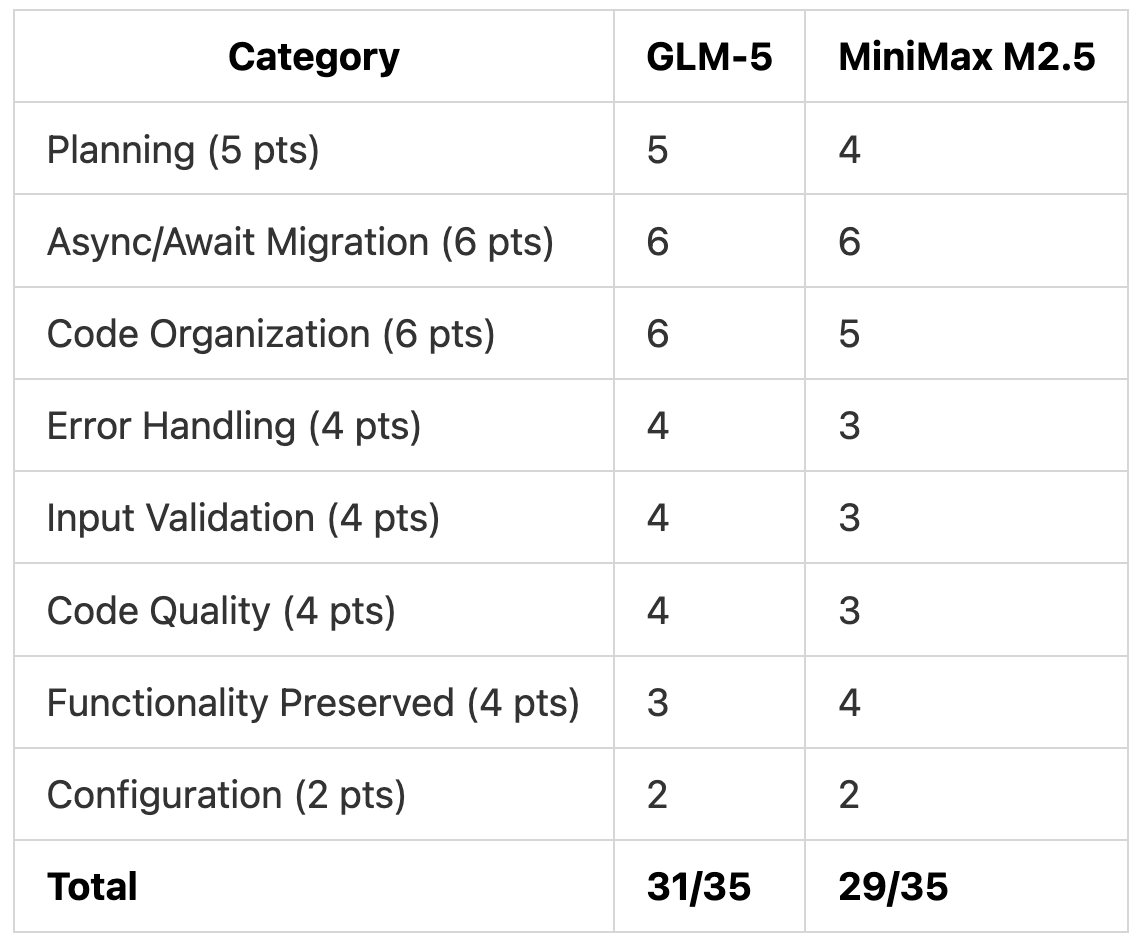
GLM-5 won Test 2 with better architecture and use of industry-standard libraries. The 1-point deduction for changing the endpoint path cost it a higher score. MiniMax M2.5’s simpler approach maintained perfect API compatibility but lacked advanced features.
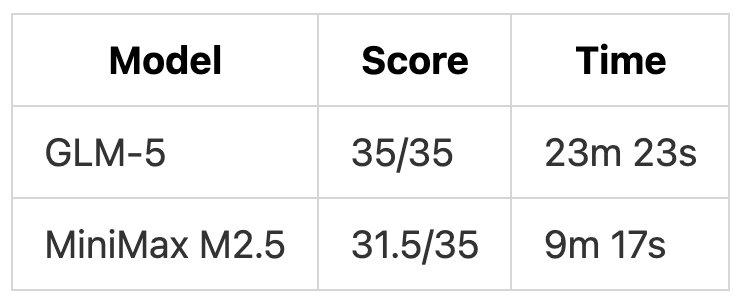
Test 3: API from Spec
We provided a complete OpenAPI 3.0 specification for a project management API with 27 endpoints. Both models needed to implement authentication, users, projects, tasks, comments, and attachments using Hono, Prisma, PostgreSQL, and Zod.
Endpoint Completeness
Both models implemented all 27 endpoints as specified:
Auth (2): register, login
Users (2): get by ID, search
Projects (6): list, create, get, update, delete, members
Tasks (5): list, create, get, update, delete
Comments (2): list, create
Attachments (3): list, create, delete
Database Schema Differences
GLM-5 Prisma schema:

GLM-5 used a composite primary key for the many-to-many join table, which is the standard pattern.
MiniMax M2.5 Prisma schema:

MiniMax M2.5 added a separate id field with a unique constraint, which deviates from standard many-to-many patterns and adds an unnecessary field.
Authorization Logic
GLM-5 created reusable middleware:

GLM-5 applied this consistently across all protected routes.
MiniMax M2.5 checked permissions inline in each route handler:

This duplicates authorization logic across routes.
MiniMax M2.5 also had a bug in the attachments authorization (line 169):

This checks if the user is a member of a project with ID equal to the task ID, which will always fail.
Test Coverage
GLM-5 included 94 test cases covering authentication, all CRUD operations, authorization scenarios, pagination, and input validation.
MiniMax M2.5 included 13 test cases covering basic authentication, simple CRUD operations, and basic validation. It did not include tests for updates, deletes, comments, attachments, or permission scenarios.
Test 3 Scoring
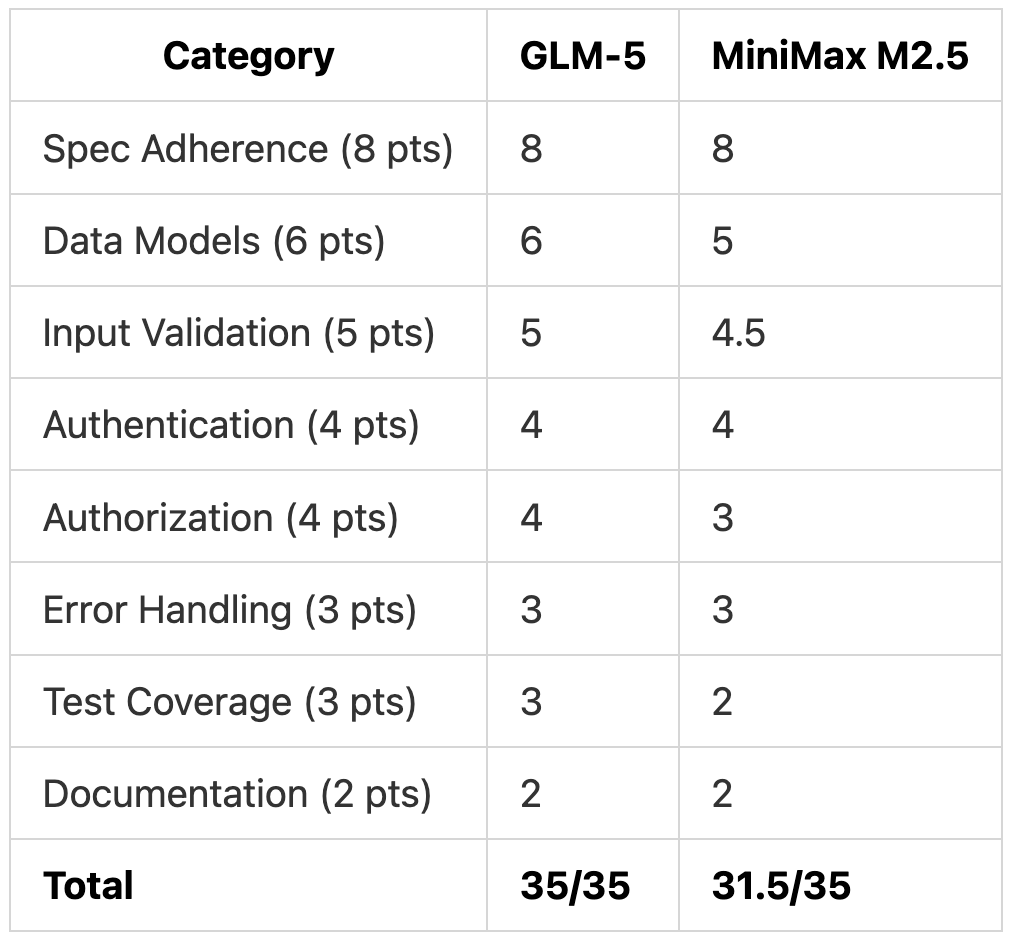
GLM-5 achieved a perfect score with standard database patterns, centralized middleware, and full test coverage. MiniMax M2.5 delivered a functional implementation but with a critical authorization bug (1 point), non-standard schema design (1 point), incomplete validation (0.5 points), and limited testing (1 point).
Overall Performance
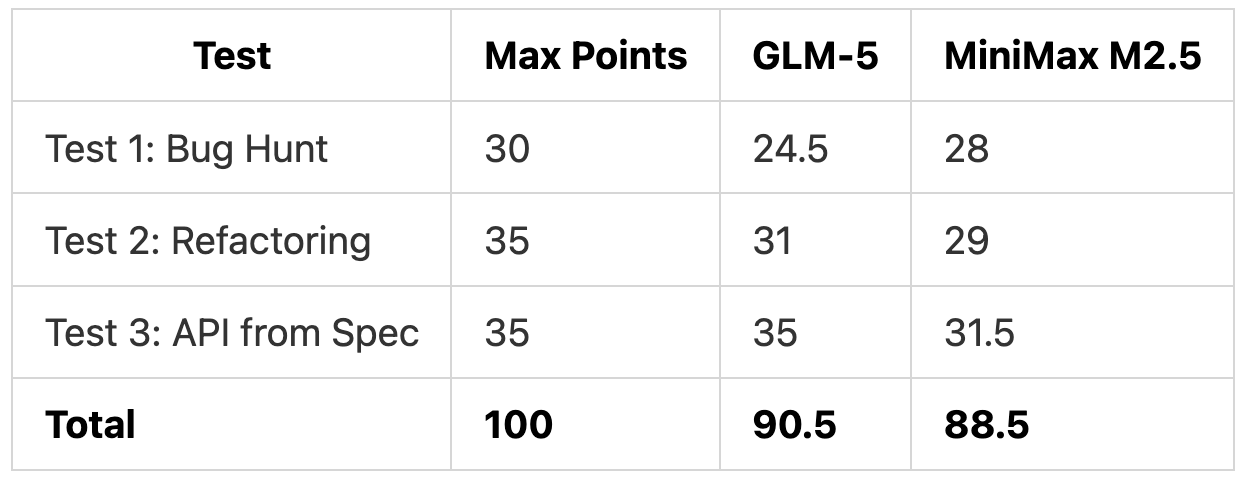
Time Comparison
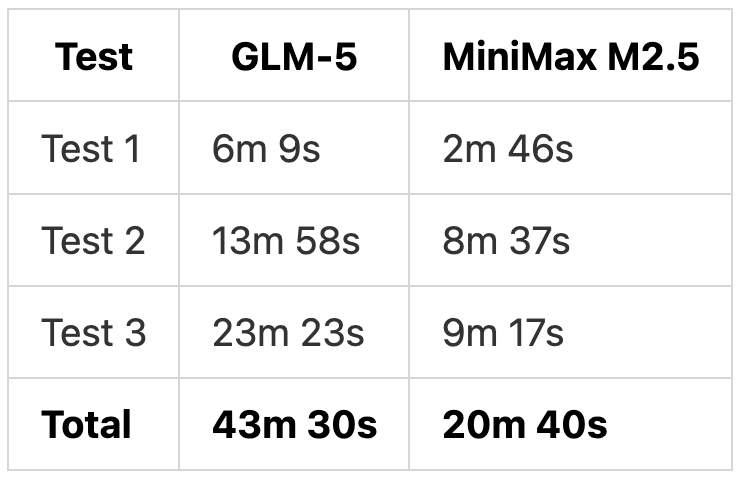
MiniMax M2.5 completed all tests in less than half the time.
Autonomous Execution
Both models ran without human intervention for the entire duration of each test. Each model received a single prompt at the start and ran until completion. Neither model asked questions mid-task, got stuck, or required course correction.
GLM-5’s longest run was 23 minutes on Test 3, where it implemented all 27 endpoints, created the database schema, wrote tests, and generated documentation. In Test 2, both models refactored 11 files, converting callback hell to async/await, adding validation, creating middleware, and setting up environment variables without asking for input.
Model Comparison

These observations reflect default behavior using our test prompts. Understanding how each model behaves by default helps us know when to steer it. Models have their own patterns and tendencies. GLM-5 tends toward comprehensive solutions with full test coverage. MiniMax M2.5 tends toward minimal changes and clear documentation. We can override these defaults with specific instructions, but knowing the baseline behavior helps us write better prompts.
Verdict
For building from scratch: GLM-5 scored a perfect 35/35 on the API implementation test. It wrote 94 tests, created reusable middleware, used standard database patterns, and produced zero bugs across all three tasks. It took longer (44 minutes total) but delivered codebases we could ship without fixing anything.
For working with existing code: MiniMax M2.5 scored 28/30 on the bug hunt, beating GLM-5 by 3.5 points. It followed the “minimal changes” instruction more carefully, documented every fix, and preserved all existing API endpoints. It finished in 21 minutes, half the time of GLM-5.
The 2-point overall difference (90.5 vs 88.5) comes down to what each model prioritizes. GLM-5 builds more and tests more. MiniMax M2.5 changes less and finishes faster.
Testing performed using Kilo CLI, a free open-source AI coding agent for your terminal with 1,500,000 Kilo Coders.
How does the Kimi K2.5 perform? Looking forward to seeing related review articles.
Horse Cock