
We Tested Grok, Opus, Sonnet, GPT, and Gemini in Kilo Code Reviewer
The $0.08 One Tied the Frontier.


We built an entire app from scratch with the bugs baked into the first commit, left everything uncommitted, and asked five popular AI models to review the working tree, cold.
The app is “Budget Harbor”, a client-side household budget planner in React, TypeScript, and Vite. It tracks accounts, category budgets, recurring transactions, and savings goals, and it handles CSV import and export plus an end-of-month forecast. It looks finished and even ships with a passing test suite. Underneath that we planted 15 bugs, from a one-line useEffect mistake to a forecast that quietly double-counts your rent.
Then we ran the same prompt against Grok Build 0.1, Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro, and Claude Sonnet 4.6.
TL;DR: Opus 4.8 caught the most at 10 of 15. The surprise was one rung down, where Grok Build 0.1 tied Sonnet 4.6 at 9 of 15 and gave the cleanest read on the hardest bug in the set, for less than a tenth of the Opus cost. Gemini 3.1 Pro was the letdown, missing a bug so obvious that every other model caught it. And four bugs got past all five.
Why a Budget App
Money math has one property most CRUD apps don’t: the answers aren’t up for debate. A contribution either adds to your goal or it doesn’t. A deleted transaction either reverses its effect on your balance or it leaves the balance wrong forever. A forecast counts your rent once or it counts it twice. There’s no design-judgment gray area for a weak review to hide behind.
So this was less a test of whether a model can spot a missing semicolon and more a test of whether it can track state that mutates in three different places and stay consistent about it.
The 15 bugs fall into six buckets:

The Prompt
Each model got the same instruction inside Kilo’s Code Reviews, run against the uncommitted tree:
“Review the uncommitted changes.”
No hint about where to look, no bug count, no nudge toward security or correctness. We wanted to see what each model surfaces when you point it at a diff and step back.
Results
“Issues found” counts everything a model flagged, including real problems we didn’t plant. Detection rate is scored only against the 15 planted bugs.
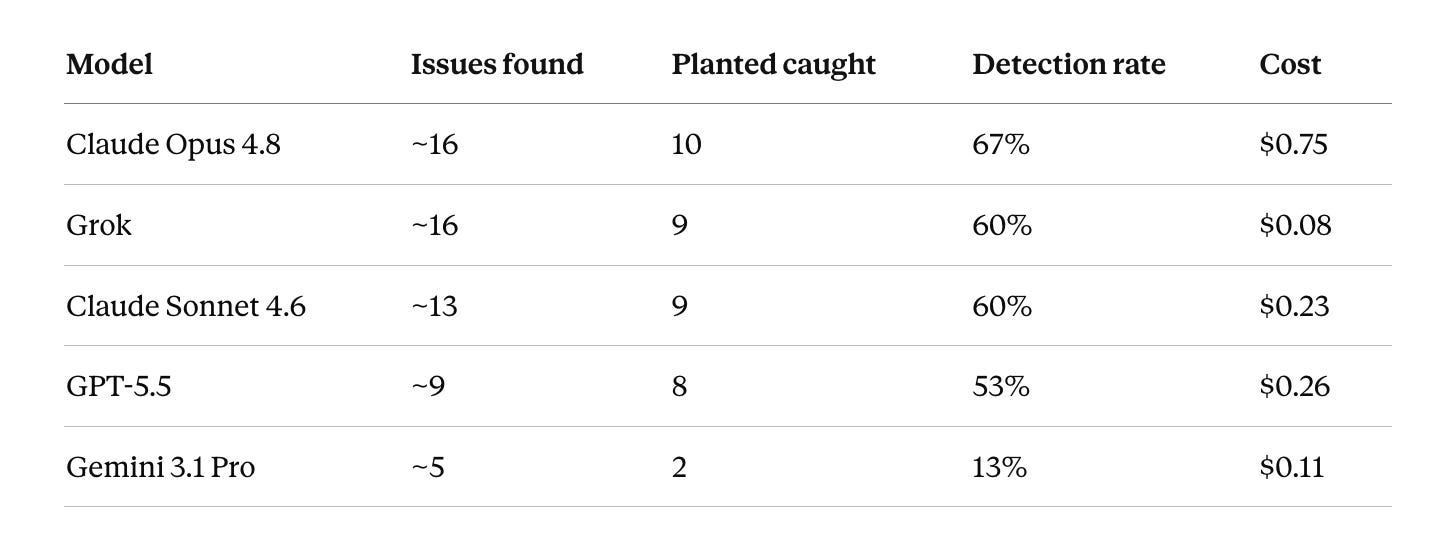
No model produced a false positive we could pin down. Everything flagged was a real problem, planted or not. The spread came from how deep each model dug and which kind of bug it was wired to see.
Detection by Category
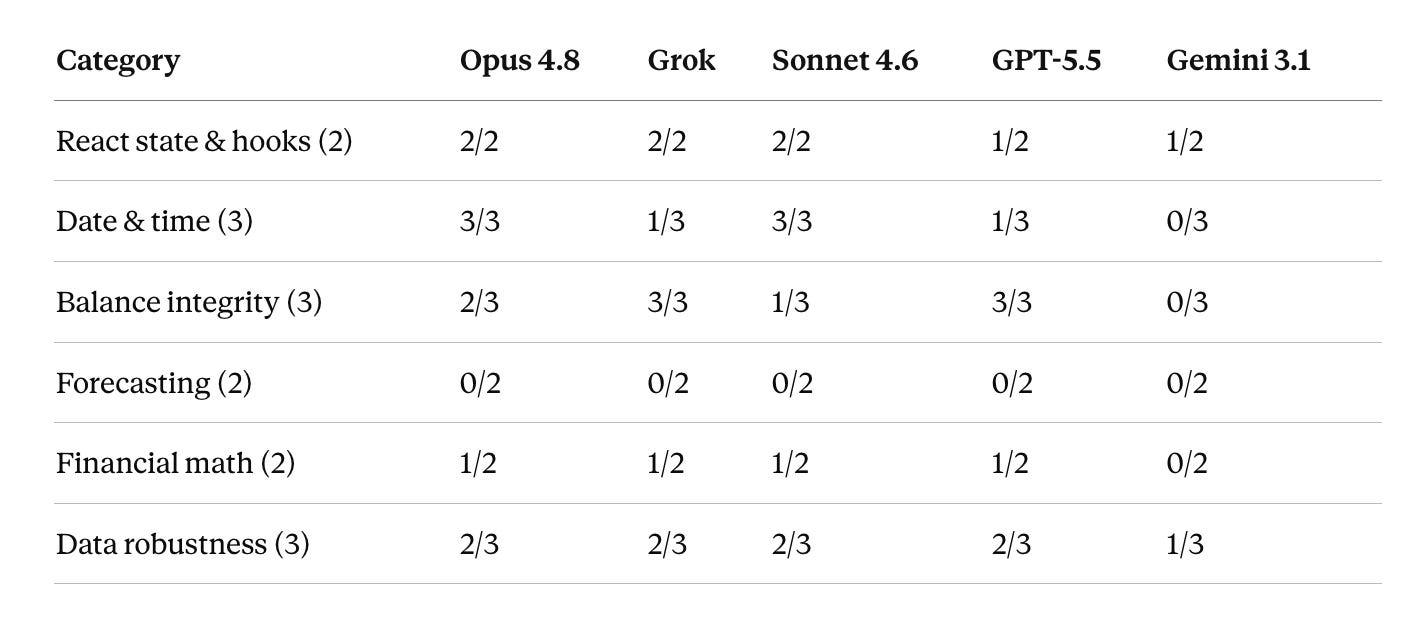
This is where the models show their personalities. Opus and Sonnet owned the date and time bugs nobody else could see. Grok Build 0.1 and GPT-5.5 were the only two to fully untangle balance integrity, and one of them costs eight cents. Forecasting was a clean shutout.
What Each Model Did Well
Claude Opus 4.8
Opus turned in the broadest review and the most careful one, catching both React bugs, all three date bugs, and two of the three balance bugs.
It also did arithmetic nobody else bothered with. It opened the test file, summed the sample transactions by hand, and reported that the committed expectations were off by exactly 200, so npm run test would fail. We hadn’t planted that, and it’s the kind of thing you usually only get from a human who decided to check the numbers. Verify it against your own sample data before trusting it, but the instinct to check is the point.
Opus nailed the subtle date bug too. getUpcomingRecurring builds dates with new Date(year, month, day), and since JavaScript months are zero-indexed but the app’s month strings aren’t, recurring transactions land a month late. Opus caught the off-by-one and explained that a May selection schedules into June.
Its one miss in the balance set: Opus reasoned cleanly about adds and imports but never noticed that deleteTransaction leaves the account balance untouched. One function short of the full picture.
Grok Build 0.1
Grok is the story here. It tied Sonnet at 9 of 15 on the cheapest run of the five, and it produced the best single finding in the test.
That finding is the account balance model, the hardest bug because it lives across three files and only breaks when state mutates in more than one place. Grok Build 0.1 pulled it apart in one item: addTransaction mutates the base balance, deleteTransaction never reverses that delta, and getAccountBalances then recomputes a projected balance as balance + sum(transactions) on top of the already-mutated number. It tied all three into one root cause, flagged the resulting double-counting and drift, and went further than any other model by prescribing the fix: derive balances from an immutable ledger, or move to event sourcing so the base balance is never mutated directly. No frontier model stated it that completely.
It also caught both React bugs, the goal inversion, the stale search memo, the unsafe CSV parser, the substring month match, and the corrupt-JSON crash, and its CSV note came with the right remedy rather than just pointing at the split(',').
Where it fell short was date math. It noticed getUpcomingRecurring but flagged it for leaking fake -next ids downstream instead of for the zero-indexed month bug, and it missed the monthKey timezone drift entirely. That’s the whole gap between Grok and a perfect date sweep. Everything else it touched, it got right, for eight cents.
Claude Sonnet 4.6
Sonnet also hit 9 of 15, but through the opposite strengths from Grok. It swept all three date bugs Grok missed, caught both React bugs, and flagged the goal inversion, the CSV corruption, the corrupt-JSON crash, and the deletion that doesn’t reverse the balance.
It also came closest to the APR bug everyone technically missed. Sonnet flagged estimateDebtPayoffMonths for silently returning a 600-month cap when the payment is smaller than the monthly interest. That’s the symptom, not the cause: feed 19.99 as a percent into a function expecting a decimal and the monthly interest balloons until no payment can dent it. Sonnet found the tripwire without naming the wire, which beat the other four.
Its gap was the rest of balance integrity. It caught the deletion bug but didn’t connect the projection layer re-applying every transaction on top of a mutated balance, which is the piece Grok and GPT-5.5 got.
GPT-5.5
GPT-5.5 was the other model to fully solve the balance contradiction, laying out the same three-way problem Grok did and explaining that new transactions hit the projection twice while deletes leave the balance permanently wrong. It also caught the goal inversion, the stale search memo, the CSV problem, the corrupt-JSON crash, and the off-by-one recurring schedule.
Its whiff was odd for a model this strong. GPT-5.5 never mentioned the useEffect with no dependency array, the most common React mistake in the file and one that both Grok and Gemini caught easily. It reasoned through cross-file state mutation, then walked past a textbook one-liner.
Gemini 3.1 Pro
Gemini is the one I keep coming back to, because the result doesn’t match the price. It caught two planted bugs, the useEffect dependency array and the CSV escaping. Its output was also the shortest by far, and it spent part of that budget on unplanted findings (a timezone issue in the form’s default date, the package.json pinning everything to latest) instead of the planted bugs sitting in plain sight.
The miss that gets me is the goal bug. The handler is labeled “Add contribution” and then subtracts the amount, so every contribution moves your progress backward. Grok caught it. Opus, Sonnet, and GPT-5.5 caught it. An eight-cent Grok run caught it. The model with a Pro in its name walked right past a bug that inverts the core action of a whole feature.
What All Five Missed
Four bugs survived every review, and they cluster in a telling way.
The forecast double-counts recurring transactions: forecastEndOfMonthBalance sums the recurring bills already recorded for the month and then adds the generated ones on top, so your rent gets counted twice. The same function treats credit-card debt as spendable cash, summing negative card balances into the total as if a maxed-out card were money you could spend down to. loadBudgetState reaches straight for window.localStorage, which throws in any SSR or test environment where window is undefined, and while three models caught the related corrupt-JSON crash, none caught the bare window access. And estimateDebtPayoffMonths does its interest math as if APR arrives as 0.1999 when the UI hands it 19.99, so the payoff numbers come out wildly wrong.
The bugs that survive aren’t the visible ones. They’re the bugs where the code is correct in isolation and only wrong if you know what the numbers are supposed to mean. Counting rent twice is valid arithmetic. Summing debt as cash is a valid sum. You only catch them if you understand how a budget is supposed to behave, and that intent is exactly what these models are still shaky on.
Cost vs Coverage
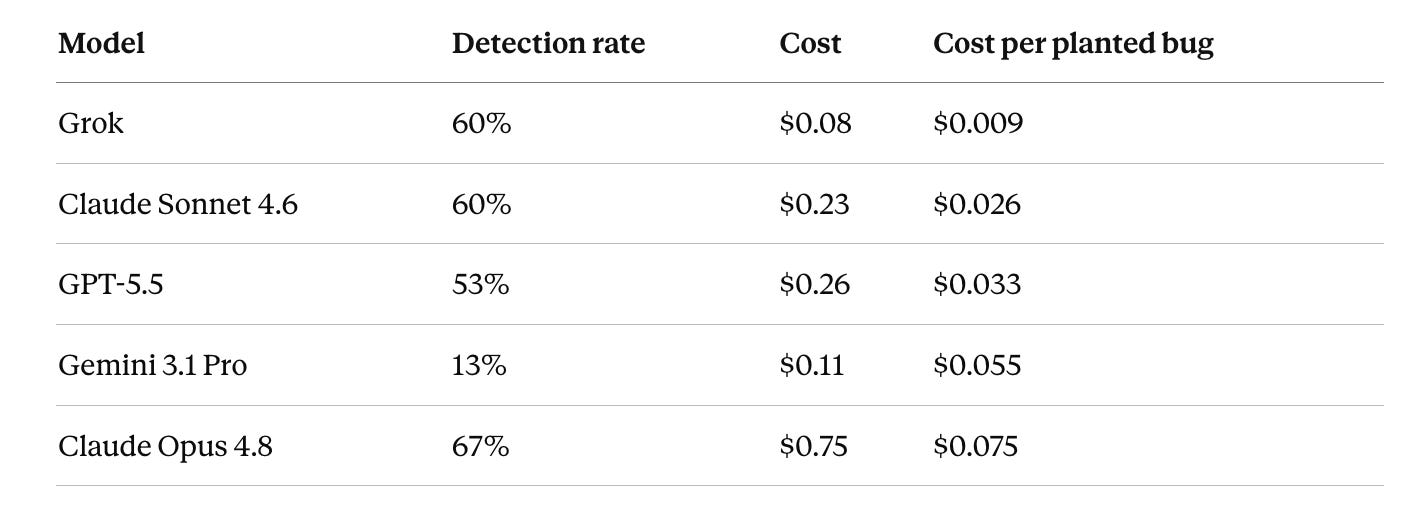
This is the table that reframes the test. Grok and Sonnet tie on coverage, but Grok gets there for a third of the price, which makes it three times cheaper per catch than the next model and nearly nine times cheaper than Opus. The usual tradeoff between cheap-per-bug and high-detection just doesn’t appear, since the cheapest model is also tied for second on what it found. Opus still buys the widest net, which is worth paying for when the review is your last gate before release. The floor for a useful review just came in much lower than expected.
Verdict
For the widest coverage on a correctness-sensitive change, Opus 4.8 is the call. It found the most, reasoned across files, and was the only model to check the test math by hand. When a review stands between you and shipping a balance-corrupting bug, the extra cost is cheap insurance.
For value, Grok Build 0.1 is hard to argue with. It tied the best frontier-tier model on detection, gave the most complete account of the hardest bug, and did it for under a tenth of the Opus cost. Its blind spot is date math, so if your code leans on timezones and recurring schedules, pair it with something that owns that.
That partner is Sonnet 4.6, which matched Grok Build 0.1’s score through the opposite strengths and came closest to the APR bug nobody fully cracked. Grok plus Sonnet would have caught 11 of 15 between them, more than any single model managed.
GPT-5.5 still brings real reasoning for data-flow-heavy code, since it untangled the balance contradiction same as Grok. Just don’t run it alone, given it skipped a basic React mistake the cheaper models caught.
Gemini 3.1 Pro is the one to test against your own code before relying on it. Missing a feature-inverting bug that an eight-cent model caught should change how much you trust a single-model review.
Which lands where the last test did, with a twist. One model is a screen, not a verdict, and the best move is still two models with different strengths or a frontier model plus a careful human pass. The twist is that “frontier” and “best at the hard bug” turned out not to be the same thing. The bugs that need real domain understanding are still the ones you have to catch yourself.
Testing performed using Code Reviewer, a feature of Kilo, the all-in-one, open-source agentic engineering platform with IDE extensions for VS Code and JetBrains and a CLI. Pick from 500+ models, pay per token at provider cost, and switch whenever you want. Join the 1M Kilo Coders building at Kilo Speed.
Which Grok model is reviewed here?
Any chance you might make the app used for the review process available so that other models can be tested / compared against the known results?