
New Models from StepFun and MiniMax Are Sending the Internet into a Tailspin
And one of them is currently free in Kilo

Model releases are coming at us faster than ever. Over the weekend, StepFun and MiniMax, two of the most prevalent Chinese model labs, dropped exciting new releases: Step 3.7 Flash and MiniMax M3.
To make things ever more intense: both labs released these new models out of the gate with open weights. The new StepFun model comes with a permissive Apache 2.0 license and MiniMax is expected to release the weights for M3 shortly.
The internet is already buzzing—our community Discord and X feeds are in a tailspin over the agentic capabilities, massive context windows, and raw speed these models are bringing to the open-weights arena.
These releases couldn’t come at a more exhilarating time as the “model wars” heat up and users everywhere are benefitting from the rapid improvements in both intelligence and efficiency. Last week, just as xAI’s Grok Build 0.1 was hitting new heights as a trending topic, Anthropic dropped Claude Opus 4.8 (currently available in Kilo at an exclusive 20% discount).
Then the weekend saw StepFun and MiniMax pushing conversations back to cost-efficiency and the strength of building with open weights. The Chinese labs are improving faster than ever.
The “Flash” Era is Here
Before we dive into the specs, it’s worth noting the massive industry shift we’re seeing toward high-efficiency, low-latency “Flash” models. Ever since Google set the gold standard with Gemini 3.5 Flash, the demand for incredibly fast, cost-effective reasoning at scale has skyrocketed. Gemini 3.5 Flash proved that you don’t need to sacrifice deep reasoning or multimodal capabilities to get blazing-fast time-to-first-token. Now, we are seeing elite open-weight labs answer the call, leaning into sparse attention and Mixture-of-Experts (MoE) architectures to deliver Flash-tier speed and unit economics for developers everywhere.
Here is everything you need to know about the new heavyweights on Kilo.
Step 3.7 Flash - FREE in Kilo
StepFun has officially entered the Flash wars, bringing their highest-efficiency multimodal Mixture-of-Experts (MoE) models to Kilo. Step 3.5 was already a hit on Kilo, but the lab has made a leap directly to 3.7 Flash. This benefits everyday developers, and even better—Step 3.7 Flash is totally free in Kilo for a limited time.
Step 3.5 and the newly unveiled Step 3.7 Flash pair a massive 196B-parameter language backbone with a dedicated vision encoder for native image and video understanding. Despite the massive parameter count, it sparsely activates only roughly 11B parameters per token, keeping it incredibly speed-efficient even at long contexts. In overall performance, it’s a slight improvement on Step 3.5 Flash, showing a two percentage point gain on KiloBench (33% vs 3.5’s 31%).

Key Features:
256K Context Window: Perfect for deep document analysis and long-context productivity.
Selectable Reasoning Levels: The model exposes high, medium, and low reasoning tiers, allowing callers to dynamically trade off speed, cost, and depth of “thinking” tokens based on the task.
Agentic Workflows: Purpose-built for coding, structured outputs, and complex tool-calling environments.
Early testers are raving about how well the model balances deep reasoning with “Flash-like” speeds, making it a top contender for persistent agentic loops. Social channels like X were immediately blowing up with users overwhelmed by the speed and efficiency, for both long-running cloud tasks and for running agents locally (some said they were changing their local setup from Qwen 3.6 27B to Step 3.7 Flash). Some noted some initial issues with tool calling, but did say that StepFun’s new model is “as good as Gemini Flash 3.0 at half the cost”.
StepFun Flash is TOTALLY FREE on Kilo for a limited time! To celebrate the launch and let our community push these architectures to their limits, we are dropping the API cost to absolutely zero.
API Pricing (for future reference) is just $0.20/M Input, $1.15/M Output, and $0.04/M Cache Read.
Affordable. And efficient. But for now it’s even more affordable: FREE in all of Kilo. Get it while it’s free!
MiniMax-M3: A Frontier-Class Triple Threat
But a big fish was released over the weekend, too. And it’s really turning heads.
MiniMax-M3 is nothing short of a frontier-class foundation model. It is the first open-weight model to unite the three capabilities defining today’s frontier in a single system:
A massive 1M-token context window.
Frontier coding and agentic performance.
Native multimodality.
MSA is the “magic under the hood” here. M3 is powered by a groundbreaking architecture called MiniMax Sparse Attention (MSA). This simple, scalable new sparse-attention design turns context length into a genuine scaling dimension. By replacing the quadratic cost of full attention with precise KV-block selection, MSA cuts the per-token compute at 1M context down to roughly 1/20th of the previous generation. Early reactions from developers have highlighted the staggering speed—delivering over 9× faster pre-filling and 15× faster decoding while matching full attention capabilities.

Trained from step zero as a native multimodal model on interleaved data scaled to the 100T-token range, M3 isn’t just a single-turn executor; it’s a multi-turn, long-horizon partner tuned via an interactive user-simulator framework.
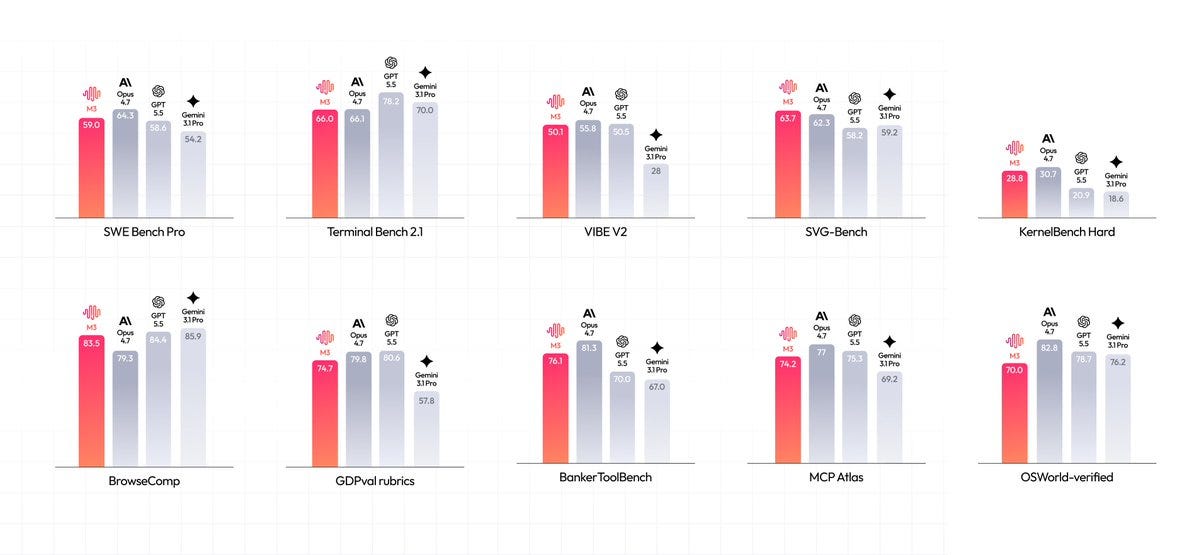
M3’s agentic performance is setting a new open-weight standard, and sees the lab catching up to some frontier performance. X has been heating up with discussion of users chatting about how they are starting to substitute MiniMax for frontier models, especially around large-scale agentic coding tasks, and the benchmarks support this view:
SWE-bench Verified: 80.5%
SWE-bench Pro: 58.0%
Terminal-Bench 2.1: 66.0%
BrowseComp: 83.5%
KiloBench: 48%
API Pricing for MiniMax M3:
0–512K Context: $0.60/M Input | $2.40/M Output | $0.12/M Prompt Cache Read
512K+ Context: $1.20/M Input | $4.80/M Output | $0.24/M Prompt Cache Read
As always, there’s no no upcharge in Kilo. You pay the same API prices as we do. And with Kilo Pass, you get major savings on top of list price.
Start Building Today
These releases mark a pivotal moment for open-weight AI. Whether you want to build a long-horizon coding agent with MiniMax-M3 or test the rapid-fire MoE capabilities of StepFun Flash, the endpoints are live and ready.
Head over to your favorite way to use Kilo, whether that’s the Kilo CLI or our VS Code extension, and let us know what you build!