
Martian's Independent Benchmark Tested 13 Code Review Tools
Here's Where Kilo Landed

Last week, Martian released Code Review Bench — the first independent, open-source benchmark for AI code review tools. It tracks over 200,000 real pull requests across GitHub, measures which review comments developers actually act on, and updates daily. The methodology and code are fully open source.
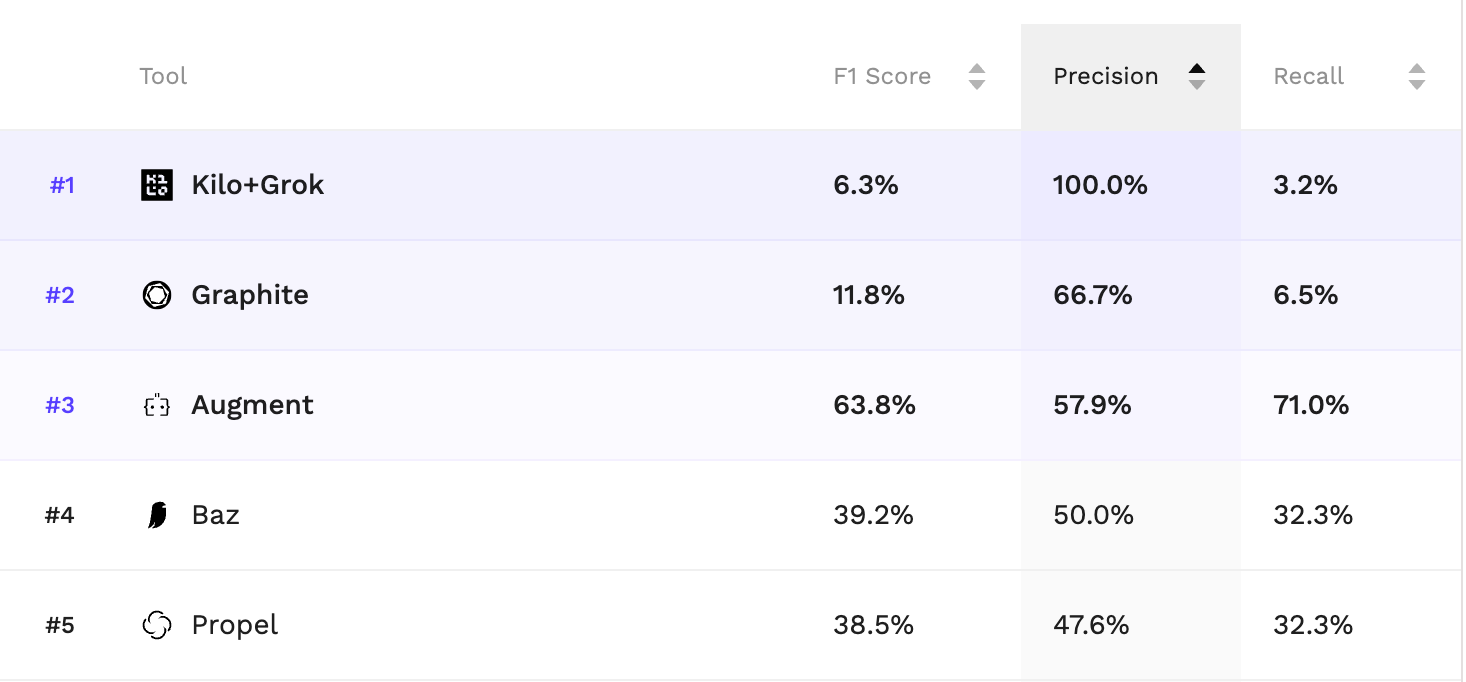
Kilo’s Code Reviewer ranked as the #1 open source code review tool across all values of beta. Whether you optimize for low noise (precision) or high thoroughness (recall), Kilo is the best open source option on the board.
Why This Benchmark is Different
If you’ve been around the AI benchmarking space, you know the pattern: a benchmark launches, tools optimize for it, it becomes less reliable. SWE-bench went through this cycle three times before OpenAI recommended everyone stop reporting scores entirely. Frontier models had memorized the gold patches. Over half the unsolved problems had broken tests.
Martian’s Code Review Bench was specifically built to avoid this. It works on two levels:
The offline benchmark runs every tool on the same set of 50 curated PRs with human-verified issues and scores them against a gold set. This gives you the controlled, apples-to-apples comparison.
The online benchmark is the reality check. It continuously collects data from code review tools operating in open source repos and tracks which comments developers actually fix versus ignore. When the offline rankings diverge from what’s happening in the wild, that’s the signal something is off.
The benchmark evaluates tools including CodeRabbit, GitHub Copilot, Cursor, Gemini Code Assist, Augment, Qodo, Graphite, Baz, Greptile, and Kilo — among others. It measures precision (are the tool’s comments actually useful?) and recall (does the tool catch the real issues?), and uses an adjustable F-beta score so you can weight the tradeoff however you want.
Open Source Competing with Closed Source
This is the part we find most interesting.
The code review space has historically been dominated by closed-source, proprietary tools. Kilo’s Code Reviewer is open source. You can see how it works, configure it for your team’s priorities, and choose which model runs the review from 500+ options.
The fact that an open source tool is leading the OSS category on an independent benchmark — built by a research lab with no stake in who wins — is a signal.
And this tracks with what we’ve been seeing in our own testing. When we tested three free models on Kilo’s Code Reviewer last December, Grok Code Fast 1 caught all five planted security vulnerabilities and matched the detection rate of frontier models. When we followed up with frontier models, GPT-5.2 found the most issues overall, but the gap between free and paid was smaller than anyone expected. The common thread: the model matters, but the review system matters just as much.
Kilo’s Code Reviewer lets you choose the model. That flexibility is part of what makes it work. You can run Grok Code Fast 1 for free screening on every PR, then escalate to Claude Opus 4.5 or GPT-5.2 for security-sensitive changes. One tool, any model, configured to your workflow.
Try It
Kilo’s Code Reviewer runs automatically the moment you open a PR. You can configure the review style, focus areas, and which model runs the analysis. It’s available now for any GitHub repository.
Set it up from the Kilo Dashboard, or check out the Code Review Bench results for yourself.
Kilo is the free, open-source, end-to-end agentic engineering platform with IDE extensions for VS Code and JetBrains. Join the over 2M Kilo Coders already building at Kilo Speed.