
Inside Kilo Speed: The Engineer Behind Every Model in Kilo Code

One of the things we’re most proud of at Kilo Code is model freedom: you can choose from 500+ models—frontier or specialized, closed or open source—with new ones added almost every week. The person behind all those model integrations with Kilo is software engineer Christiaan Arnoldus.
When a new model ships, Christiaan is behind the scenes assessing API changes, identifying what needs updating across which layers of the application, and shipping support quickly enough that users aren’t waiting while the rest of the industry has moved on.
Christiaan might not have a product area, feature, or roadmap to work on, but Kilo Speed is of the essence when a new model preview drops. Even so, Christiaan is a self-described skeptic when it comes to new AI capabilities, so if you’ve been hesitant to adopt more agentic engineering practices, he’s a good yardstick for separating hype from true utility.
Before joining Kilo last May, Christiaan spent years at a previous employer, where the team shipped just three times a year. The question that now structures most of his working day is one that wouldn’t have made much sense there but is critical at Kilo: what’s mine to do, and what can I hand off to agents?

It Starts With Triage
Christiaan is based in the Netherlands, which means his mornings often start with a backlog. Model providers are largely US-based, and announcements or access grants that arrive in their afternoon are waiting for him when he wakes up. Occasionally one announces a preview model available for testing, with feedback expected in just 48 hours.
For each piece of work, Christiaan runs through a few questions before deciding how to handle it. Is the task localized enough that an agent won’t start touching unrelated parts of the codebase—if you ask it to rename something, might it rename a bunch of unrelated stuff too? Does enough prior art exist for an agent to reason from, or is this at the frontier of what’s been documented anywhere? And if the output is wrong, how recoverable is that?
For work that passes those checks, cloud agents handle the background queue: a docs update, a small missing feature, a bugfix that started with an @Kilo mention in Kilo for Slack.
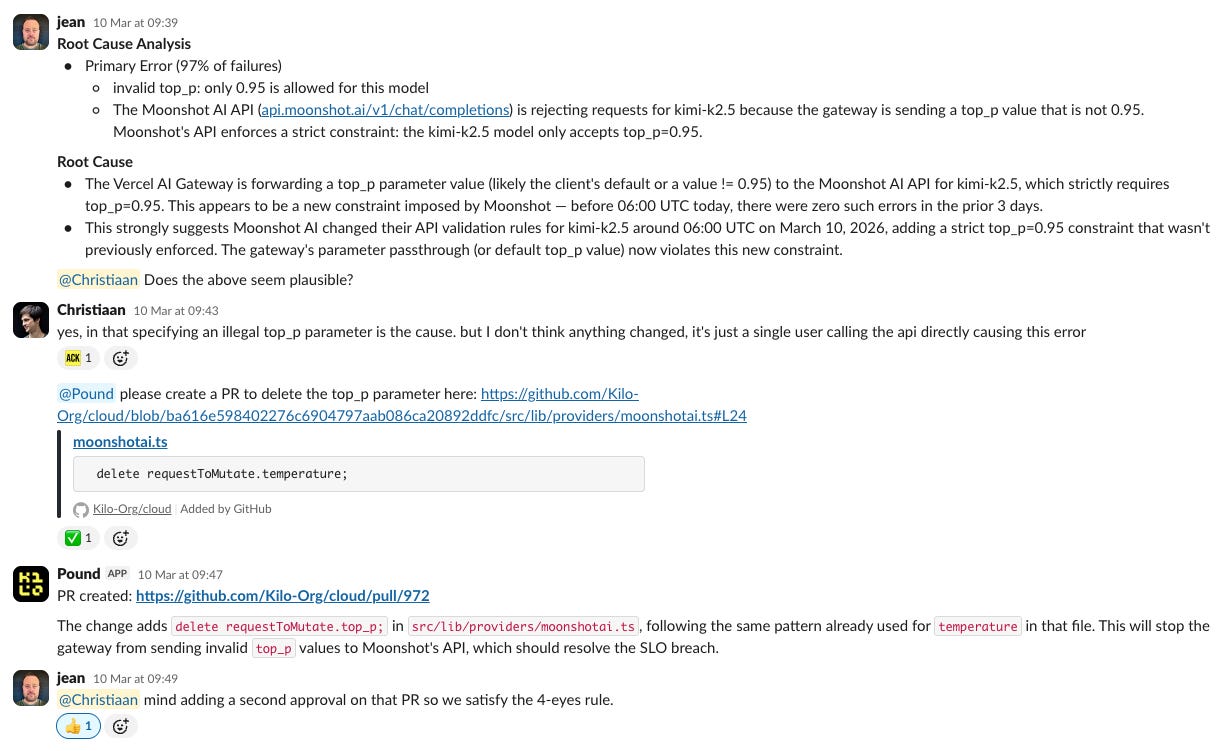
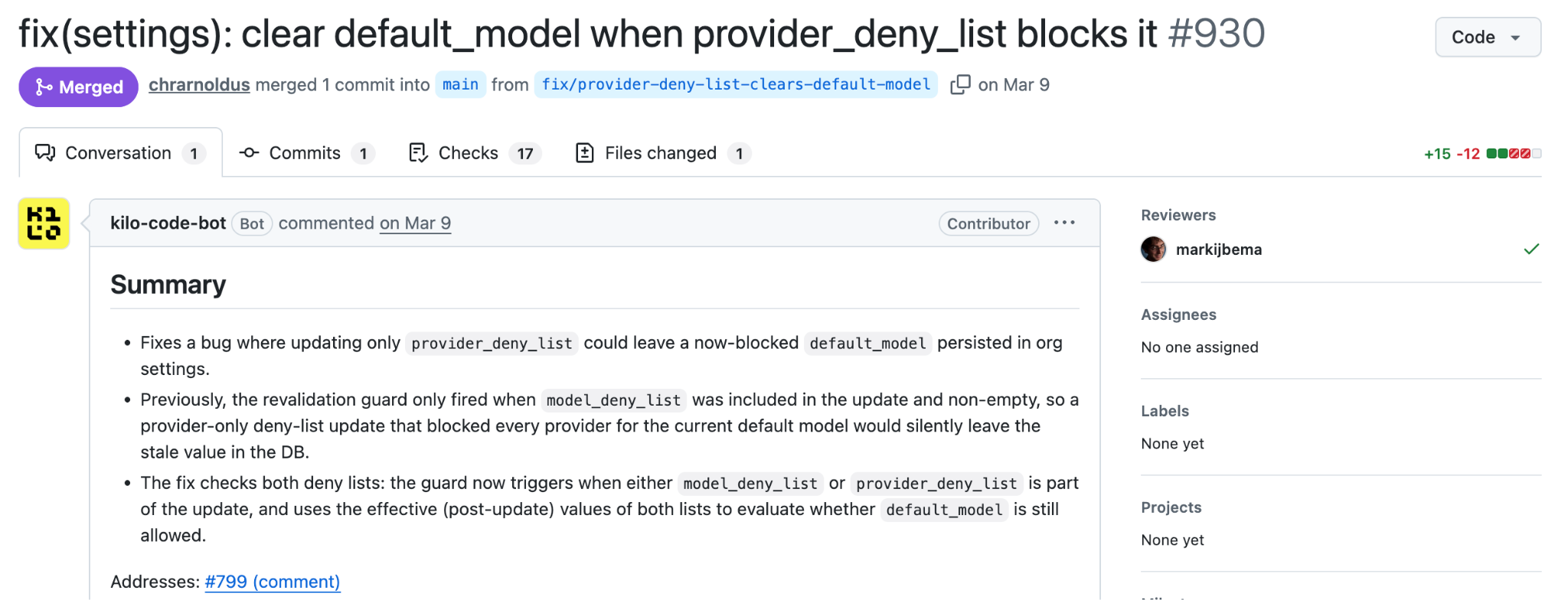
Tasks that previously required a context switch—checking out a branch, making a change, then remembering to come back—now run while he works on something harder. “Before, small irregular tasks would often take a lot of time and take me out of my flow or be forgotten,” he says. “Now I can have these run in the background, which feels a lot more productive.”
With more complex tasks, Christiaan likes to start in our Cloud Agent web app, which has the advantage of avoiding disturbing the work he’s busy with on his own computer.
“If a task involves certain business-critical things like usage accounting, I am personally hesitant to go all in on using AI there,” Christiaan says. “You can get some stuff done with AI in smaller steps, but then you have to be careful that it gets human review.”
Christiaan, like his teammates, is the mini-CEO of his domain. Operating mostly alone, he does run into challenges where in a traditional org you might turn to another expert on the team—a database specialist, or someone close to the documentation. Christiaan’s default is to put the agent in that role first: give it the codebase to explore and see what it surfaces. Human expertise is a last resort rather than the first.
Where Agents Can’t Help (Yet)
The harder work—the investigation phase that precedes any integration—still belongs to Christiaan.
Most of Kilo’s models route through OpenRouter, which provides a uniform API layer that handles discrepancies between providers. Routine model additions are relatively straightforward, but early-access integrations are different. When a lab provides preview access under NDA, there’s no OpenRouter abstraction, public documentation, or community knowledge to reference. Christiaan has to assess the API format himself, identify where it diverges from anything already in the codebase, and work out how to handle the delta—sometimes in hours.
Agents aren’t well-suited to that work, especially where there’s incomplete (or non-existent) documentation and novel patterns to contend with. In these cases, an implementation that appears plausible but is actually wrong just creates more work than it saves.
For example, when GPT-5.4 launched, it introduced a new required field in API calls that meant replacing Kilo’s existing Chat Completions format with the newer Responses API. The change touched the API layer that underpins every Kilo feature—including usage accounting—which ruled out a fully agent-driven approach. “Generating hard-to-review code is not appropriate here,” Christiaan says. But because the two API formats are broadly similar, there were still opportunities to use agents to speed up specific parts of the work. It’s not always a binary choice between full delegation and full manual effort, but more commonly a judgment call about which parts of a larger task are safe to hand off.
Christiaan’s approach to delegation is based on experience: early in his time at Kilo, he sometimes leaned harder on AI-generated code than a task warranted, and ended up spending more time debugging the output than a more deliberate approach would have required. Instead of just using agents less overall, the lesson he learned was to be more precise about when they are the right tool. This can be harder to calibrate than it sounds when everything is moving fast and there’s always something new to try.
The Skeptic’s Approach
When your work focuses on making the latest new model available to use, it would be easy to get swept away by hype, but Christiaan is skeptical by default—new capabilities, he’s noticed, tend to be announced in a way that makes them sound more impressive than they turn out to be. His bar for adopting something new is whether it reduces friction in work he’s already doing.
In his time at Kilo the tooling he uses has evolved with the development of Cloud Agents, Kilo for Slack, and direct orchestration for larger tasks, but the underlying approach hasn’t changed much: delegate the routine, tightly scoped tasks, and keep the sensitive work close. This conservative-looking workflow is more demanding than it appears: you have to know enough about every layer of the system to know exactly which parts an agent can touch safely, and which ones you can’t afford to get wrong.