
We Tested Three Free Models on Kilo's AI Code Reviews

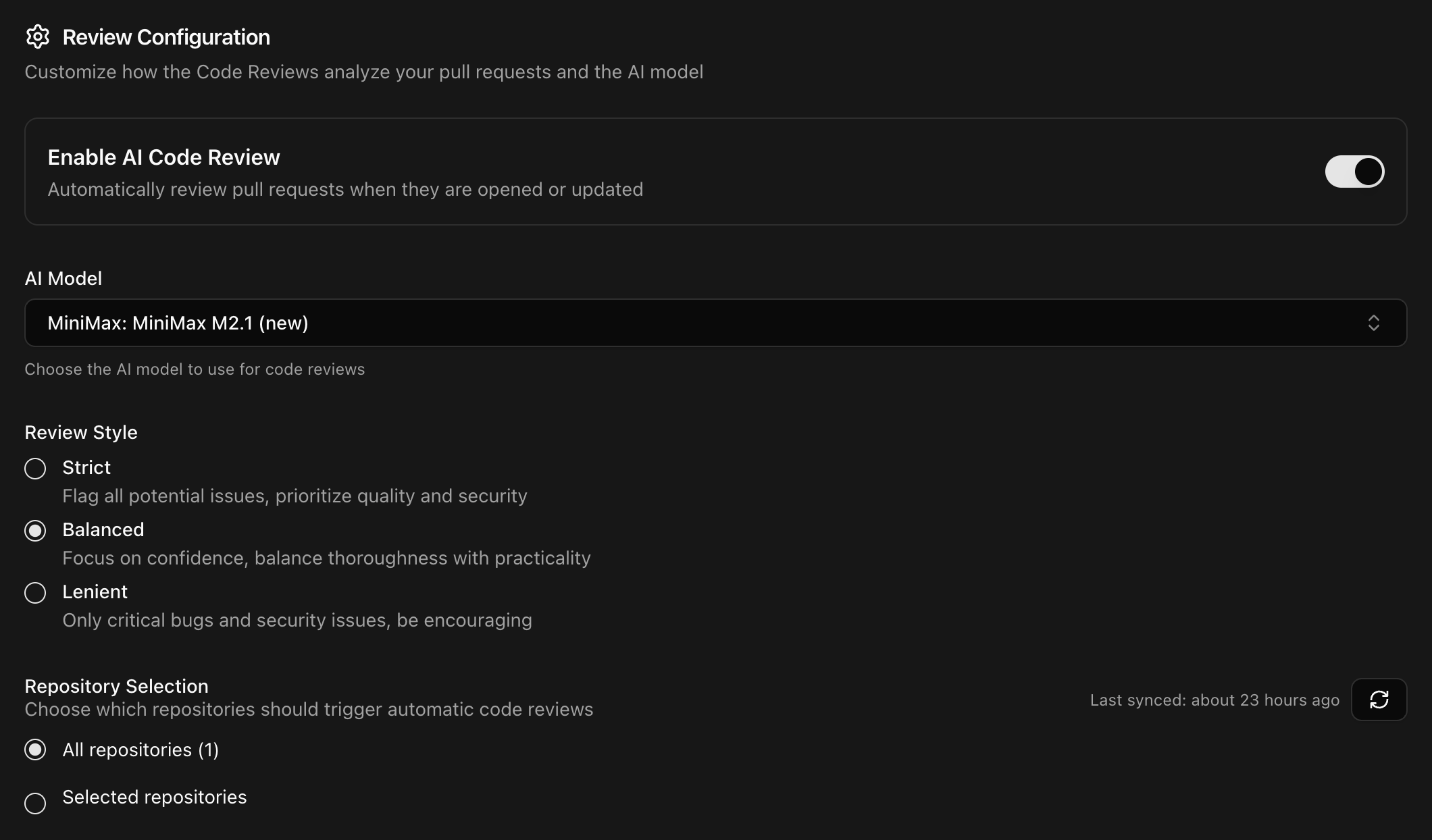
Kilo Code can now review your pull requests automatically. Our Code Reviews agent runs AI-powered analysis on every PR and posts findings directly in GitHub.
We picked three models currently free in Kilo Code: Grok Code Fast 1, Mistral Devstral 2, and MiniMax M2, and ran each through Code Reviews on a test PR containing planted issues.
TL;DR: Grok Code Fast 1 found the most issues (8) in 2 minutes with zero false positives. All three models caught critical security vulnerabilities, with MiniMax M2 standing out for inline code fixes and Mistral Devstral 2 for consistency checks.
Testing Methodology
We built a base project using TypeScript with the Hono web framework, Prisma ORM, and SQLite. The project implements a task management API with JWT authentication, CRUD operations for tasks, user management, and role-based access control. The base code was clean and functional with no intentional bugs.
From there, we created a feature branch adding three new capabilities: a search system for finding users and tasks, bulk operations for assigning or updating multiple tasks at once, and CSV export functionality for reporting. This feature PR added roughly 560 lines across four new files.
The PR contained 18 intentional issues across six categories. We embedded these issues at varying levels of subtlety: some obvious (like raw SQL queries with string interpolation), some moderate (like incorrect pagination math), and some subtle (like asserting on the wrong variable in a test).
To ensure fair comparison, we used the identical commit for all three pull requests. Same code changes, same PR title (”Add user search, bulk operations, and CSV export”), same description. Each model reviewed the PR with Balanced Review Style. We set the maximum review time to 10 minutes, though none of the models needed more than 5.
Embedded Issues by Category

Results Overview
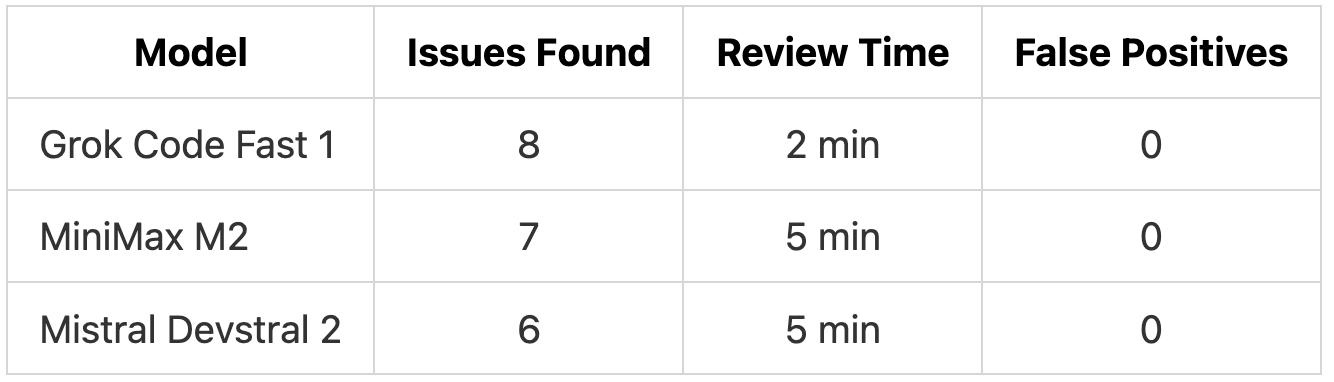
All three models correctly identified the SQL injection vulnerabilities, the missing admin authorization on the export endpoint, and the CSV formula injection risk. They also caught the loop bounds error and flagged the test file as inadequate.
None of the models produced false positives. Every issue they flagged was a real problem in the code. This matters because false positives erode trust in automated reviews and make it harder to identify real issues.
What Each Model Did Well
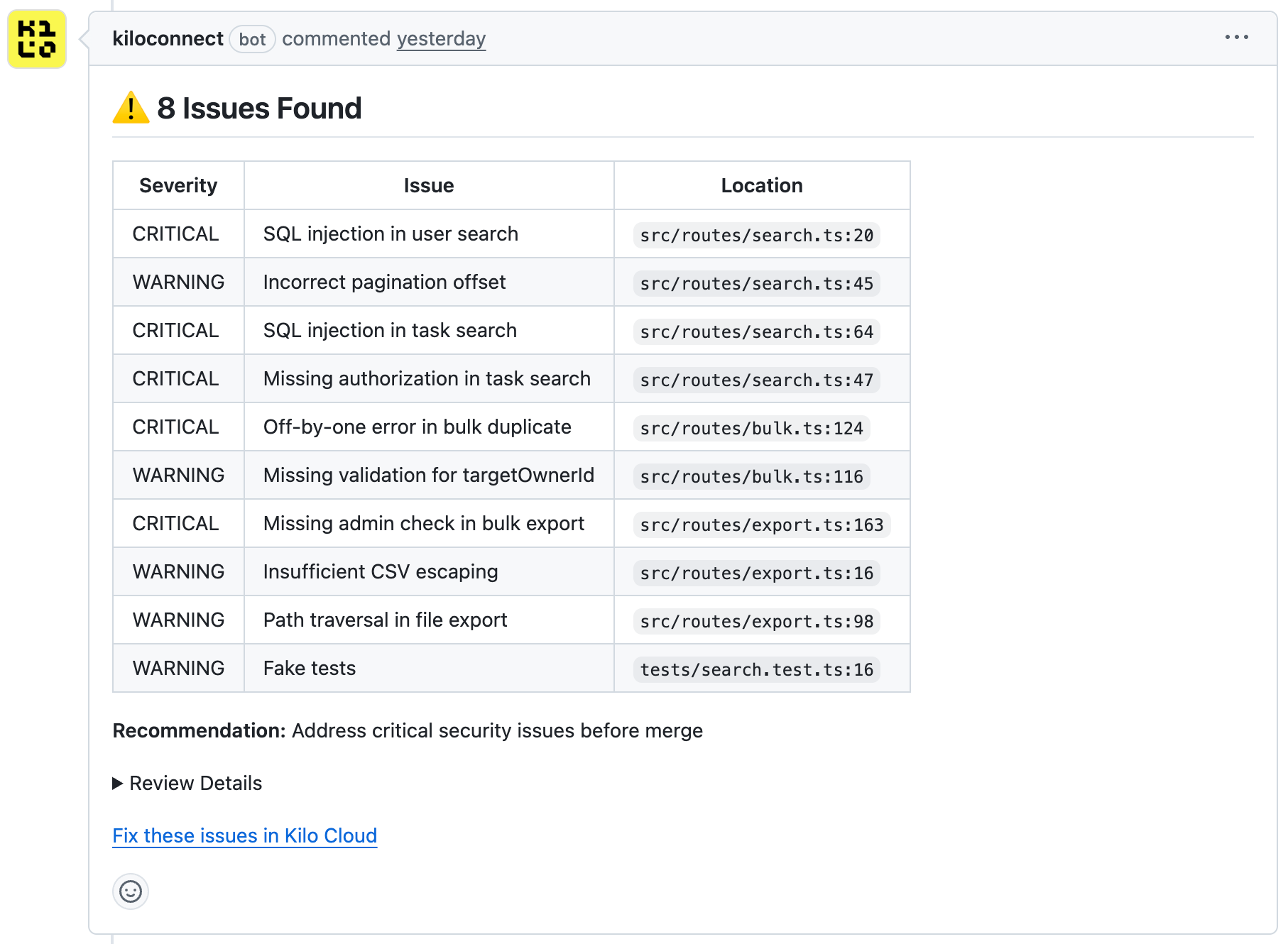
Grok Code Fast 1
Grok Code Fast 1 completed its review in 2 minutes, less than half the time of the other models. It found the most issues (8) while producing zero false positives.
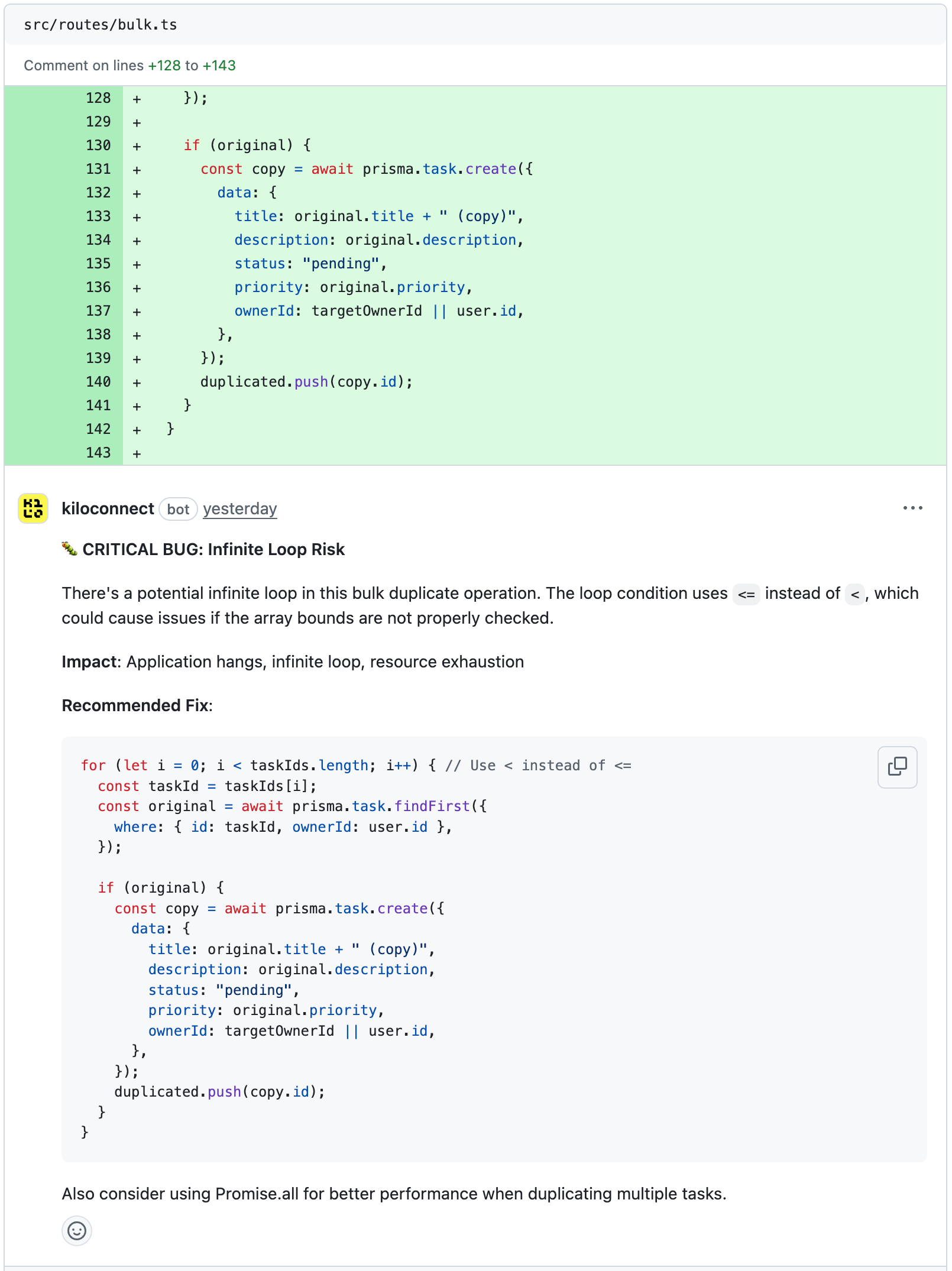
Grok Code Fast 1 was the only model to catch two issues the others missed:
The pagination offset bug. The search endpoint calculated the database offset as page * limit. For page 1 with a limit of 50, this skips the first 50 results and returns results 51-100 instead of 1-50. Grok Code Fast 1 flagged this with the recommendation to use (page - 1) * limit.
The task search authorization gap. The task search query returned all matching tasks in the database regardless of who owned them. Any authenticated user could search and view tasks belonging to other users. Grok Code Fast 1 described this as “violating data isolation principles” and recommended adding an owner filter to the query.
Grok Code Fast 1’s output was structured with clear severity ratings (Critical, Warning) and a summary table at the top listing all findings with their locations. Each finding included a specific recommendation.
MiniMax M2
MiniMax M2 took a different approach from Grok Code Fast 1 and Devstral 2. Instead of posting a summary, it added inline comments directly on the relevant lines in the pull request. Each comment appeared in context, explaining the issue and providing a code snippet showing how to fix it.
MiniMax M2 also identified security concerns we hadn’t explicitly embedded:
The bulk operations endpoints accepted arrays of arbitrary size with no limit, creating potential for denial-of-service attacks where a malicious request could overwhelm the server.
No rate limiting on bulk endpoints, allowing automated abuse.
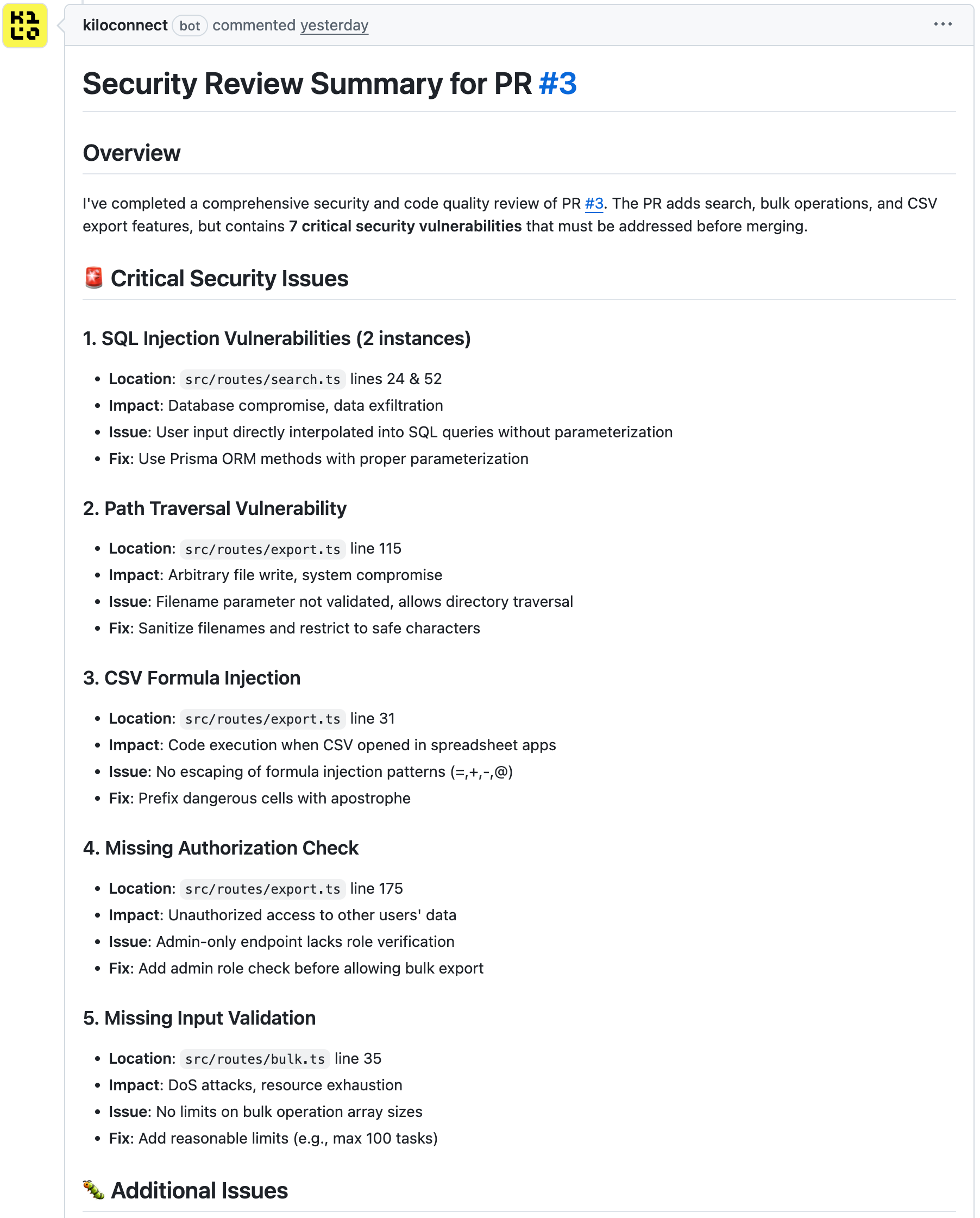
Mistral Devstral 2
Devstral 2 found fewer issues overall but caught something the other models missed: one endpoint didn’t use the same validation approach as the rest of the codebase.
The project used Zod schemas for request validation on all endpoints. One new endpoint parsed the request body manually with await c.req.json() instead of using the zValidator middleware. Devstral 2 flagged this as “breaking consistency with the rest of the codebase” and recommended adding proper Zod validation to match the established pattern.
Devstral 2 also noted missing error handling around filesystem operations. The export endpoint used synchronous file writes without try-catch, meaning a disk full error or permission issue would crash the request handler. Neither Grok Code Fast 1 nor MiniMax M2 flagged this.
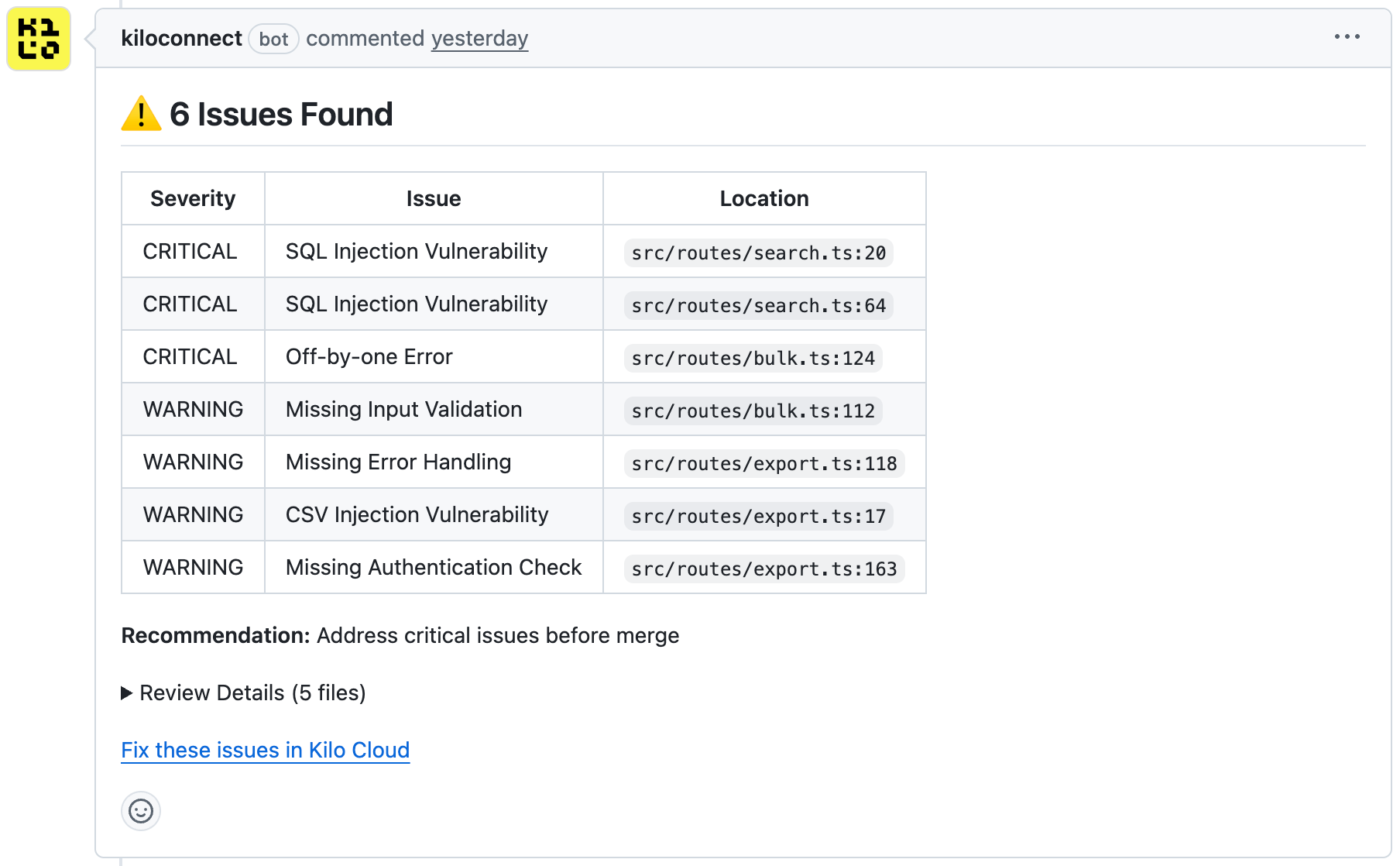
Additional Valid Findings
Each model also identified issues we hadn’t explicitly planted:

Even though we didn’t explicitly plant these issues, they are real problems in the codebase that would’ve slipped through the cracks had we not used Code Reviews on this PR.
What All Three Missed
No model caught everything, and the three shared some consistent blind spots.
Performance issues: None detected the N+1 query pattern, the synchronous file write blocking the event loop, or the unbounded search query.
Concurrency bugs: None caught the race condition in bulk operations where tasks were checked and updated without transaction wrapping.
Subtle logic errors: The date comparison bug (using string ordering instead of comparing Date objects) went undetected. So did the specific test assertion error where tests asserted on the wrong variable.
Code style issues: None flagged the inconsistent naming conventions or magic numbers.
Detection Rates by Category
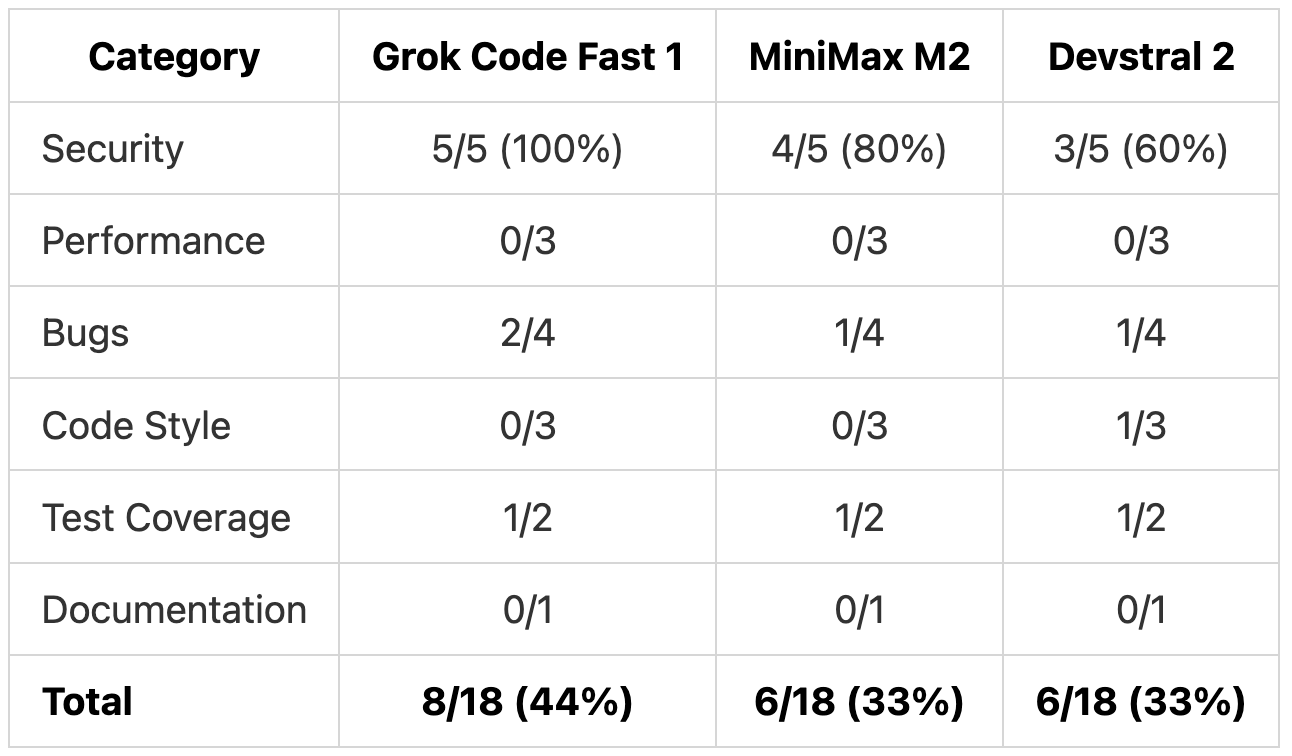
These counts reflect only the 18 planted issues. The additional valid findings shown earlier are not included in these percentages.
Security detection was strong across all models:
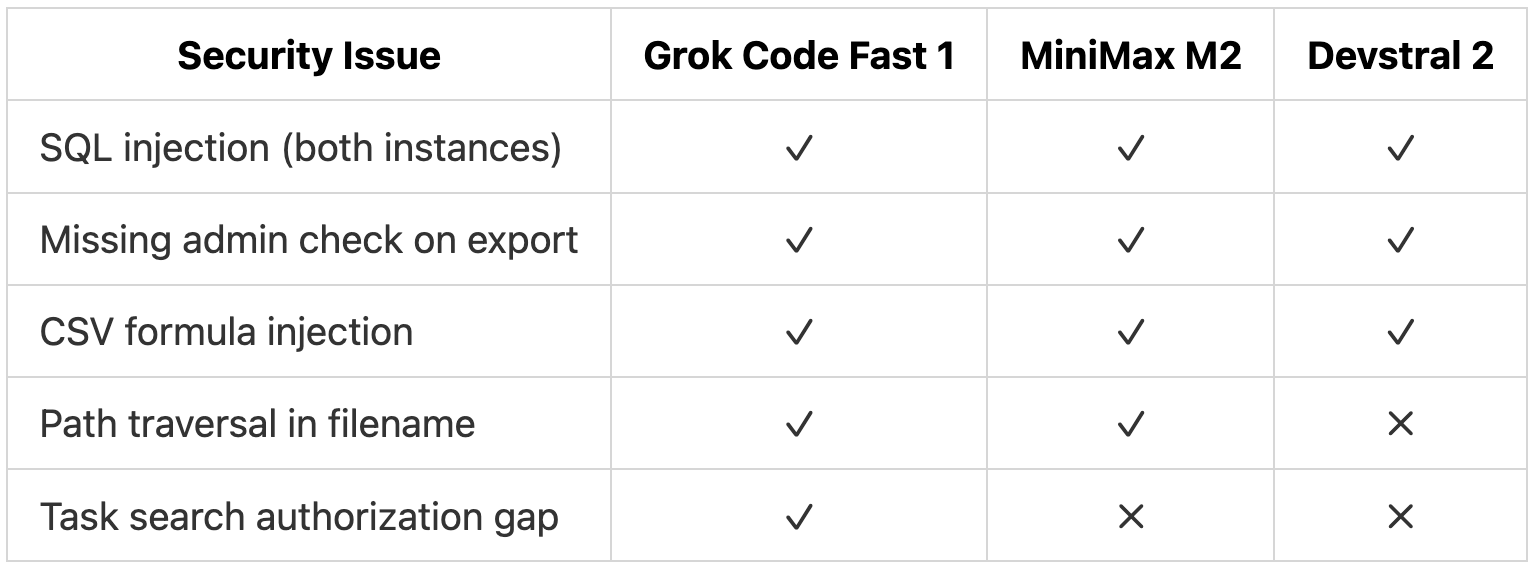
Grok Code Fast 1 caught all five. MiniMax M2 missed the authorization gap where any user could search all tasks. Devstral 2 missed both that and the path traversal vulnerability. The gaps in performance and concurrency detection are expected from smaller models optimized for speed rather than deep reasoning. For security issues, which often carry the highest risk, all three models performed well.
Output Format Comparison
Grok Code Fast 1 and Devstral 2 posted summary comments at the PR level with a table of all findings, followed by detailed explanations grouped by category. This keeps the PR clean with a single comment thread regardless of how many issues are found.
MiniMax M2 posted inline comments directly on the code lines where issues occurred. Each issue appears in context with the problematic code visible. For a PR with 7 issues, this creates 7 separate comment threads.
The summary format works better for architectural reviews where you want to see all findings at once. The inline format works better for quick fixes where developers can address each issue in place without cross-referencing line numbers. Both approaches have merit, and the right choice depends on how your team prefers to work.
When to Use Each Model
Grok Code Fast 1 works well for teams that want fast feedback on every PR. The 2-minute review time means it can run on every push without blocking developers waiting for CI. It found the most issues and had perfect precision (no false positives). Use it when speed and breadth matter.
MiniMax M2 fits teams that want actionable inline feedback. The comments appear directly on the code in GitHub with specific fix suggestions. Developers can address issues without context switching. Use it when you want the review to function like a human reviewer leaving comments.
Devstral 2 is useful for catching consistency issues across a codebase. Its pattern-matching identified where new code deviated from established conventions. Use it when maintaining codebase consistency is a priority.
Moving Beyond Free Tier
The free models caught 6-8 of 18 issues (33-44%), with particularly strong performance on security vulnerabilities. For teams that need deeper coverage, there are options to extend this baseline.
Use a more capable model. Kilo Code supports Claude Opus 4.5, OpenAI GPT-5.2, and other frontier models for code reviews. These larger models catch performance patterns, concurrency bugs, and subtle logic errors that smaller models miss.
Layer fast and deep reviews. Use free models like Grok Code Fast 1 for screening on every PR, then run a deeper review with Claude Opus 4.5 or GPT-5.2 on PRs targeting main or before releases.
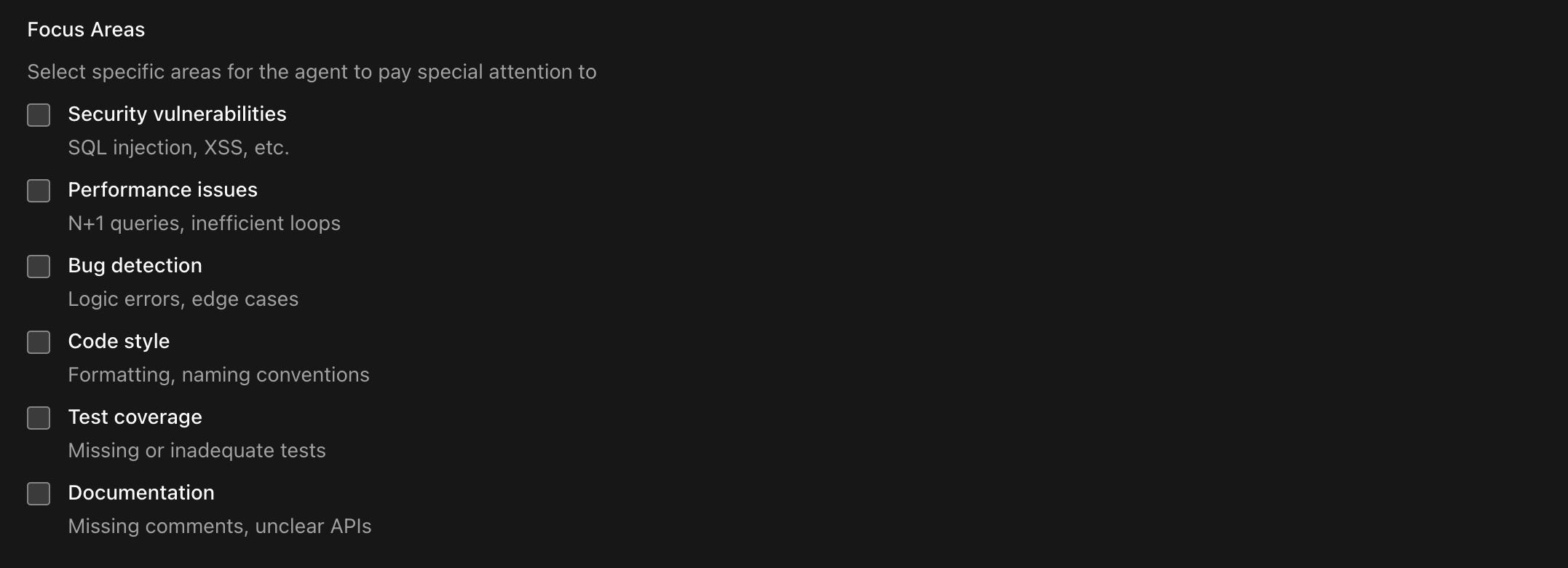
Configure focus areas. If your codebase has known risk areas, configure reviews to focus specifically on those categories. A model looking only for security issues may catch more than one spreading attention across all categories.
Verdict
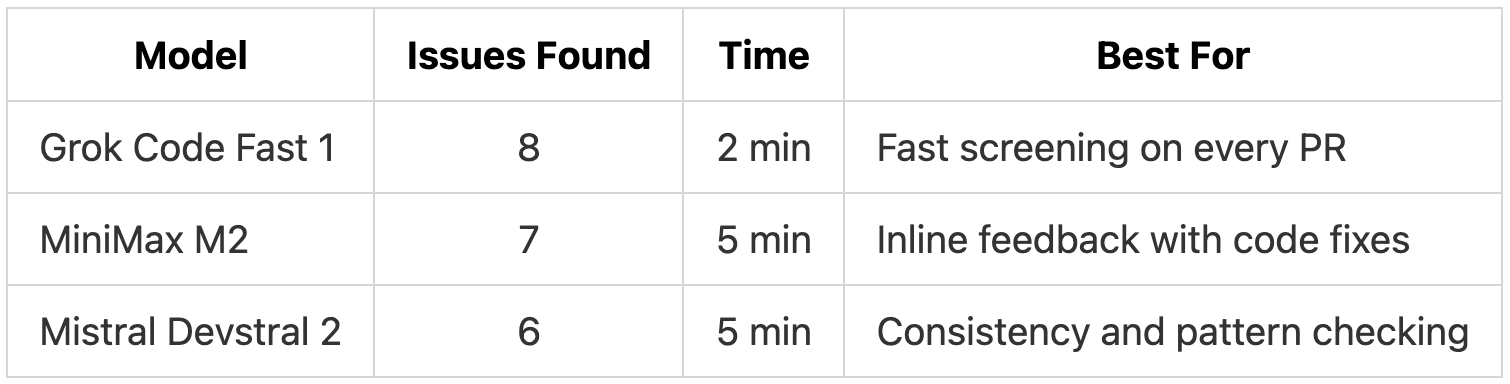
For free models, these results are solid. All three caught critical security issues (SQL injection, missing authorization, CSV injection) and flagged inadequate test coverage. None produced false positives. Grok Code Fast 1 stood out for speed and detection breadth, MiniMax M2 for the quality of its inline suggestions, and Devstral 2 for catching consistency gaps.
The common blind spots (performance patterns, race conditions, subtle logic bugs) are expected at this tier. For deeper analysis, Frontier models like Claude Opus 4.5 and OpenAI GPT-5.2 are also available in Kilo Code.
For catching the issues that matter most before they reach production, the free models deliver real value. They run in 2-5 minutes, cost nothing during the limited launch period, and catch problems that would otherwise slip through.
Testing performed using Kilo Code, a free open-source AI coding assistant for VS Code and JetBrains with 750,000+ installs.
How does one switch between more in depth reviews (heavier models) and faster reviews between PRs? Can I add a label or @kilocode or something in the description?