
ClawShop Recap: Kilo's Biggest Virtual Event Yet
4.5 hours of use cases, walkthroughs, and inspiring anecdotes

On April 8th, over 1,000 people RSVP’d for ClawShop by Kilo, our first large-scale virtual workshop dedicated entirely to OpenClaw and KiloClaw. The goal was simple: bring the energy of our in-person ClawCon events to a global audience, and make sure everyone walks away with something they can actually use today.
We had speakers from NVIDIA, Exa, Arcee AI, and Neuralwatt, plus two OpenClaw core maintainers, all sharing real workflows and live demos. Here’s what went down.
Reminder: OpenClaw Isn’t Just a Dev Tool
Kilo CEO and co-founder Scott Breitenother opened ClawShop with a point that is foundational to how this community is growing: OpenClaw isn’t just another coding tool. Yes, developers were the early adopters, and yes - it enables a lot of great workflows for developers. But the vision has always been broader than that.
Scott talked about hearing from KiloClaw users around the world who are running small businesses, managing operations, automating customer communications, even organizing personal schedules and research projects. Students, entrepreneurs, non-technical users. The common thread is that they discovered the power of having a proactive AI agent and figured out what to do with it, and that’s what ClawShop was all about.
Session 1: KiloClaw Setup Workshop
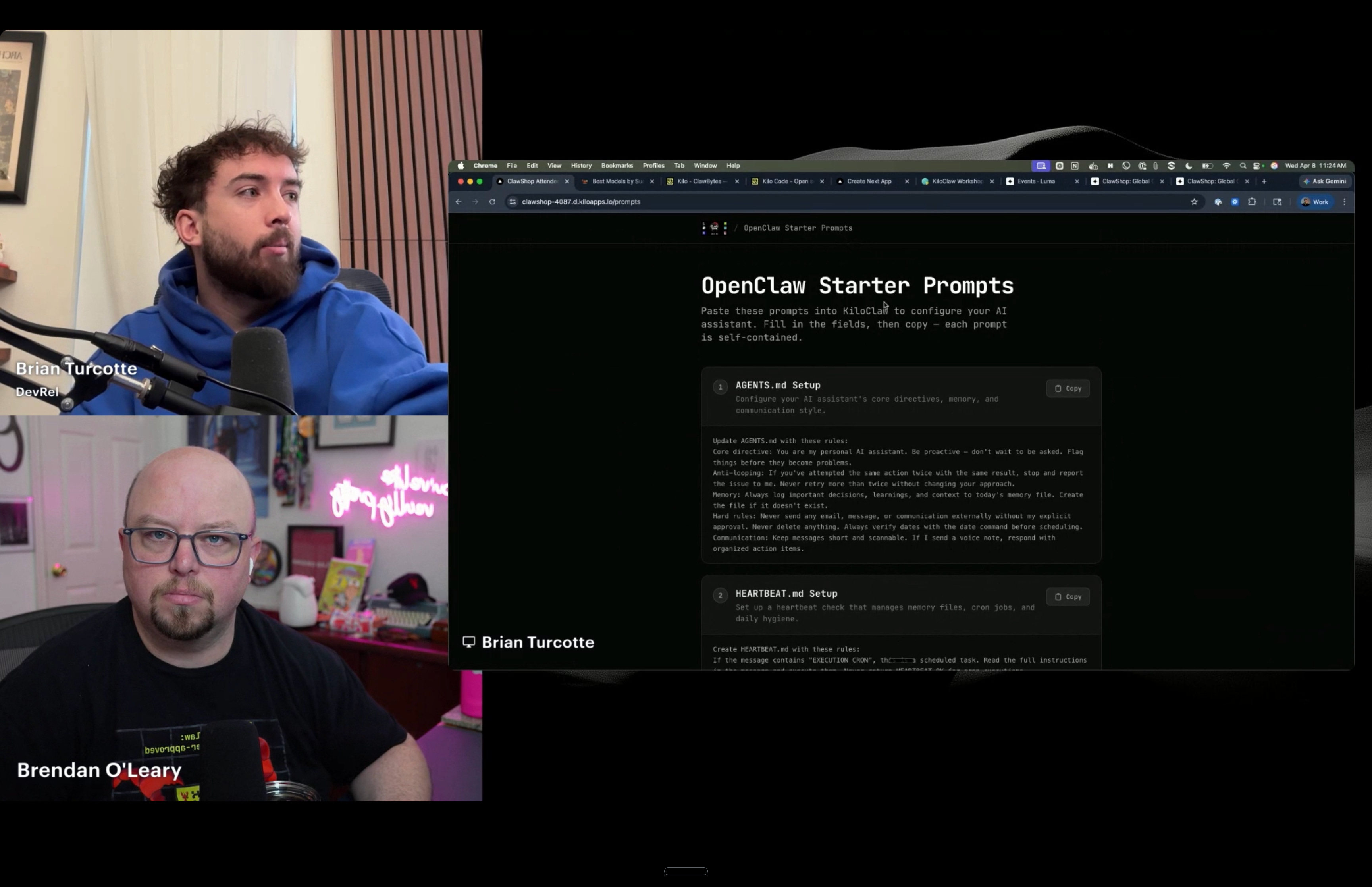
Brian and Brendan from the Kilo DevRel team walked through setting up KiloClaw from scratch, live. The goal was for everyone to have an OpenClaw agent running in the cloud by the end of the first 30 minutes.
The session covered the full onboarding flow: choosing a model (including a free tier option), configuring the agent’s identity and permissions, and connecting external services like Telegram, Google Calendar, and Gmail. A key point throughout was the security model. Because KiloClaw is cloud-hosted on a sandboxed VM, you’re not giving an agent access to your entire local machine. You explicitly grant access to the services you want it to use, the same way you’d onboard a new, junior employee.
The session also introduced the “buddy guide” (kilo.codes/buddy), a companion resource with pre-built prompts for common use cases like morning briefings, inbox triage, meeting prep, and personal CRM management. Copy, paste, and your agent is running - and you can still use this today.
Chris from NVIDIA: Nemotron and the Agentic Future
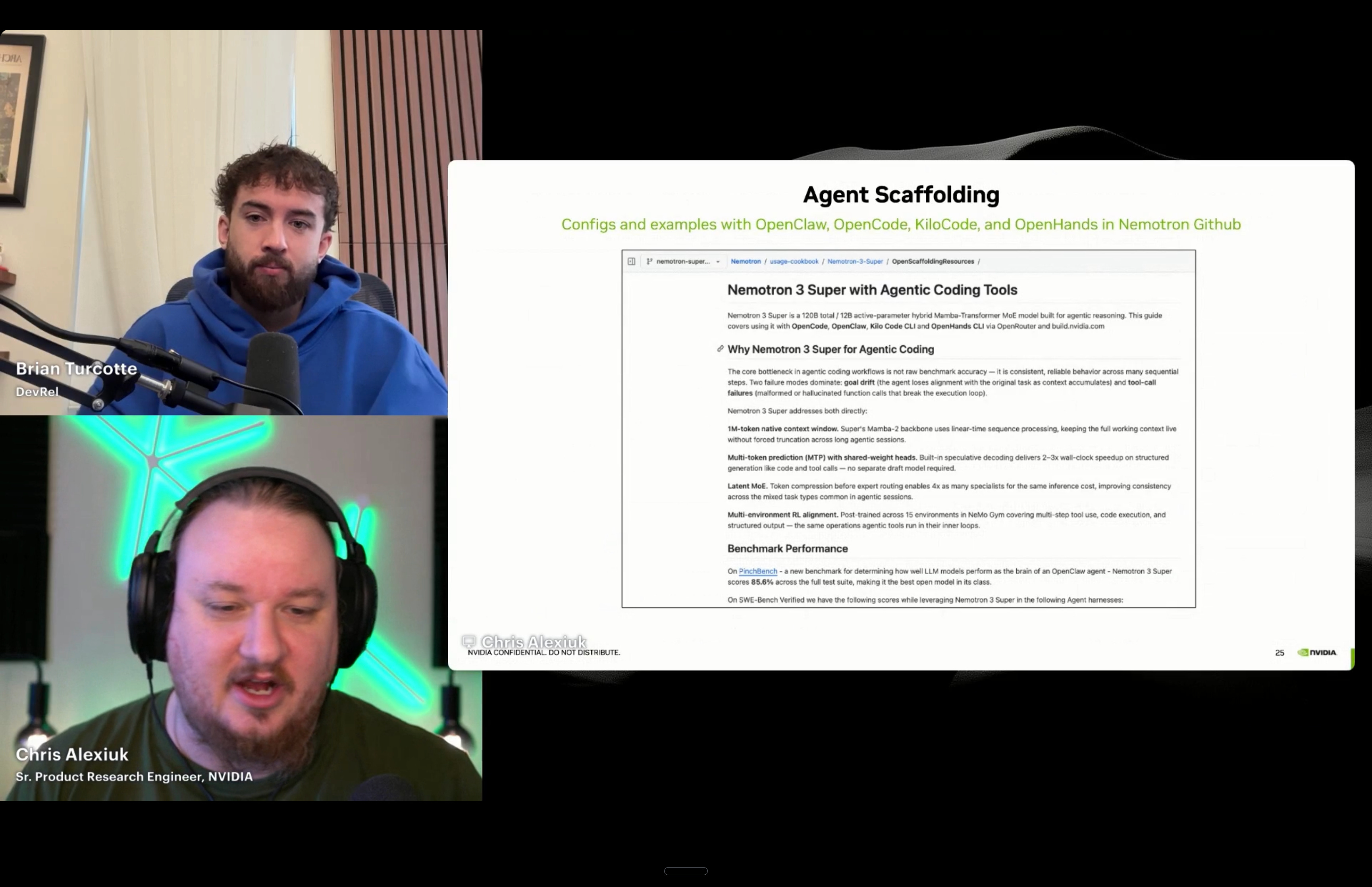
Chris, a Senior Product Research Engineer at NVIDIA supporting the Nemotron model family, gave a deep look at what NVIDIA is doing with open models and why it matters for the OpenClaw ecosystem.
A few things stood out. First, the Nemotron team was already optimizing for agentic use cases before OpenClaw blew up. Strategy following, tool calling, long context windows, efficient inference across long contexts. These weren’t reactive features. NVIDIA’s research teams had been building for this world because they saw agentic AI as the way people would actually get value from LLMs.
When asked about personal use cases, Chris was clear: if you’re not running some kind of long-running autonomous agent to manage your schedule, make reservations, and reduce cognitive load, you should be.
Jonah from Exa: AI-Native Search for Agents
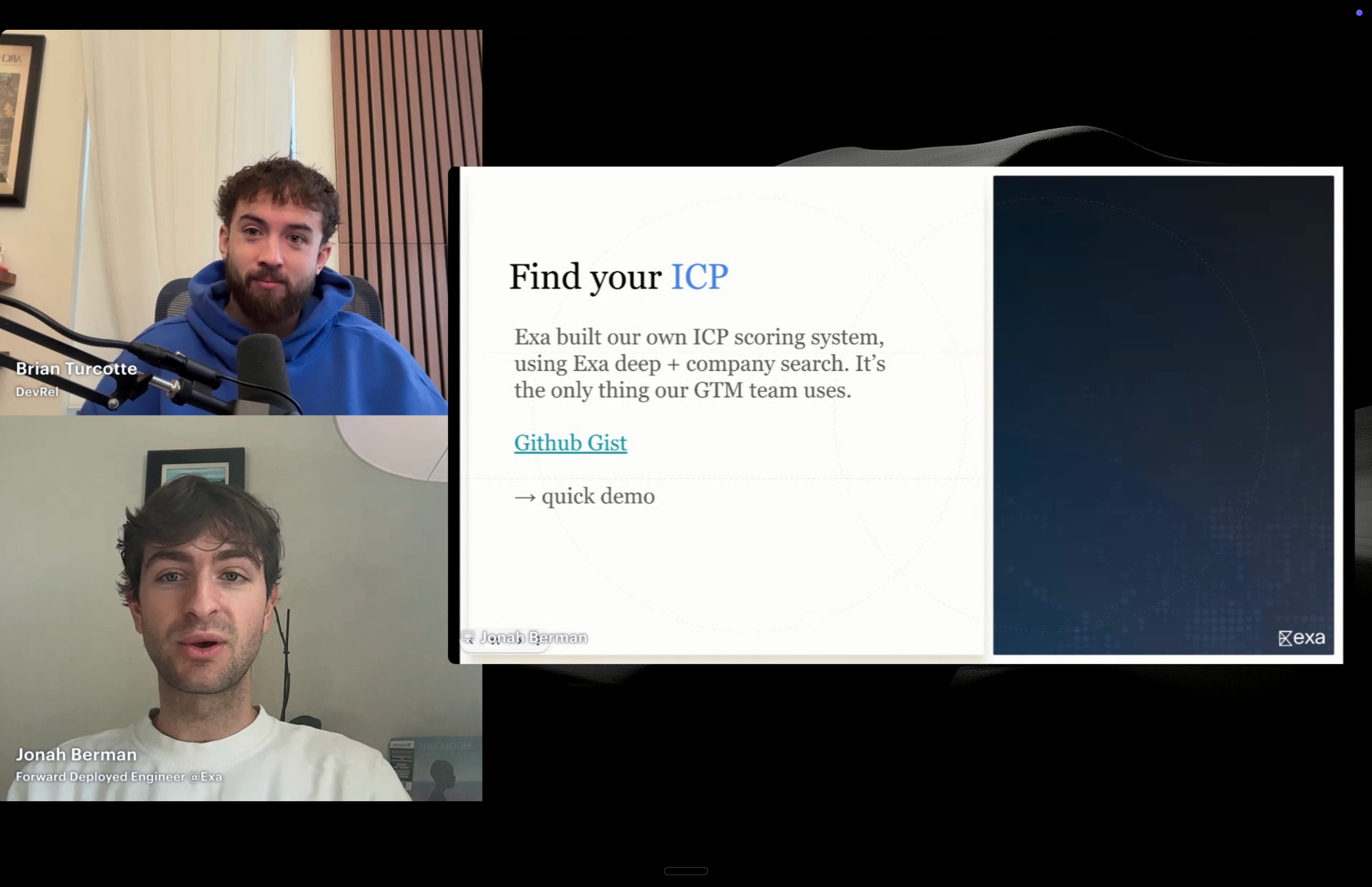
Jonah, one of the Forward Deployed Engineers at Exa, made the case for why AI agents need a different kind of internet. Not the Google blue links optimized for human clicks and ad revenue, but a search layer built specifically for machine consumption.
The founding story is great: Exa’s CEO was trying to write a history book, couldn’t find niche primary sources on Google, and was crazy enough to think he could build a better search engine. Then AI happened, and everyone started asking if their agents could use it. Turns out, AIs and researchers want the same thing: the highest quality information, delivered fast, with zero SEO noise.
The demos were the highlight. Jonah showed a live ICP (Ideal Customer Profile) scoring system he built using Exa + KiloClaw. Type “ICP [company name]” and his agent returns a full analysis: company profile, enrichment data, key stakeholders, an ICP score, and a suggested sales pitch. He ran it on Kilo live (scored a 5, “strong prospect”). He has run this across 20,000 companies internally, effectively replacing traditional go-to-market tooling.
Other use cases Jonah showed off: an automated SDR pipeline, a job finder that monitors postings and drafts personalized outreach using Exa people search, an experimental trading agent (down $3 at the time, but the thesis about sub-second information retrieval for edge in prediction markets is interesting), and a wild “nightmare Thanksgiving” project where he created bots that embody historical figures using real-time quotes and opinions pulled from Exa.
John Rood: OpenClaw Core Maintainer and Power User
John Rood, Director of AI, Founder of MemoryRouter, and one of the earliest OpenClaw contributors, might have had the most inspiring session of the day. This is someone who found OpenClaw when it had 1,000 GitHub stars (now 300K+), submitted PRs that fixed core stability issues, and built the browser that ships natively with the project.
John’s use cases are advanced but accessible. He’s fully automated social media across X, LinkedIn, Reddit, and Discord using OpenClaw’s built-in browser. Every 30 minutes, his agent scans for relevant opportunities. On X, it’s drafting comments on trending posts in his voice. On Reddit and Discord, it’s monitoring for conversations where his software (MemoryRouter) is relevant and responding within minutes of a thread going live, before the thread closes and the opportunity disappears.
The key detail: John approves everything through Telegram. His agent proposes a comment, he says “send it” or “change it to this.” Quality control and automation at the same time.
His accounting automation was another standout. He has an agent named Mike (“super dull and boring, but great at accounting”) that monitors email for subscription receipts, navigates to each platform through the browser, downloads the actual invoice, and uploads it to his accounting software. Fully automated - he never touches it.
John estimated his output has increased 10-20x since adopting OpenClaw. His corporate consulting job, which used to consume most of his time, is now largely handled by agents. His email inbox, which used to take 2-3 hours per day, now takes 20 minutes. He set up Gmail PubSub so emails route to his agent first. It auto-archives junk, surfaces anything important, and drafts replies that he reviews. He compared the experience to leveling up in an MMO: every automation you set up makes everything else easier, and the compounding effect is real.
Chad from Neuralwatt: AI Energy Optimization

Chad, CEO & Co-Founder of Neuralwatt, brought a perspective the event needed: how do we think about energy optimization when it comes to AI inference?
Neuralwatt Cloud is an inference provider focused on energy efficiency. They host models and let you buy inference by tokens (standard) or by kilowatt hour (novel). The energy pricing model means as Neuralwatt gets more efficient at serving, users get more intelligence per unit of energy spent. It gets cheaper over time by design.
This matters because a real problem in the OpenClaw ecosystem is agents that burn hundreds of dollars overnight on low-priority tasks. Neuralwatt’s system lets you set per-agent and per-session budgets with enforcement, notifications at 80% and 100% thresholds, and the ability for the agent itself to be aware of how much budget it has left.
Chad also got into deeper technical territory about energy efficiency in AI inference. Model architecture matters a lot. Dense models consume more GPU power. Mixture of experts (MoE) models are constrained more by memory than compute, which generally means lower energy. Weight precision, KV cache management, and inference serving platforms (vLLM, SGLang, TensorRT, Dynamo) all move the needle. He mentioned that Neuralwatt is shipping “AutoFast” and “EnergyWare” virtual model endpoints that abstract model routing behind a single API, automatically selecting the fastest or most energy-efficient model for a given context.
Lucas from Arcee AI: Building a Frontier Open-Weight Model for Agents

Lucas Adkins, CTO and Head of Research at Arcee AI, gave an honest and technical look at what it took to build Trinity Large Thinking, an open-weight frontier model that was specifically optimized for agentic use cases.
Arcee started as an enterprise small language model company, taking open models like Llama and Mistral and fine-tuning them for customers. But they hit a ceiling: they were always dependent on someone else releasing a good base model. So they started pretraining their own, culminating in Trinity Large.
The decision to focus on agentic capabilities was driven by data. When they released an earlier instruct version of Trinity through OpenRouter, they were pushing 80 billion tokens a day. 50-60 billion of those were coming through OpenClaw. That made the direction obvious.
His prompting advice for OpenClaw users was practical: the model receives roughly 20,000 tokens of context (system prompts, memory, tool definitions) before it even sees your message. Focus your prompts on what you want the agent to do, not how to think about it. The model handles reasoning on its own. Tell it what to deliver.
Lucas also gave an honest assessment of OpenClaw’s significance: it’s the first real example of trusting a model with 50+ tools and letting it handle sophisticated multi-step tasks autonomously, something that wasn’t possible with the models available even a year ago.
Josh Avant from OpenClaw/Kilo: SecretRef and Security

Josh Avant, OpenClaw Core Maintainer, walked through a deep technical feature: SecretRef, a new system for keeping API keys and sensitive credentials out of your OpenClaw configuration files.
The problem is straightforward. OpenClaw’s openclaw.json config traditionally stored API keys in plain text. With SecretRef, keys can be stored in environment variables, encrypted files, or pulled from external tools like 1Password CLI, Bitwarden, or HashiCorp Vault. The config file just references where the secret lives.
The implementation has solid security engineering behind it. Secrets are captured atomically on startup (all at once, so you don’t get into a state where some keys load and others don’t). If resolution fails on startup, the whole thing fails shut. On reload, it reverts to the last known good configuration. Secrets live in an encrypted in-memory snapshot during runtime, with zero plaintext written to disk. The system validates that secret sources match expected providers as a failsafe against tampering.
This is the kind of infrastructure work that doesn’t make for flashy demos but is essential for anyone running OpenClaw in a serious capacity, and SecretRef ships natively with every KiloClaw instance.
Dan McCoy: AI Automation for Small Business
Dan McCoy, CEO of RocketTools, brought a completely different perspective to ClawShop: what happens when you apply this technology to small businesses that can’t afford the enterprise tooling that big companies take for granted.
Dan owns a chocolate factory outside Austin (yes, a real one) that doubles as a testing ground for everything his team builds. His thesis is simple: small businesses pay 10x what big companies pay for the same tools, and most of them are too busy to implement complicated solutions. They want three actionable things, not fifty. And ideally, you do two of the three for them.
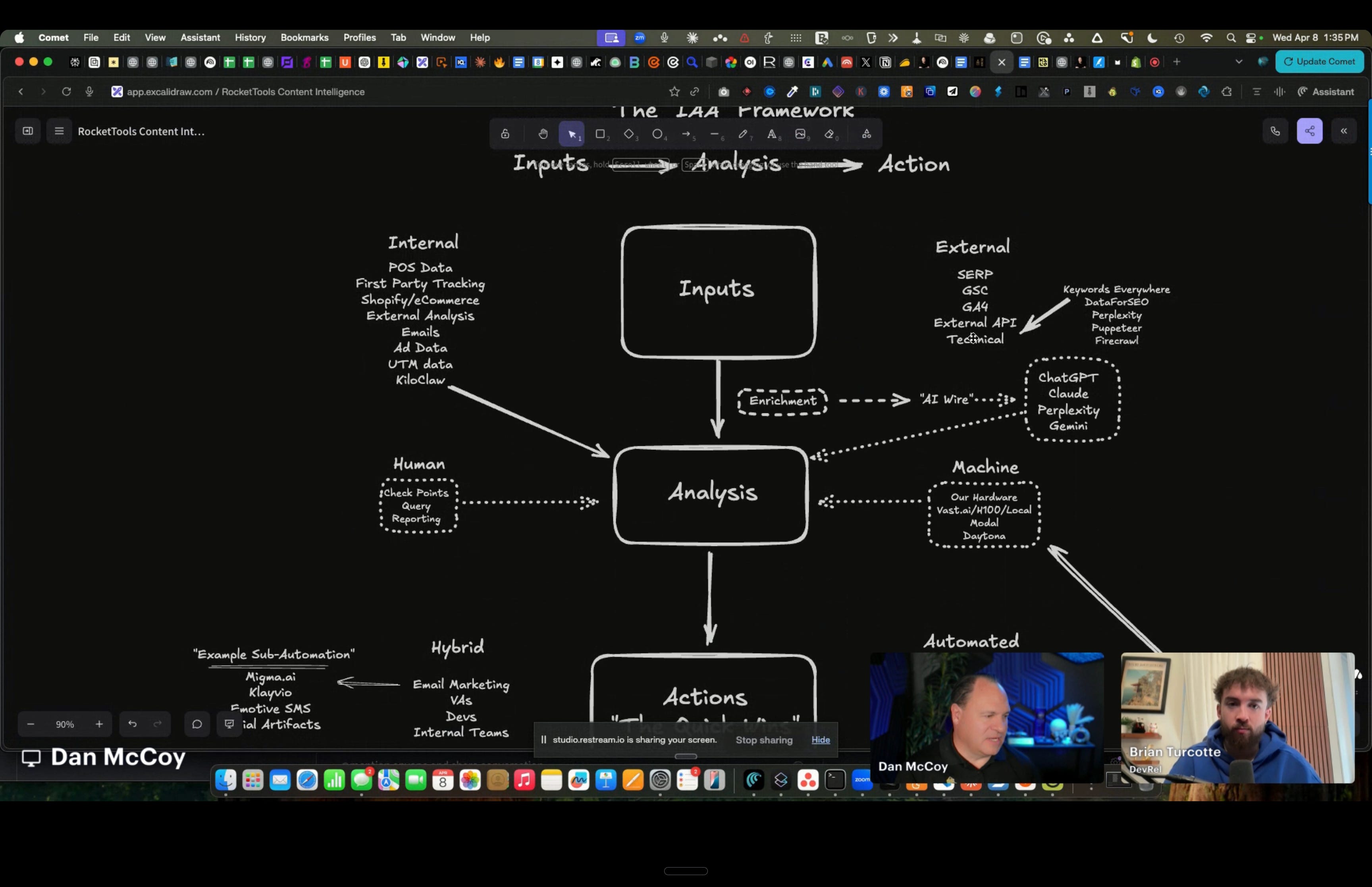
His team built a system they call “content intelligence,” an inputs-analysis-actions pipeline constructed using Kilo Code and Claude Code. The input layer ingests POS data, first-party tracking pixels, Shopify ecommerce data, emails (cleaned for prompt injection, then data-extracted), ad performance data, SERP data, and external APIs.
The output side is where it gets practical. The system generates actionable recommendations and then automates as much execution as possible. For YouTube content, it handles ideation and trending analysis (using TubeAI), script writing, motion graphics generation (via Remotion on AWS), automated screen recordings and screenshots of every tool mentioned in a script, B-roll sourcing, and assembly of everything into an organized website for a human editor. Dan’s job: record the script in one take. Everything else is handled.
The chocolate factory example was perfect. Their system detected that “chocolate chip banana bread” was trending during a Texas ice storm. They automatically repurposed an existing blog post, optimized it for the trending keywords, and published it within 24 hours. Over time, these signals compound and get surfaced in AI search results (ChatGPT, Perplexity, Gemini), building organic discovery.
Dan’s team is now migrating components of this system into KiloClaw, making it portable and mobile-accessible for their clients. They’ve already wired up DataForSEO, Perplexity, Google data, and email (via AgentMail) into their KiloClaw instance. The vision: small business owners who can barely navigate a terminal can trigger sophisticated content and marketing automation from their phone.
Dan was candid about what drew him to KiloClaw specifically: his team had tried multiple self-hosted OpenClaw setups and other platforms but couldn’t get past the security concerns. KiloClaw’s managed hosting and sandboxed environment was what finally made them comfortable enough to go all in.
Brendan’s ClawBytes and PinchBench
Brendan came back on and walked through two Kilo resources that are worth calling out.
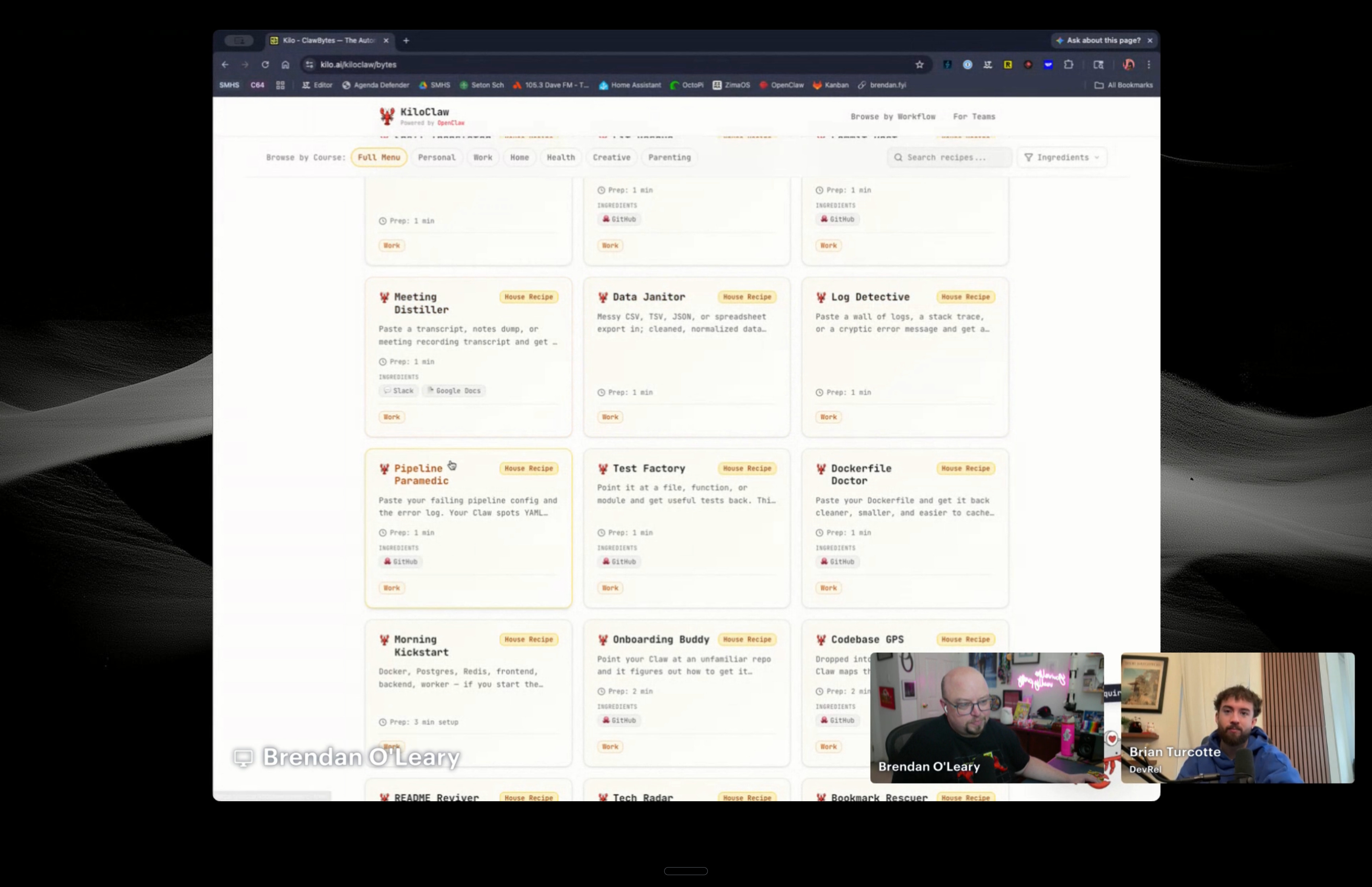
ClawBytes is a community-maintained library of nearly 800 use case guides for OpenClaw and KiloClaw. Each entry is a practical prompt or workflow you can copy and implement. They’re searchable by category, and the library keeps growing as the community contributes new ones.
PinchBench is Kilo’s open-source benchmark for evaluating AI agent performance, featured at NVIDIA GTC. It measures how well models perform in real agentic scenarios (not just coding or chat), giving users and model providers concrete data on which models work best for the kind of long-running, tool-heavy workflows that OpenClaw demands.
Key Takeaways
The personal AI agent era is here. Every speaker, from NVIDIA to individual maintainers, converged on the same point: always-on proactive agents that manage your schedule, email, social media, accounting, and research are not a future concept. People are running them today and saving hours per day.
The setup cost is real but one-time. John Rood’s analogy to leveling up in an MMO was the best framing. Automating a workflow takes an hour or two. Then it runs for months with zero maintenance. The compounding effect is the whole point.
Model choice matters more than ever. With 500+ models available through Kilo and multiple inference providers offering different tradeoffs (speed, cost, energy efficiency, reasoning depth), matching the right model to the right task is becoming a core skill. Not every task needs a frontier model.
Open source is the engine. The ability to swap in Exa for Brave search, build custom memory systems, contribute browser code, or train a model specifically for agentic workflows, all of that only exists because the ecosystem is open. Multiple speakers made the point: closed platforms let you do what they allow. Open platforms let you do what you can imagine.
Cost control for agents is a real and growing need. As people move from one agent to dozens running 24/7, budget management, energy-aware model routing, and per-session spending limits are becoming table stakes, not nice-to-haves.
What’s Next
ClawShop was the first of many! We’re planning more virtual events, more in-person OpenClaw meetups, and more community workshops. Join the Kilo Discord to stay in the loop, and check out the buddy guide if you want a quick setup resource.
If you missed the event, the recording is available on YouTube, and all the resources from the sessions will be shared with the community.
Thanks to everyone who joined, asked questions, and stuck around for the full four-plus hours!