
Claude Sonnet 5 Is Available in Kilo Code
Anthropic’s most agentic Sonnet closes the gap with Opus — and the pricing makes it interesting

Anthropic launched Claude Sonnet 5 today. It’s their most agentic mid-tier model, and it’s available in Kilo Code right now through both OpenRouter and direct API.
Sonnet 5 gets close to Opus 4.8 performance on agentic coding tasks, at roughly a third of the price. For teams running AI-assisted coding at scale, that changes which model you default to.

What Changed
The headline numbers:
63.2% on SWE-bench Pro (up from 57.6% on Sonnet 4.6). Opus 4.8 still leads at 69.2%.
1618 on GDPval-AA v2 for knowledge work — slightly above Opus 4.8’s 1615.
1M token context window natively. No beta headers, no special configuration.
128k output ceiling — useful for large refactors and multi-file changes.
The knowledge-work score stands out because Sonnet 5 edges past Opus 4.8 on a benchmark that looks a lot like sustained agent work: reading context, planning changes, executing them, verifying results.
Early testers cited by Anthropic described it finishing tasks where previous Sonnet models stalled mid-way. One tester reported it investigating a bug, writing a reproducing test, implementing the fix, then stashing it to confirm the bug came back — all unprompted, in a single pass. That kind of autonomous follow-through used to require Opus-class models.
The more interesting behavior shows up when you actually watch it work. In his day-one review, Theo (t3dotgg) pointed out that Sonnet 5 does something no other model available at launch does: it spontaneously spins up and orchestrates sub-agents. Given a simple prompt to rebuild a game from scratch, it launched agents to investigate the old codebase, others to write a plan, more to analyze that plan, then more to implement it — all unprompted. Opus 4.8, given the identical prompt, spun up zero sub-agents. Sonnet 5 also asked scoping questions up front where Opus asked none. Theo’s read: these are the behaviors that made Anthropic’s top-tier models exciting, and they’re the real reason this is a “5” and not a “Sonnet 4.8.”
Pricing and Tokenizer Costs
Introductory pricing through August 31: $2 input / $10 output per million tokens. After that, it jumps to $3/$15.
For comparison:
Opus 4.8: ~$15/$75
GPT-5.5: $5/$30
Gemini 3.1 Pro: $2/$12
At face value, Sonnet 5 is a bargain. One caveat: it uses an updated tokenizer that produces 1.0–1.35x more tokens than Sonnet 4.6 for the same input text. Your effective cost increase over Sonnet 4.6 is slightly higher than the per-token price alone suggests.
Even accounting for tokenizer inflation, the per-token price is undeniably attractive. But per-token price does not determine total task cost.
Theo’s testing surfaced a genuinely counterintuitive result: Sonnet 5 can end up more expensive per task than Opus 4.8. In his benchmarks it burned close to 2x the tokens of Opus and up to ~5x the tokens of GPT-5.5 on comparable work. On one run of his internal “skatebench,” Sonnet 5 Max averaged 15 cents per question — with some questions costing as much as a dollar — making it the single most expensive model he’d ever run through that benchmark, pricier than dedicated pro-tier models. Artificial Analysis reportedly clocked it as the most expensive model to run their full suite at ~$6,000, edging out even Fable 5.
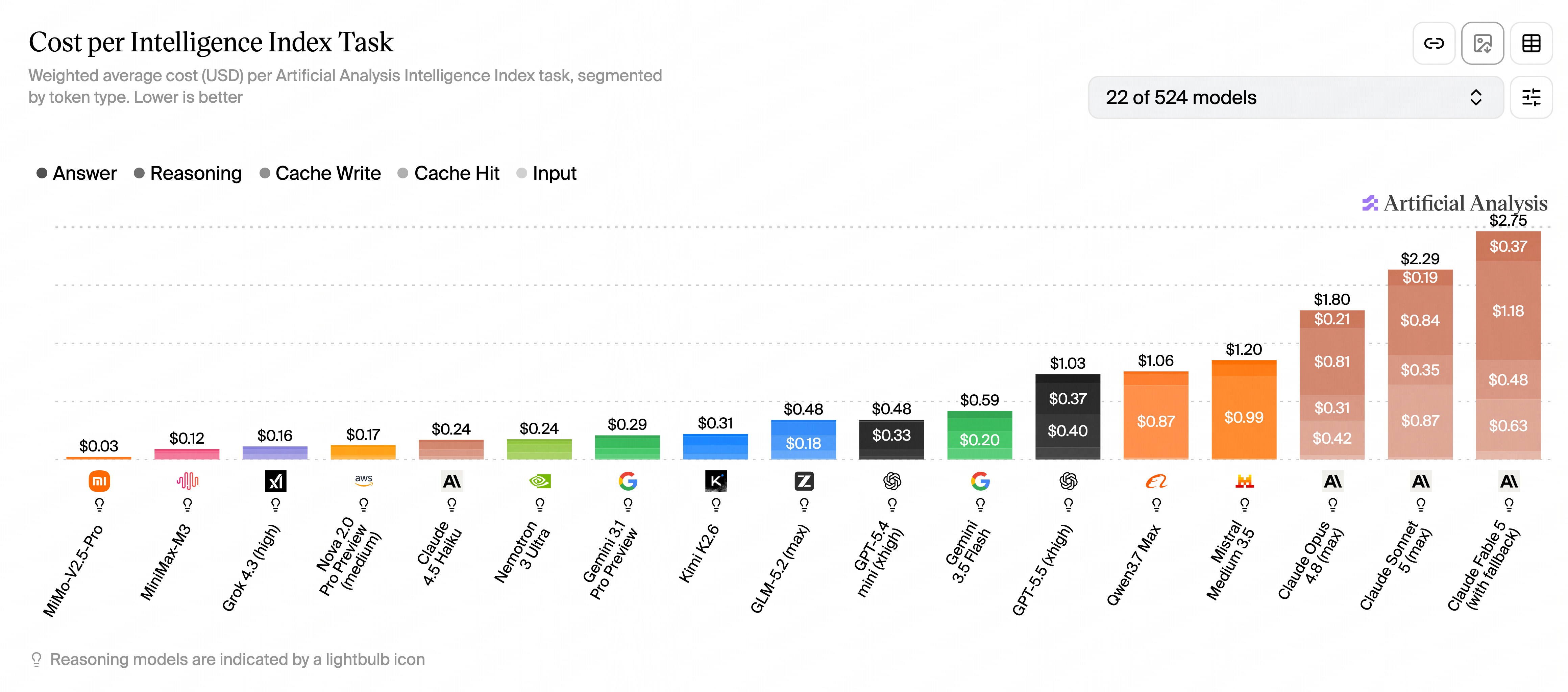
The reason is mostly in how Sonnet 5 is tuned. It keeps going until it reaches an answer — but it isn’t always smart enough to get there efficiently, so on harder tasks it “runs in circles,” spawning sub-agents and re-reasoning rather than tapping out. Theo’s analogy: a $20/hour junior engineer is cheaper than a $100/hour senior only if the task is within their reach. Hand them something too hard with no supervision and the cheap hourly rate turns into a bigger bill.
For tasks squarely within its capability, Sonnet 5 at $2/$10 is a genuine value. For tasks at the edge of its capability, the cheap token price can invert into a higher total cost than just calling Opus in the first place. For well-scoped tasks, it can be a bargain; for harder open-ended work, total cost can rise quickly.
Effort Levels Got Recalibrated
For Kilo users, the effort-level changes are especially relevant. Anthropic recalibrated effort levels:
Medium now ≈ Sonnet 4.6’s high
High now ≈ Sonnet 4.6’s max
New “xhigh” above everything previous
Adaptive thinking is on by default — no manual thinking budget required. The model decides how much reasoning a task needs.
If you were running Sonnet 4.6 at high effort in Kilo, you’ll want to experiment with medium on Sonnet 5. You might get equivalent results at lower cost. Conversely, the new xhigh effort level gives you a path to Opus-tier performance without switching models.
Using Sonnet 5 with an Advisor Model
Anthropic introduced an advisor strategy in beta: Sonnet 5 acts as the executor while a model like Opus 4.8 provides plan and course correction. You get Opus-level planning at Sonnet execution costs.
This is similar to how Kilo’s Auto Model routing already works — using the right model for the right part of the task. The advisor pattern is essentially what smart model routing does at the API level.
This is also the frame Theo lands on after a full day of testing: Sonnet 5 may be more useful as a model called by smarter planners than as a cheaper Opus replacement for day-to-day coding. Its standout trait is that it understands sub-agents and orchestration far better than any previous mid-tier model. The ideal setup is a smarter planner (Opus, or a future Fable/Mythos-class model) breaking work into pieces and handing isolated, well-scoped tasks to Sonnet 5, which can then either execute directly or fan out further sub-agents when it makes sense.
One current limitation is Sonnet 5 knowing when to tap out and escalate a genuinely hard sub-task back up to a smarter model. Good routing can save real money, while poor routing can make Sonnet’s tendency to grind cost more than using the senior model for everything. This is exactly the kind of tradeoff a routing layer is meant to manage for you.
Why Model Flexibility Matters Right Now
Every major lab is shipping agentic models at different price points with different strengths. In the last month alone: Google launched Gemini 3.5 Flash (cheap, agentic-focused), OpenAI shipped GPT-5.6 Sol in limited preview, and now Sonnet 5.
The Fable 5 shutdown also shows why flexibility matters. On June 12, the U.S. Department of Commerce ordered Anthropic to suspend Claude Fable 5 and Mythos 5 globally after Amazon researchers reported a jailbreak technique that bypassed a cybersecurity safeguard. Because Anthropic had no reliable way to verify user nationality in real time, both models went dark for everyone — including enterprises running them in production workflows. Nineteen days later, on June 30, the Commerce Department lifted the controls and Fable 5 rolled back out globally on July 1.
The lifted controls are notably broad. As Theo highlighted, the withdrawal explicitly covers “export, reexport, or in-country transfer” — which matters because it means services that host these models over an API and let users hit them directly are back in the clear, not just first-party use. Anthropic secured the rollback by agreeing to proactively detect and address security risks and to coordinate release protocols with the U.S. government going forward, and Commerce reserved the right to reevaluate.
If your team had hard dependencies on Fable 5 during those 19 days, that outage made the risk of single-model dependency concrete. Single-model dependency is single-point-of-failure dependency. The enterprises that kept working were the ones that could switch to Sonnet 5, GPT-5.5, or Gemini 3.5 Flash without rewriting their tooling.
TechCrunch put it well: “Sonnet 5’s pitch is confirmation that agentic capability is the new baseline expectation at every price tier. Now the differentiator isn’t going to be who can do agentic work best, but how cheaply they can do it.”
The Fable 5 episode also makes resilience a competitive factor. When a model can disappear for 19 days with no warning, the ability to switch becomes an operational requirement rather than an optional convenience.
The market has shifted quickly. In roughly six months, the central question has moved from whether agentic coding is ready to which model can do it cheapest.
This is exactly the environment where being locked into a single provider hurts. If you’re on a tool that only supports Anthropic, you can’t compare Sonnet 5 against Gemini 3.5 Flash on your actual codebase. If you’re locked to OpenAI, you’re paying $5/$30 for GPT-5.5 when Sonnet 5 might handle your tasks for $2/$10.
Kilo Code supports 500+ models via OpenRouter and direct API connections. No lock-in means you can try Sonnet 5 today, compare it against whatever you were running yesterday, and switch back if it doesn’t work for your codebase. That flexibility has always been a core design decision, and recent model launches and outages make it more valuable.
How to Use Sonnet 5 in Kilo
If you’re using OpenRouter, Sonnet 5 is already available as anthropic/claude-sonnet-5. Select it from the model picker or set it as your default.
For direct Anthropic API users, the model ID is claude-sonnet-5.
A few practical suggestions:
Start at medium effort. It’s calibrated higher than Sonnet 4.6’s medium — you might not need high for most tasks.
Use it for sustained multi-file work. The 1M context window and improved follow-through make it well-suited for large refactors.
Compare it against your current default. If you’ve been on Opus 4.8 for everything, try Sonnet 5 on your routine tasks. Save Opus for the genuinely hard problems.
Watch your token counts. The new tokenizer means the same code produces more tokens. Keep an eye on usage if you’re budget-conscious.
Bottom Line
Agentic capability is now expected at every price tier, and Sonnet 5 reflects that shift. The more important development is the arrival of a mid-tier model that genuinely understands orchestration and sub-agents.
The caveat is that the per-token price is a bargain, but per-task cost depends entirely on whether the work sits within Sonnet 5’s capability. For well-scoped, in-reach tasks it’s an excellent value. For open-ended or genuinely hard problems, its tendency to grind until it lands an answer can make it slower — and occasionally pricier — than just reaching for Opus. Skeptics like Theo are sticking with GPT-5.5 and Opus for their own day-to-day work while remaining genuinely excited about what Sonnet 5 unlocks as an executor inside orchestrated workflows.
In practice, try Sonnet 5, but match it to the task rather than defaulting to it blindly. Compare it against whatever you run today on your actual codebase, use it for sustained multi-file work that fits its strengths, and let a routing layer or a smarter planner decide when a task warrants Opus instead.
Sonnet 5 is available now in Kilo Code as anthropic/claude-sonnet-5 in the model selector, or you can install Kilo Code if you haven’t yet.